import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from datetime import date
import datetime as dt
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
# 导入CSV文件
off_train = pd.read_csv('ccf_offline_stage1_train.csv', keep_default_na=False)
off_train.columns = ['user_id', 'merchant_id', 'coupon_id', 'discount_rate', 'distance', 'date_received', 'date']
off_test = pd.read_csv('ccf_offline_stage1_test_revised.csv', keep_default_na=False)
off_test.columns = ['user_id', 'merchant_id', 'coupon_id', 'discount_rate', 'distance', 'date_received']
on_train = pd.read_csv('ccf_online_stage1_train.csv', keep_default_na=False)
on_train.columns = ['user_id', 'merchant_id', 'action', 'coupon_id', 'discount_rate', 'date_received', 'date']
off_train.head()
off_train.info()
off_test.head()
off_test.info()
# 领券日期范围
print('offline train date_received')
print(off_train[off_train['date_received'] != 'null']['date_received'].min())# 非空日期
print(off_train[off_train['date_received'] != 'null']['date_received'].max())
print('online train date_received')
print(on_train[on_train['date_received'] != 'null']['date_received'].min())# 非空日期
print(on_train[on_train['date_received'] != 'null']['date_received'].max())
print('offline test date_received')
print(off_test[off_test['date_received'] != 'null']['date_received'].min())# 非空日期
print(off_test[off_test['date_received'] != 'null']['date_received'].max())
# 用券日期范围
print('offline train date')
print(off_train[off_train['date'] != 'null']['date'].min())# 非空日期
print(off_train[off_train['date'] != 'null']['date'].max())
print('online train date')
print(on_train[on_train['date'] != 'null']['date'].min())# 非空日期
print(on_train[on_train['date'] != 'null']['date'].max())
# 训练集与测试集id的重合度
# user_id
off_train_user = off_train[['user_id']].copy().drop_duplicates()
off_test_user = off_test[['user_id']].copy().drop_duplicates()
on_train_user = on_train[['user_id']].copy().drop_duplicates()
print('offline训练集用户ID数量')
print(off_train_user.user_id.count())
print('online训练集用户ID数量')
print(on_train_user.user_id.count())
print('offline测试集用户ID数量')
print(off_test_user.user_id.count())
off_train_user['off_train_flag']=1
off_merge = off_test_user.merge(off_train_user, on='user_id', how="left").reset_index().fillna(0)# 索引,缺失值
print('offline训练集用户与测试集用户的重复数量')
print(off_merge['off_train_flag'].sum())
print('offline训练集用户与测试集重复用户在总测试集用户中的占比')
print(off_merge['off_train_flag'].sum()/off_test_user['user_id'].count())
on_train_user['on_train_flag']=1
on_merge = off_test_user.merge(on_train_user, on='user_id', how="left").reset_index().fillna(0)
print('online训练集用户与测试集用户的重复数量')
print(on_merge['on_train_flag'].sum())
print('online训练集用户与测试集重复用户在总测试集用户中的占比')
print(on_merge['on_train_flag'].sum()/off_test_user['user_id'].count())
#
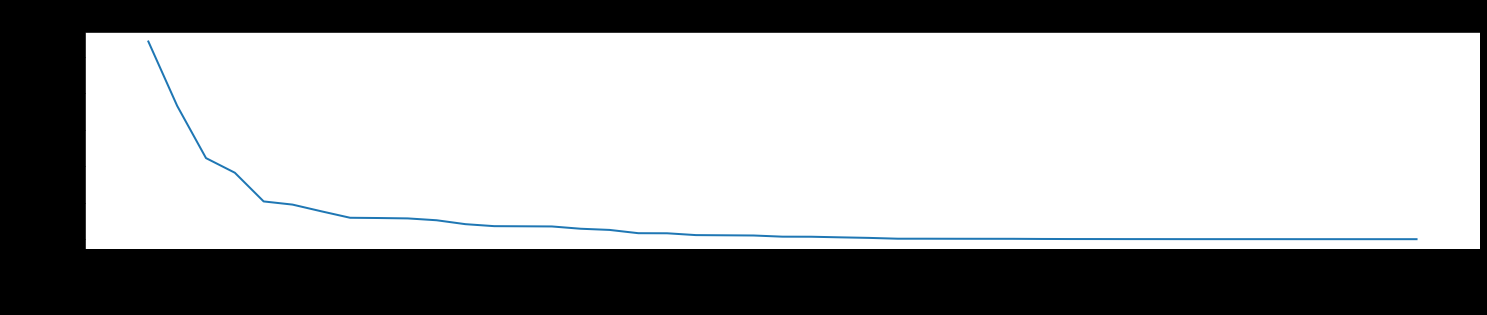
plt.rcParams['figure.figsize'] = (25.0, 4.0)
plt.title("Value Distribution", fontsize=24)
plt.xlabel("Values", fontsize=14)
plt.ylabel("Counts", fontsize=14)
plt.tick_params(axis='both', labelsize=14)
plt.xticks(size='small', rotation=68, fontsize=8)
plt.plot(off_train['discount_rate'].value_counts(), linewidth=2)
plt.show()