TFF是不追踪或者维持tff.CLIENTS端任何东西的,在之前的博客TFF Frame的Case代码里,用户的模型是在拿到server_message后重建的(也就是只训练几轮local_model_variables)而不是一直保持、追踪的。发这篇reconstrction文章的谷歌那批人说,因为现实应用的限制,所以stateless更好,然后TFF也是Stateless。很多之前的personalization的文章都是要维持tff.CLIENTS端状态的,这篇文章就简单介绍一下如果把TFF做成stateful主要参考了为TFF提供的源代码[1],这里选择仍然是之前的矩阵分解进行电影推荐的例子,里面的tff.learning.Model和tff.template.IterativeProcess都要重写,正好可以当作TFF Frame和TFF Core的实践。
Model
先把需要用到的深度模型写出来,直接用tf.keras.layers提供的方法,要是按照TFF Frame里从最底层搭建太麻烦了
class UserEmbedding(tf.keras.layers.Layer):
def __init__(self, num_latent_factors, **kwargs) -> None:
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel'
)
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def tf_model(
num_items: int,
num_latent_factors: int) -> tf.keras.Model:
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name="ItemEmbedding"
)
flat_item_vec = tf.keras.layers.Flatten(name="FlattenItem")(
item_embedding_layer(item_input)
)
user_embedding_layer = UserEmbedding(
num_latent_factors,
name="UserEmbedding"
)
flat_user_vec = user_embedding_layer(item_input)
pred = tf.keras.layers.Dot(axes=1, normalize=False, name='Dot')([
flat_user_vec, flat_item_vec
])
model = tf.keras.Model(inputs=item_input, outputs=pred)
return model
model_fn = functools.partial(tf_model, num_items=3706, num_latent_factors=50)
然后开始根据实际需要编写创建变量、计算预测结果、前向传播、本地评估和federated_output_computation要暴露的protocol。这里我也很懒,模型的变量统统塞给model这个参数、能调用keras接口的就绝对不运算。
ModelVariables = collections.namedtuple('ModelVariables', 'num_examples, loss_sum')
loss_fn = tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: tf.keras.metrics.Mean()
def create_variables():
return ModelVariables(
num_examples = tf.Variable(0.0, name="num_examples", trainable=False),
loss_sum = tf.Variable(0.0, name="loss_sum", trainable=False)
)
def predict_on_batch(model, x):
return model(x)
def tf_forward_pass(model, variables, batch):
pred = model(batch['x'])
loss = loss_fn(batch['y'], pred)
num_examples = tf.cast(tf.size(batch['y']), tf.float32)
variables.num_examples.assign_add(num_examples)
variables.loss_sum.assign_add(loss * num_examples)
return loss, pred
def get_local_metrics(variables):
return collections.OrderedDict(
num_examples = variables.num_examples,
loss = variables.loss_sum / variables.num_examples
)
@tff.federated_computation
def aggregate_metrics_across_clients(metrics):
return collections.OrderedDict(
num_examples = tff.federated_sum(metrics.num_examples),
loss = tff.federated_mean(metrics.loss, metrics.num_examples)
)
这里自己编写的类比之前多添了一个_model属性,同时为了维持一些层的参数,增加了local_model_variables和global_model_variables两个属性。
class tff_model(tff.learning.Model):
def __init__(self) -> None:
self._variables = create_variables()
self._model = model_fn()
self._model.build(input_shape=tf_model_input_shape)
@property
def trainable_variables(self):
return self._model.trainable_variables
@property
def non_trainable_variables(self):
return self._model.non_trainable_variables
@property
def local_variables(self):
return [self._variables.num_examples, self._variables.loss_sum,
self._variables.accuracy_sum]
@property
def local_model_variables(self):
return self._model.get_layer(name="UserEmbedding").weights
@property
def global_model_variables(self):
return self._model.get_layer(name="ItemEmbedding").weights
@property
def input_spec(self):
return tff_model_input_spec
@tf.function
def predict_on_batch(self, x, training=True):
del training
return predict_on_batch(self._model, x)
@tf.function
def forward_pass(self, batch, training=True):
del training
loss, predictions = tf_forward_pass(self._model, self._variables, batch)
num_examples = tf.shape(batch['x'])[0]
return tff.learning.BatchOutput(
loss = loss,
predictions = predictions,
num_examples = num_examples
)
@tf.function
def report_local_outputs(self):
