通过之前两章的学习,基于input, hidden, output, 3层的神经网络,我们尝试来做一些人工智能的小项目。
前两章链接:
第一章 :https://www.cnblogs.com/ChrisInsistPy/p/9002880.html
第二章 :https://www.cnblogs.com/ChrisInsistPy/p/9056066.html
神经网络在机器学习中有很多应用, 比如说,字符识别,字符识别对于人工智能来说是一项不小的挑战,尤其是在识别的过程中,会遇到很多意想不到的困难,比如清晰度,噪音等等。。。
有些时候,对于人类来说,去识别一个图案上的内容,偶尔也会引起分歧,比如说下面这张图,是4,还是9呢??
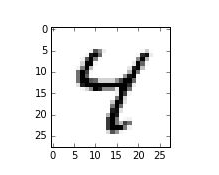
首先,我们知道图片都是由像素组成的,
在MNIST database => http://yann.lecun.com/exdb/mnist/ 可以下载到很多字符识别的成功数据,测试数据,以及一些training data。
我们下载一个100份的成功数据,先进行分析,下载下来的数据是保存为csv文件格式的,所以我们先读入python 数组中,然后再来分析。
def read(): data_file = open('mnist_dataset/mnist_train_100.csv', 'r') data_list = data_file.readlines() data_file.close() print(data_list[0])
首先尝试着打印出第一份数据:

通过观察,发现这组input数据有很多0, 也就是说一会儿我们需要做一下转换,因为0会导致我们的整个weight没法继续更新,导致整个学习过程终止
通过MNIST描述,我们发现数组的第一位,也就是 ‘5‘ 是真实对应的图片数字,从数组下标1开始,后面读到的都是被扫描图片的像素,也就是字符显示的像素,我们通过matplotlib包,把这个像素打印出来,看看是否与结果一致:
def read(): data_file = open('mnist_dataset/mnist_train_100.csv', 'r') data_list = data_file.readlines() data_file.close() all_values = data_list[0].split(',') image_array = numpy.asfarray(all_values[1:]).reshape((28, 28)) plt.imshow(image_array, cmap='Greys', interpolation='None') plt.show() pass
打印出来的结果为:
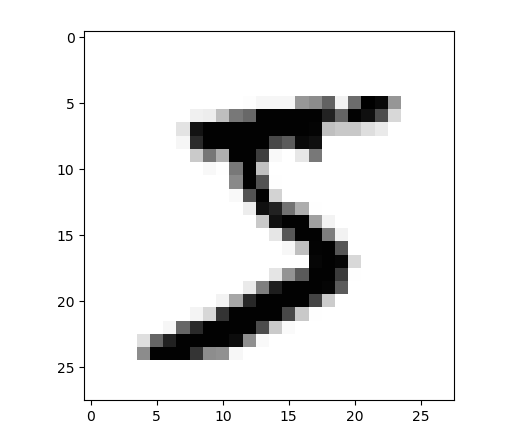
通过人工识别,的确是数字5的可能性最大。这些成功数据,可以用来在我们的机器学习完成后,做结果验证。
--------------------------------------------------------------------------------------------------分割线------------------------------------------------------------------------------------------
upload 一部分代码,明天做解释:
if __name__ == '__main__': input_nodes = 784 hidden_nodes = 100 output_nodes = 10 learning_rate = 0.3 # create instance of neural network n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate) # load data of mnist data_file = open('mnist_dataset/mnist_train_100.csv', 'r') data_list = data_file.readlines() data_file.close() # train the neural network # go through all records in the training data set for record in data_list: all_values = record.split(',') inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 targets = numpy.zeros(output_nodes) + 0.01 targets[int(all_values[0])] = 0.99 n.train(inputs, targets) pass
首先把从MNIST数据集下载的两个文件读入数组,第一组为100个训练data,剩下的一组为10组,验证结果datalist。所以在第一个循环中,我们先modify target数组,让target 的数组样式能跟我们需要的output进行对比,所以我们把target设置为真实值的value为0.99,其他为0.01。 在input中,我们同样把range 为0-255像素的input 缩小到理想的0.01-1之间,所以做了一些数学处理。然后传入train方法进行训练。 在for循环运行完毕后,我们初始化时随机的weight就根据100组正确数据 进行了modify。
