 重在图像的定位和检测的内容。
重在图像的定位和检测的内容。
一张图片中只有一种给定类别标签的对象,定位则是图像中有对象框;再这些类中,每一个训练目标都有一个类和许多的图像内部对应类的位置选框。
猜想的仅是类标签,不如说它们是位置选框。正确的位置选框,代表你的结果很接近分割的准确率。
研究定位的简单有用基础的范式,就是回归。

这张图片经过一系列的处理过程,最终生成四个代表选框大小的实数,有很多不同的参数来描述选框,人们常用的是用XY坐标定位选框的左上角
、宽度和高度,还有一些ground truth(真实准确的选框),计算欧式损失。
训练流程:
1.用ground truth边框对许多批样本进行抽样,and forward
2.get the loss between the predicted results and ground truth. and carry out the backward
3.download the trained models like VGG、AlexNet. and get the FC layers of class scores
4.现在在这个网络里再接上一些新的全连接层,称为回归网络(regression head),输出的是一些实数。

5.训练这一个回归网络像训练分类网络一样,唯一的区别就是class scores 和class 的损失替换成了L2 loss 和
ground true 选框。
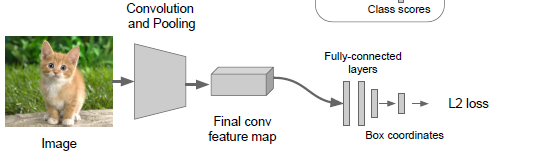
6. finally get the classification network and the regression network
Detail note:在进行回归时一共有两种主要方式,不定类回归(class-logostic regress ) :全连接层都使用相同的结构和权值来得到边界框(bounding box)
and 特定类回归(class- specific regress) :输出的是C * 4个数字,相当于每种类别有一个边界框。
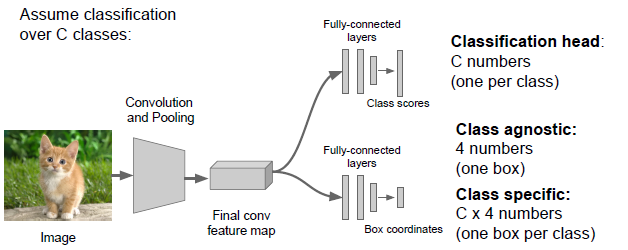
两种回归的Discussion: 对一只猫和对火车确定边界总是有一些不同,你需要网络中有不同的处理来应对这个问题,
它稍微改变了计算损失的方式,它不仅仅是使用ground truth class 来计算损失。
网络在哪一个位置进行回归?

我们可以用这个框架对不止一种物体来划定边界框,输入一张图片,你需要提前知道固定数量的物体进行划定边界框,回归层
输出对于每个物体的边界框,同样训练。
应用于人类姿势判别:需要去找到人类的特定的关节,能够在XY轴上找每个关节的位置,从而让我们对这个人的姿势进行预测。
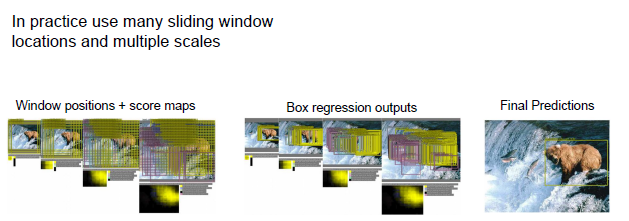
Idea 2: sliding window
思路:和之前的方法相比不只是运行一次,而是在不同的位置多次进行,再将不同的位置进行聚合。
Overfeat的结构:
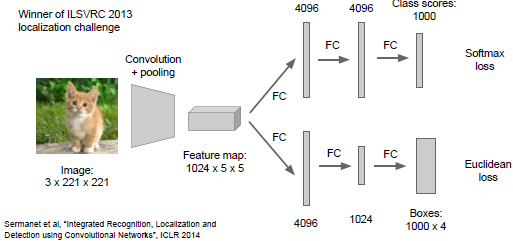
过程:输入图片,在图片左上方进行分类和定位,进而得到类的分数和相应的边界框。重复这个操作,使用相同的分类和
定位网络,在这个图片的四个角落都运行一次,最终得到四个边界框,对于每个位置都有一个边界框和类的分数,并使用一些方法对边界框和分数进行合并,组合和据集不同位置的边界框可以帮助这个模型进行错误修正。
1.在实际操作中要使用远对于四个的边界框;
2.进行回归时,输出的是表示边界框的四个数字,这个数字理论上可能出现在任何地方,他不一定在图片内部,当你在用
sliding window 方法进行训练的时候,你对不同位置进行操作时坐标轴为进行一些改变,事实上,它们选取的位置对于四种.
Discussion: 高效的方法; 网络通常包含卷积网络和全连接网络,一个全连接网络由4096个数字构成,是一个vector,如果不把他看成一个vector,而将他看成另一个卷积的特征映射,这个方法是将全连接层转换成了卷积层,我们得到一个卷积特征映射;考虑通过一个5*5的卷积层,而不是特征特征映射。之后将全连接层转换为1*1的卷积。
我们使用了卷积运算替换了原先的全连接层,优势:网络只由卷积层和池化层的元素构成了,我们就可以使用不同尺寸的图片来运行网络,就可以处理不同尺寸的图片了,在不同大小的图片上使用相同的计算过程。
Discussion:
1、ResNet使用了另外一种定位算法叫RPN(region proposal network)
2、在L2损失值有一个极端值时,是很不好的,所以人们一般不用L2,也可以使用L1损失值,帮助解决极端值的问题,用一个平滑L1函数(Huber损失),看起来和普通的L1差不多,但在接近0的时候更像二次函数,但是里面有噪声的话就不会那么有效。
3.不要选取非反向传播的网络;
4.因为在测试环节,你用的类和训练环节一样,在训练中也需要测试,我们不要求去做不同类之间的泛化,这太难了。
5.实际上人们有时候使用同一个网络,同时训练;有时候人们会分开,用一个网络训练回归,用另一个网络训练分类,两种都可以。