return get_local_metrics(self._variables)
@property
def federated_output_computation(self):
return aggregate_metrics_across_clients
@tf.function
def report_local_unfinalized_metrics(self):
return collections.OrderedDict(
num_examples=[self._variables.num_examples],
loss=[self._variables.loss_sum, self._variables.num_examples]
)
def metric_finalizers(self):
return collections.OrderedDict(
num_examples=tf.function(func=lambda x: x[0]),
loss=tf.function(func=lambda x: x[0] / x[1])
)
'''测试代码
a = tff_model()
iterative_process = tff.learning.build_federated_averaging_process(
tff_model,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02))
state = iterative_process.initialize()
state, metrics = iterative_process.next(state, tf_test_datasets[:5])
'''
Iterative Process
整个IterativeProcess的框架大致是这个样子的:
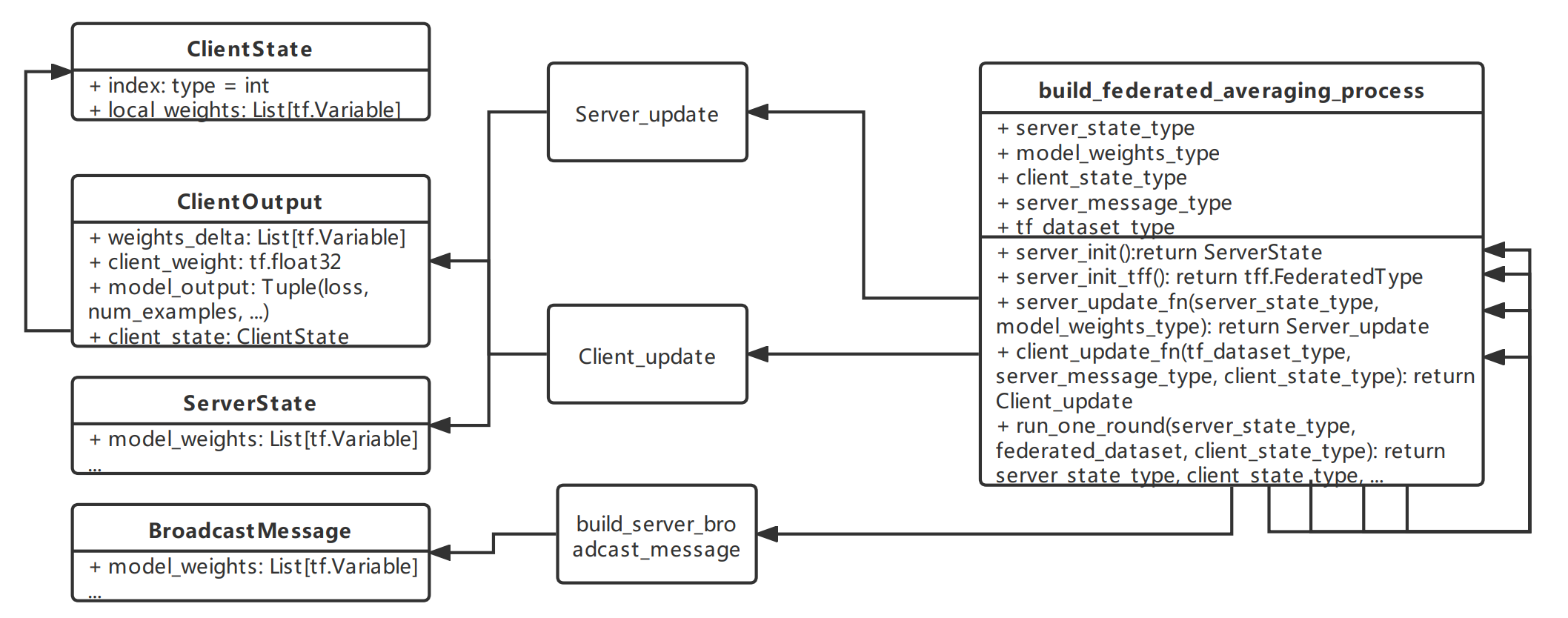
左边的四个作为容器类,其中ClientOutput中又包含了ClientState类;中间的3个作为具体的update和传播实现方法,都用tf.function装饰;右边的实际也是一个函数,为了方便我画成了一个类,其中包含了IterativeProcess具体的实现方法。
Container
4个类我定义的都很简答,其中BroadcastMessage可以用来处理广播前的信息。
@attr.s(eq=False, frozen=True, slots=True)
class ClientState():
index = attr.ib()
local_weights = attr.ib()
@attr.s(eq=False, frozen=True, slots=True)
class ClientOutput():
weights_delta = attr.ib()
client_weight = attr.ib()
loss = attr.ib()
client_state = attr.ib()
@attr.s(eq=False, frozen=True, slots=True)
class ServerState():
model_weights = attr.ib()
@attr.s(eq=False, frozen=True, slots=True)
class BroadcastMessage(object):
model_weights = attr.ib()
Local Methods
这里的Local Methods指的是在服务器端和客户端如何更新。需要注意的是,model这个参数实际上是tff.learning.Model类,我们可以自定义一些属性来简化操作。根据之前的定义,global_model_variables返回物品的Embedding,local_model_variables返回用户的Embedding。这样在server_update的时候只更新global_model_variables对应的权重(即之前定义的ServerState),client_update的时候先复制广播来的server_message中的model_variables(即global_model_variables),再计算梯度信息用来构成ClientOutput。因为这里还不需要对ServerState进行后续处理所以build_server_broadcast_message没有进行操作。
@tf.function
def server_update(model, server_state, server_optimizer, weights_delta):
weights = model.global_model_variables
tf.nest.map_structure(lambda x, y: x.assign(y), weights, server_state.model_weights)
neg_weights_delta = [-1.0 * x for x in weights_delta]
server_optimizer.apply_gradients(zip(neg_weights_delta, weights))
return tff.structure.update_struct(
server_state,
model_weights = weights
)
@tf.function
def build_server_broadcast_message(server_state):
return BroadcastMessage(
model_weights=server_state.model_weights)
@tf.function
def client_update(model, dataset, client_state, server_message, client_optimizer, local_optimizer):
weights_local = model.local_model_variables
weights_global = model.global_model_variables
tf.nest.map_structure(
lambda x, y: x.assign(y),
weights_local,
client_state.local_weights
)
tf.nest.map_structure(
lambda x, y: x.assign(y),
weights_global,
server_message.model_weights
)
num_examples = tf.constant(0, dtype=tf.int32)
loss_sum = tf.constant(0.0, dtype=tf.float32)
for batch in dataset:
with tf.GradientTape(persistent=True) as tape:
outputs = model.forward_pass(batch)
grads_local = tape.gradient(outputs.loss, weights_local)
grads_global = tape.gradient(outputs.loss, weights_global)
localgrads_and_vars = zip(grads_local, weights_local)
globalgrads_and_vars = zip(grads_global, weights_global)
client_optimizer.apply_gradients(globalgrads_and_vars)
local_optimizer.apply_gradients(localgrads_and_vars)
batch_size = (tf.shape(batch['x'])[0])
num_examples += batch_size
loss_sum += outputs.loss * tf.cast(batch_size, tf.float32)
weights_delta = tf.nest.map_structure(
lambda x, y: x-y, weights_global, server_message.model_weights
)
client_weights = tf.cast(num_examples, tf.float32)
return ClientOutput(
weights_delta,
client_weights,
loss_sum / tf.cast(client_weights, dtype=tf.float32),