根据https://blog.csdn.net/lz0499/article/details/80212695举出下面的例子,方便理解记忆:
让我们实际计算下一个简单的神经网络中权重(weight)是如何更新的。
下图是我们之前遇到的一个神经网络。但是这次我们添加了每一个隐藏层的输出结果。这些输出结果只是为了演示如何更新权重而设置的,实际中并不一定是这个值。
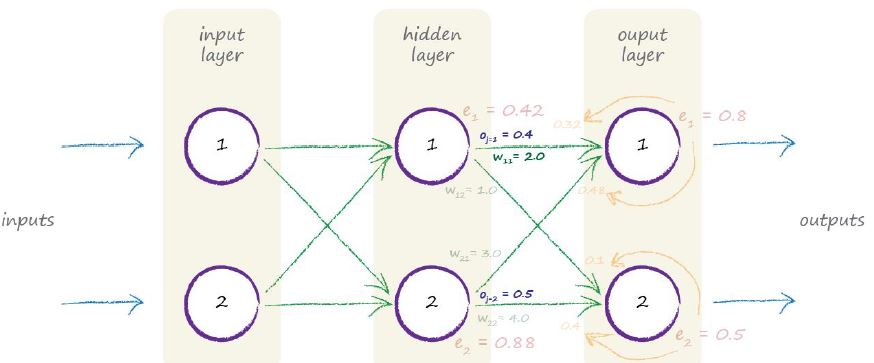
我们想更新隐藏层和输出之间的权重W1,1。W1,1当前的权重值为2.0.
让我们再一次写出误差斜率表达式: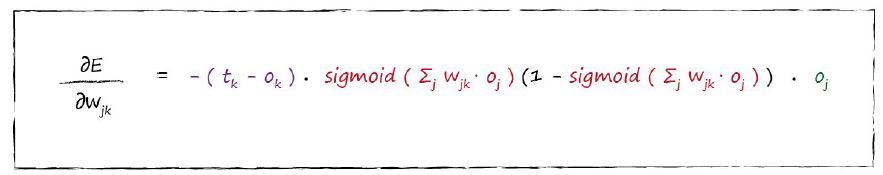
我们一步一步开始计算:
l 第一部分tk-ok是误差e1=0.8
l Sigmoid函数中的加权和为2.0*0.4+3.0*0.5=2.3
l 把2.3带入Sigmoid函数得到0.909.中间表达式为0.909*(1-0.909)=0.083
l 最后一部分Oj即使j=1的隐藏层输出,即为oj=0.4
把上述所有部分相乘,不要忘记前面的负号。我们将得到最后的结果为-0.0265。如果我们设置学习率为0.1,则我们需要改变权重W1,1 -(0.1*-0.0265)=0.002650大小,即W11=2.0+0.002650=2.00265。
这个改变值很小,但是经过上千次甚至上万次迭代之后,权重值将固定在某一个数值,表示的是神经网络已经训练好了。
接下来:
# Test after 100 dataSet runs test_data_file = open('mnist_dataset/mnist_test_10.csv', 'r') test_data_list = test_data_file.readlines() test_data_file.close() scorecard = [] for record in test_data_list: all_values = record.split(',') correct_label = int(all_values[0]) print(correct_label, "correct label") inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 outputs = n.query(inputs) label = numpy.argmax(outputs) print(label, "network's answer") print('------------------') if(label == correct_label): scorecard.append(1) else: scorecard.append(0) print(scorecard)
接下来用同样的方法,去验证我们训练的结果, 其中all_values[0]是我们之前提到的真实数据的正确值,而numpy.argmax()方法,可以得到每组输出output中的最大值,也就是整个程序根据像素分析出的output结果(对应的数组下标0-9便是结果), 然后把正确的结果计入scorecard value=1, 错误的记为0。
打印出scorecard的结果:
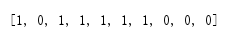
通过100组trainingdata的训练,现在数字识别能力已经达到百分之60的水准!!!也就是performance 达到了百分之60。
Tutorial的作者尝试了另一组实验,也就是用60000组真实数据去training, 然后用10000组真实数据去验证结果,最后得出的performance 高达95.3%。
还有一些优化的方法,比如去调试 learning rate去控制学习率,以及去多次循环training data让神经网络多次学习。
学习次数对结果的影响如图: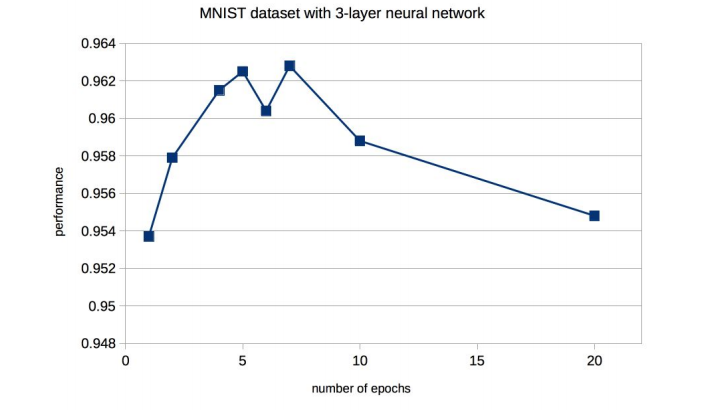
当然改变hidden layer的nodes数量也会对学习结果产生影响。
完整代码:
import numpy import scipy.special class neuralNetwork: def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate): self.inodes = inputnodes self.hnodes = hiddennodes self.onodes = outputnodes self.lr = learningrate # generate the link weights between the range of -1 to +1 self.wih = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes)) self.who = numpy.