scikit-learn官网:http://scikit-learn.org/stable/
通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测。
学习问题一般可以分为:
- 监督学习(supervised learning)
- 分类(classification)
- 回归(regression)
- 非监督学习(unsupervised learning)
- 聚类(clustering)
监督学习和非监督学习的区别就是,监督学习中,样本数据会包含要预测的标签(label),例如给定一组猫和狗的图片并对不同的照片给定对应的标签(猫或狗),而非监督学习只会给定一组图片,并不会给出标签。
分类和回归的区别是,分类的样本数据中的标签有大于等于2种,对于预测数据只需要判断属于其中哪个类即可,而回归则是期望输出由一个或多个连续的变量组成,例如根据鱼的年龄和重量推断鱼的长度。
对于一个已知问题,如何判断需要使用那种方法,scikit-learn给出了一个图,可以根据这个图来确定,链接:
http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html

接下来的内容包括:
- 样本数据的获取和生成
- 分类器训练和预测
- 持久化分类器
- 简单交叉验证
- 例子
① 样本数据获取和生成
scikit-learn中包含了很多供初学者学习的样本数据,这些数据包含在sklearn.datasets包中,比较典型的数据是iris,这个数据集给出了iris花的花瓣和萼片的长度和宽度及对应花的种类:

读取这个数据集的方法很简单:
1 from sklearn import datasets 2 3 # 读取iris数据集 4 iris = datasets.load_iris() 5 # 获取数据集中的属性值(花瓣和萼片长度宽度) 6 iris_X = iris.data 7 # 获取数据集中的标签,分别是哪种花 8 iris_y = iris.target 9 10 print(iris_X[::50]) 11 print(iris_y[::50])
因为数据集是有序的并且长度为150(每种花50个),所以打印的时候步长设置为50,我们可以看到结果如下所示:

下面的这个数组就是对应的分类,这里简化为数字123了。
在学习中,也可以手动的创造自己想要的数据集,比如生成一组回归数据:
1 X, y = datasets.make_regression(n_samples=200, n_features=1, n_targets=1, noise=10)
得到的数据集如图所示:

构造的方法参考API文档即可:http://scikit-learn.org/stable/modules/classes.html#samples-generator
② 训练分类器和进行预测
接着我们将iris数据集分为两部分,一部分用来训练分类器,另一部分则是用来进行测试,看看预测的正确率如何。
1 from sklearn import datasets 2 from sklearn.model_selection import train_test_split 3 from sklearn.neighbors import KNeighborsClassifier 4 5 # 读取iris数据集 6 iris = datasets.load_iris() 7 # 获取数据集中的属性值(花瓣和萼片长度宽度) 8 iris_X = iris.data 9 # 获取数据集中的标签,分别是哪种花 10 iris_y = iris.target 11 12 # 将数据分别训练数据和测试数据,测试数据为20% 13 train_X, test_X, train_y, test_y = train_test_split(iris_X, iris_y, test_size=0.2) 14 15 # 创建K邻近分类器 16 knn = KNeighborsClassifier() 17 # 输入训练数据 18 knn.fit(train_X, train_y) 19 # 得到预测标签 20 predicts = knn.predict(test_X) 21 22 # 对比结果 23 print(predicts) 24 print(test_y) 25 26 # 计算准确率 27 print(knn.score(test_X, test_y))
这里首先将数据分成训练和测试数据,接着创建了一个K临近分类器,通过fit方法传入训练数据,predict方法对测试数据进行测试。
得到的结果如图:

这里的准确率可能会不同,因为使用train_test_split方法分离数据会打乱数据集顺序并且随机选择。
这里的K临近分类器,是一个比较简单的分类器,对于每个测试样本,分类器会选取K个(默认是5个)附近的点进行比较,判断哪个分类的点多,则判断为对应的类。因为每个样本有四个属性,所以样本属性需要一个四维空间坐标系表示,但是距离计算公式是类似二维空间的。
当然,scikit-learn还有其他的分类器,可以参考API文档和例子:
http://scikit-learn.org/stable/supervised_learning.html#supervised-learning
③ 持久化
对于一个训练好的模型,可以进行持久化,也就是每次需要使用模型的时候,不需要重新训练。
持久化的方法有多种,可以利用python提供的pickle,但是scikit-learn提供了效率更高的joblib:
1 from sklearn.externals import joblib 2 # 持久化knn分类器 3 joblib.dump(knn, 'save/knn.pk') 4 # 读取knn分类器 5 knn2 = joblib.load('save/knn.pk') 6 print(knn2.score(test_X, test_y))
④ 交叉验证
交叉验证就是对训练数据和测试数据进行多次分组测试模型的准确率,再计算平均值来表示当前模型的优劣。
一个模型中的不同参数,会不同程度的影响模型的准确率,如果模型架构配置不恰当,还会出现过度拟合(overfitting)或者拟合不足(underfitting):
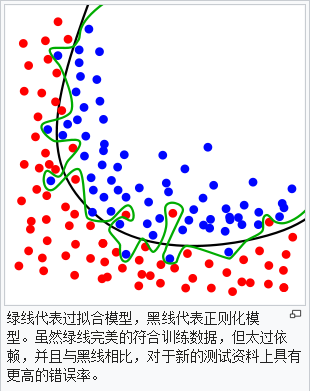
交叉验证,可以通过cross_val_score方法来计算认证的每个分组的分数:
1 from sklearn import datasets 2 from sklearn.model_selection import cross_val_score 3 from sklearn.neighbors import KNeighborsClassifier 4 5 iris = datasets.load_iris() 6 X = iris.data 7 y = iris.target 8 9 knn = KNeighborsClassifier() 10 11 # 交叉验证分数,分为5组 12 scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy') 13 # 输出分组平均值 14 print(scores.mean()) 15 16 # 让K邻近分类器的k从1到30取值并计算认证分数 17 k_range = range(1, 31) 18 k_scores = [] 19 for r in k_range: 20 # 设置k,也就是n_neighbors参数 21 kn = KNeighborsClassifier(n_neighbors=r) 22 # 求平均值并加入k_scores中 23 k_scores.append(cross_val_score(kn, X, y, cv=10, scoring='accuracy').mean()) 24 25 print(k_scores)
打印得到的结果:

使用print打印结果虽然能显示,但是不直观,这里可以通过matplotlib这个库来生成图表,更加直观的看出来对于每个k,哪个的分数更高:
1 import matplotlib.pyplot as plt 2 # 以k_range为x,k_scores为y,拟点并连线 3 plt.plot(k_range, k_scores) 4 # 设置x和y的标签 5 plt.xlabel('n_neighbors') 6 plt.ylabel('score') 7 # 展示图表 8 plt.show()
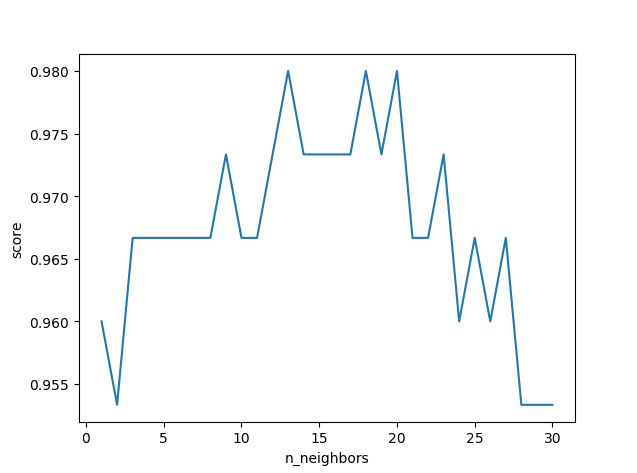
可以看到,k并非越大越好,我们得到这个图表,就可以选择一个得分高对应的k,例如上图的13作为模型的n_neighbors参数。
⑤ 例子
这个例子也是datasets中包含的,手写体数字分类。这里使用官方的一个例子:
http://scikit-learn.org/stable/auto_examples/classification/plot_digits_classification.html#sphx-glr-auto-examples-classification-plot-digits-classification-py
训练完了之后,持久化模型,接着可以尝试预测一下我们自己设计的数字(8*8像素灰度图片,放大模糊了):

测试代码:
1 from PIL import Image 2 import numpy as np 3 from sklearn.externals import joblib 4 5 # 使用pil获取每个像素点的颜色信息(灰度图为二维数组) 6 img = Image.open('four.jpg') 7 img = np.array(img) 8 for i in range(8): 9 for j in range(8): 10 # 根据datasets中的数据修改图片数据信息 11 img[i][j] //= 16 12 img[i][j] = 15 - img[i][j] 13 14 clf = joblib.load('save/digit') 15 print('推断图片中的数字为:', clf.predict(img.reshape((1, -1))))
结果:
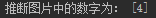
最后,关于回归和聚类的demo,可以参考官方的Examples:
http://scikit-learn.org/stable/auto_examples/index.html
有误,请指出,万分感谢