ClientState(
index = client_state.index,
local_weights = weights_local
)
)
build_federated_averaging_process
这里实现了IterativeProcess类的initialize_fn和next_fn两个方法。基本的框架跟TFF Core相差无几,就是多了一层server_message_fn(虽然这个也没起作用只是传递参数)。
def build_federated_averaging_process(
model_fn, client_state_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.1),
local_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.5)):
# the client_state_fn play the role of generating client_state_type
whimsy_model = model_fn()
@tff.tf_computation
def server_init():
model = model_fn()
return ServerState(
model_weights = model.global_model_variables)
server_state_type = server_init.type_signature.result
model_weights_type = server_state_type.model_weights
client_state_type = tff.framework.type_from_tensors(client_state_fn())
@tff.tf_computation(server_state_type, model_weights_type) # pytype: disable=attribute-error # gen-stub-imports
def server_update_fn(server_state, model_delta):
model = model_fn()
server_optimizer = server_optimizer_fn()
return server_update(model, server_state, server_optimizer, model_delta)
@tff.tf_computation(server_state_type)
def server_message_fn(server_state):
return build_server_broadcast_message(server_state)
server_message_type = server_message_fn.type_signature.result
tf_dataset_type = tff.SequenceType(whimsy_model.input_spec)
@tff.tf_computation(tf_dataset_type, client_state_type, server_message_type)
def client_update_fn(dataset, client_state, server_message):
model = model_fn()
client_optimizer = client_optimizer_fn()
local_optimizer = local_optimizer_fn()
return client_update(model, dataset, client_state, server_message, client_optimizer, local_optimizer)
federated_server_state_type = tff.type_at_server(server_state_type)
federated_dataset_type = tff.type_at_clients(tf_dataset_type)
federated_client_state_type = tff.type_at_clients(client_state_type)
@tff.federated_computation(federated_server_state_type, federated_dataset_type, federated_client_state_type)
def run_one_round(server_state, federated_dataset, client_states):
server_message = tff.federated_map(server_message_fn, server_state)
server_message_at_client = tff.federated_broadcast(server_message)
client_outputs = tff.federated_map(client_update_fn, (federated_dataset, client_states, server_message_at_client))
weight_denom = client_outputs.client_weight
round_model_delta = tff.federated_mean(client_outputs.weights_delta, weight=weight_denom)
round_loss = tff.federated_mean(client_outputs.loss, weight=weight_denom)
server_state = tff.federated_map(server_update_fn, (server_state, round_model_delta))
return server_state, round_loss, client_outputs.client_state
@tff.federated_computation
def server_init_tff():
return tff.federated_value(server_init(), tff.SERVER)
return tff.templates.IterativeProcess(initialize_fn=server_init_tff, next_fn=run_one_round)
Main
Main函数中首先要在外部创造一个client_states的字典用来存储和跟踪client_state,以便在每次next的时候都传入上次的client_state,并且再next获取新的updated_client_states时对外界的client_states进行更新。
def generate_client_state():
model = tff_model()
weights = model.local_model_variables
return ClientState(index=-1, local_weights=weights)
# main
iterative_process = build_federated_averaging_process(tff_model, generate_client_state)
server_state = iterative_process.initialize()
client_states = {i: ClientState(i, generate_client_state().local_weights) for i in range(5)}
for round_num in range(3):
selected_dataset = tf_test_datasets[:5]
sampled_client_states = [client_states[i] for i in range(5)]
server_state, trained_loss, updated_client_states = iterative_process.next(
server_state, selected_dataset, sampled_client_states
)
print(f'Round {round_num} training loss: {trained_loss}')
# update client_states
for client_state in updated_client_states:
client_index = client_state.index
tf.nest.map_structure(lambda x,y: x.assign(y),
client_states[client_index].local_weights, client_state.local_weights)
Code
Import Repositories
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import attr
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
Data Preparation
# data preparation
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str='/tmp') -> Tuple[pd.DataFrame, pd.DataFrame]:
ratings_df = pd.read_csv(
os.path.join(data_directory, 'ml-1m', 'ratings.dat'),
sep="::",
names=['UserID', 'MovieID', 'Rating', 'Timestamp'],
engine="python",
encoding="ISO-8859-1"
)
movies_df = pd.read_csv(
os.path.join(data_directory, 'ml-1m', 'movies.dat'),
sep="::",
names=['MovieID', 'Title', 'Genres'],
engine='python',
encoding="ISO-8859-1"
)
movie_mapping = {
old_movie:new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype('category').cat.categories
)
}
user_mapping = {
old_user:new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype('category').cat.categories
)
}
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
ratings_df, movies_df = load_movielens_data()
def create_tf_datasets(ratings_df: pd.DataFrame, batch_size: int=1, max_examples_per_user: Optional[int]=None, max_clients: Optional[int]=None) -> List[tf.data.Dataset]:
num_users = len(ratings_df)
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
return collections.OrderedDict([
('x', tf.cast(rating_batch[:, 1:2], tf.int64)),
('y', tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn, num_parallel_calls=tf.data.experimental.AUTOTUNE
)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
tf_model_input_shape = tf_train_datasets[0].element_spec['x'].shape
tff_model_input_spec = tf_train_datasets[0].element_spec
Model Construction
# build model
class UserEmbedding(tf.keras.layers.Layer):
def __init__(self, num_latent_factors, **kwargs) -> None:
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel'
)
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def tf_model(
num_items: int,
num_latent_factors: int) -> tf.keras.Model:
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name="ItemEmbedding"
)
flat_item_vec = tf.keras.layers.Flatten(name="FlattenItem")(
item_embedding_layer(item_input)
)
user_embedding_layer = UserEmbedding(
num_latent_factors,
name="UserEmbedding"
)
flat_user_vec = user_embedding_layer(item_input)
pred = tf.keras.layers.Dot(axes=1, normalize=False, name='Dot')([
flat_user_vec, flat_item_vec
])
model = tf.keras.Model(inputs=item_input, outputs=pred)
return model
model_fn = functools.partial(tf_model, num_items=3706, num_latent_factors=50)
ModelVariables = collections.namedtuple('ModelVariables', 'num_examples, loss_sum')
loss_fn = tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: tf.keras.metrics.Mean()
def create_variables():
return ModelVariables(
num_examples = tf.Variable(0.0, name="num_examples", trainable=False),
loss_sum = tf.Variable(0.0, name="loss_sum", trainable=False)
)
def predict_on_batch(model, x):
return model(x)
def tf_forward_pass(model, variables, batch):
pred = model(batch['x'])
loss = loss_fn(batch['y'], pred)
num_examples = tf.cast(tf.size(batch['y']), tf.float32)
variables.num_examples.assign_add(num_examples)
variables.loss_sum.assign_add(loss * num_examples)
return loss, pred
def get_local_metrics(variables):
return collections.OrderedDict(
num_examples = variables.num_examples,
loss = variables.loss_sum / variables.num_examples
)
@tff.federated_computation
def aggregate_metrics_across_clients(metrics):
return collections.OrderedDict(
num_examples = tff.federated_sum(metrics.num_examples),
loss = tff.federated_mean(metrics.loss, metrics.num_examples)
)
class tff_model(tff.learning.Model):
def __init__(self) -> None:
self._variables = create_variables()
self._model = model_fn()
self._model.build(input_shape=tf_model_input_shape)
@property
def trainable_variables(self):
return self._model.trainable_variables
@property
def non_trainable_variables(self):
return self._model.non_trainable_variables
@property
def local_variables(self):
return [self._variables.num_examples, self._variables.loss_sum,
self._variables.accuracy_sum]
@property
def local_model_variables(self):
return self._model.get_layer(name="UserEmbedding").weights
@property
def global_model_variables(self):
return self._model.get_layer(name="ItemEmbedding").weights
@property
def input_spec(self):
return tff_model_input_spec
@tf.function
def predict_on_batch(self, x, training=True):
del training
return predict_on_batch(self._model, x)
@tf.function
def forward_pass(self, batch, training=True):
del training
loss, predictions = tf_forward_pass(self._model, self._variables, batch)
num_examples = tf.shape(batch['x'])[0]
return tff.learning.BatchOutput(
loss = loss,
predictions = predictions,
num_examples = num_examples
)
@tf.function
def report_local_outputs(self):
return get_local_metrics(self._variables)
@property
def federated_output_computation(self):
return aggregate_metrics_across_clients
@tf.function
def report_local_unfinalized_metrics(self):
return collections.OrderedDict(
num_examples=[self._variables.num_examples],
loss=[self._variables.loss_sum, self._variables.num_examples]
)
def metric_finalizers(self):
return collections.OrderedDict(
num_examples=tf.function(func=lambda x: x[0]),
loss=tf.function(func=lambda x: x[0] / x[1])
)
Iterative Process
# iterative process
@attr.s(eq=False, frozen=True, slots=True)
class ClientState():
index = attr.ib()
local_weights = attr.ib()
@attr.s(eq=False, frozen=True, slots=True)
class ClientOutput():
weights_delta = attr.ib()
client_weight = attr.ib()
loss = attr.ib()
client_state = attr.ib()
@attr.s(eq=False, frozen=True, slots=True)
class ServerState():
model_weights = attr.ib()
@attr.s(eq=False, frozen=True, slots=True)
class BroadcastMessage(object):
model_weights = attr.ib()
@tf.function
def server_update(model, server_state, server_optimizer, weights_delta):
weights = model.global_model_variables
tf.nest.map_structure(lambda x, y: x.assign(y), weights, server_state.model_weights)
neg_weights_delta = [-1.0 * x for x in weights_delta]
server_optimizer.apply_gradients(zip(neg_weights_delta, weights))
return tff.structure.update_struct(
server_state,
model_weights = weights
)
@tf.function
def build_server_broadcast_message(server_state):
return BroadcastMessage(
model_weights=server_state.model_weights)
@tf.function
def client_update(model, dataset, client_state, server_message, client_optimizer, local_optimizer):
weights_local = model.local_model_variables
weights_global = model.global_model_variables
tf.nest.map_structure(
lambda x, y: x.assign(y),
weights_local,
client_state.local_weights
)
tf.nest.map_structure(
lambda x, y: x.assign(y),
weights_global,
server_message.model_weights
)
num_examples = tf.constant(0, dtype=tf.int32)
loss_sum = tf.constant(0.0, dtype=tf.float32)
for batch in dataset:
with tf.GradientTape(persistent=True) as tape:
outputs = model.forward_pass(batch)
grads_local = tape.gradient(outputs.loss, weights_local)
grads_global = tape.gradient(outputs.loss, weights_global)
localgrads_and_vars = zip(grads_local, weights_local)
globalgrads_and_vars = zip(grads_global, weights_global)
client_optimizer.apply_gradients(globalgrads_and_vars)
local_optimizer.apply_gradients(localgrads_and_vars)
batch_size = (tf.shape(batch['x'])[0])
num_examples += batch_size
loss_sum += outputs.loss * tf.cast(batch_size, tf.float32)
weights_delta = tf.nest.map_structure(