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes)) self.activation_function = lambda x: scipy.special.expit(x) # sigmoid pass # backpropagating result to modify weight # 通过output来反向修正weight的值,需要用到之前推倒的公式 # targets_list is the real effective data, which used to compare with training outputs def train(self, inputs_list, targets_list): inputs = numpy.array(inputs_list, ndmin=2).T # .T 是.transpose(), 矩阵转置,行变列,列变行 targets = numpy.array(targets_list, ndmin=2).T hidden_inputs = numpy.dot(self.wih, inputs) # 矩阵相乘 wih和inputs hidden_outputs = self.activation_function(hidden_inputs) final_inputs = numpy.dot(self.who, hidden_outputs) final_outputs = self.activation_function(final_inputs) output_errors = targets - final_outputs hidden_errors = numpy.dot(self.who.T, output_errors) # 反向推倒,去modify weight的矩阵 self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)) , numpy.transpose(hidden_outputs)) self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)) , numpy.transpose(inputs)) pass #takes input to a neural network and returns the network's output #输入input,return output def query(self, inputs_list): # Convert input list to 2d array inputs = numpy.array(inputs_list, ndmin=2).T hidden_inputs = numpy.dot(self.wih, inputs) hidden_outputs = self.activation_function(hidden_inputs) final_inputs = numpy.dot(self.who, hidden_outputs) final_outputs = self.activation_function(final_inputs) return final_outputs # Test if __name__ == '__main__': input_nodes = 784 hidden_nodes = 100 output_nodes = 10 learning_rate = 0.2 # create instance of neural network n = neuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate) # load data of mnist data_file = open('mnist_dataset/mnist_train_100.csv', 'r') data_list = data_file.readlines() data_file.close() # train the neural network # go through all records in the training data set for record in data_list: all_values = record.split(',') inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 targets = numpy.zeros(output_nodes) + 0.01 targets[int(all_values[0])] = 0.99 # set the real number => value 0.99 in the output array n.train(inputs, targets) pass # Test after 100 dataSet runs test_data_file = open('mnist_dataset/mnist_test_10.csv', 'r') test_data_list = test_data_file.readlines() test_data_file.close() scorecard = [] for record in test_data_list: all_values = record.split(',') correct_label = int(all_values[0]) print(correct_label, "correct label") inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 outputs = n.query(inputs) label = numpy.argmax(outputs) print(label, "network's answer") print('------------------') if(label == correct_label): scorecard.append(1) else: scorecard.append(0) scorecard_array = numpy.asarray(scorecard) print("performance = ", scorecard_array.sum() / scorecard_array.size)