lambda x, y: x-y, weights_global, server_message.model_weights
)
client_weights = tf.cast(num_examples, tf.float32)
return ClientOutput(
weights_delta,
client_weights,
loss_sum / tf.cast(client_weights, dtype=tf.float32),
ClientState(
index = client_state.index,
local_weights = weights_local
)
)
def build_federated_averaging_process(
model_fn, client_state_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.1),
local_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.5)):
whimsy_model = model_fn()
@tff.tf_computation
def server_init():
model = model_fn()
return ServerState(
model_weights = model.global_model_variables)
server_state_type = server_init.type_signature.result
model_weights_type = server_state_type.model_weights
client_state_type = tff.framework.type_from_tensors(client_state_fn())
@tff.tf_computation(server_state_type, model_weights_type) # pytype: disable=attribute-error # gen-stub-imports
def server_update_fn(server_state, model_delta):
model = model_fn()
server_optimizer = server_optimizer_fn()
return server_update(model, server_state, server_optimizer, model_delta)
@tff.tf_computation(server_state_type)
def server_message_fn(server_state):
return build_server_broadcast_message(server_state)
server_message_type = server_message_fn.type_signature.result
tf_dataset_type = tff.SequenceType(whimsy_model.input_spec)
@tff.tf_computation(tf_dataset_type, client_state_type, server_message_type)
def client_update_fn(dataset, client_state, server_message):
model = model_fn()
client_optimizer = client_optimizer_fn()
local_optimizer = local_optimizer_fn()
return client_update(model, dataset, client_state, server_message, client_optimizer, local_optimizer)
federated_server_state_type = tff.type_at_server(server_state_type)
federated_dataset_type = tff.type_at_clients(tf_dataset_type)
federated_client_state_type = tff.type_at_clients(client_state_type)
@tff.federated_computation(federated_server_state_type, federated_dataset_type, federated_client_state_type)
def run_one_round(server_state, federated_dataset, client_states):
server_message = tff.federated_map(server_message_fn, server_state)
server_message_at_client = tff.federated_broadcast(server_message)
client_outputs = tff.federated_map(client_update_fn, (federated_dataset, client_states, server_message_at_client))
weight_denom = client_outputs.client_weight
round_model_delta = tff.federated_mean(client_outputs.weights_delta, weight=weight_denom)
round_loss = tff.federated_mean(client_outputs.loss, weight=weight_denom)
server_state = tff.federated_map(server_update_fn, (server_state, round_model_delta))
return server_state, round_loss, client_outputs.client_state
@tff.federated_computation
def server_init_tff():
return tff.federated_value(server_init(), tff.SERVER)
return tff.templates.IterativeProcess(initialize_fn=server_init_tff, next_fn=run_one_round)
def generate_client_state():
model = tff_model()
weights = model.local_model_variables
return ClientState(index=-1, local_weights=weights)
Process snippet
# main
iterative_process = build_federated_averaging_process(tff_model, generate_client_state)
server_state = iterative_process.initialize()
client_states = {i: ClientState(i, generate_client_state().local_weights) for i in range(5)}
for round_num in range(3):
selected_dataset = tf_test_datasets[:5]
sampled_client_states = [client_states[i] for i in range(5)]
server_state, trained_loss, updated_client_states = iterative_process.next(
server_state, selected_dataset, sampled_client_states
)
print(f'Round {round_num} training loss: {trained_loss}')
for client_state in updated_client_states:
client_index = client_state.index
tf.nest.map_structure(lambda x,y: x.assign(y),
client_states[client_index].local_weights, client_state.local_weights)