1.写到一个类别下
https://www.pythonheidong.com/blog/article/674750/850e5ee9aa39c1d29ff5/
from torch.utils.tensorboard import SummaryWriter import numpy as np np.random.seed(20200910) writer = SummaryWriter() for n_iter in range(100): writer.add_scalar('Loss/train', np.random.random(), n_iter) writer.add_scalar('Loss/test', np.random.random(), n_iter) writer.add_scalar('Accuracy/train', np.random.random(), n_iter) writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
通过斜杠/来反映等级。结果:
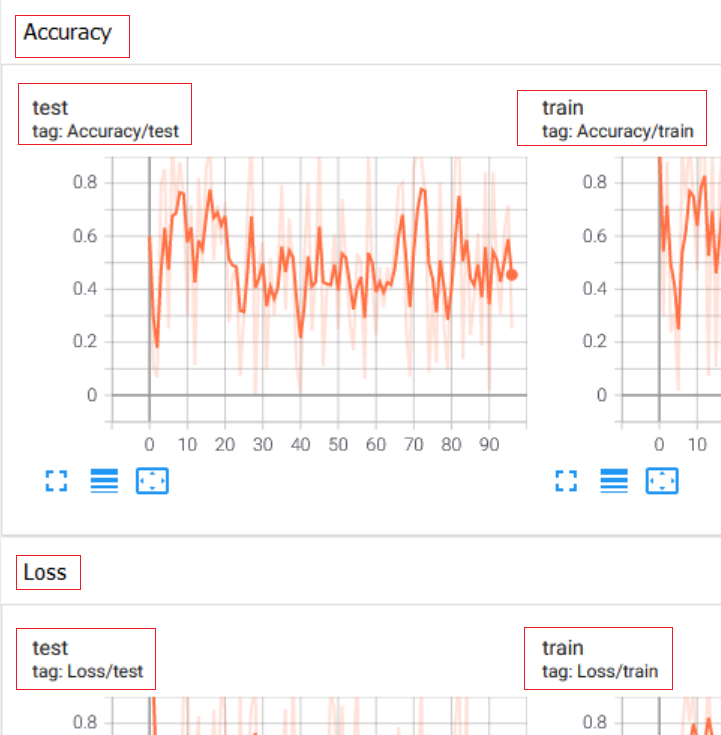
2.在同一个图中添加多个变量
https://blog.csdn.net/sdnuwjw/article/details/107305358
import numpy as np from torch.utils.tensorboard import SummaryWriter # 也可以使用 tensorboardX # from tensorboardX import SummaryWriter # 也可以使用 pytorch 集成的 tensorboard writer = SummaryWriter() for epoch in range(100): writer.add_scalar('add_scalar/squared', np.square(epoch), epoch) writer.add_scalars("add_scalars/trigonometric", {'xsinx': epoch * np.sin(epoch/5), 'xcosx': epoch* np.cos(epoch/5), 'xtanx': np.tan(epoch/5)}, epoch) writer.close()
使用writer.add_scalars()函数添加,在y轴上的类型为字典类型,可容纳多个y结果。

3.在添加时横轴是epoch还是iteration?
https://tensorboardx.readthedocs.io/en/latest/tutorial.html

这里提到每个epoch可以存储loss、accuracy或学习率。但函数参数表示用的iteration。
https://debuggercafe.com/track-your-pytorch-deep-learning-project-with-tensorboard/
上面链接中记录的是每个epoch的损失。
https://dl.ypw.io/how-to-use-tensorboard/
上面链接中给出的例子,既有记录iteration的,记录单个标量:
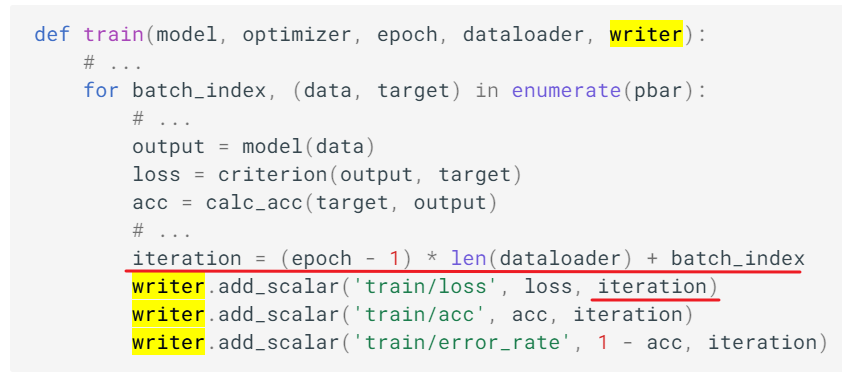
结果图:

也有记录epoch的,记录多个标量:

结果图:
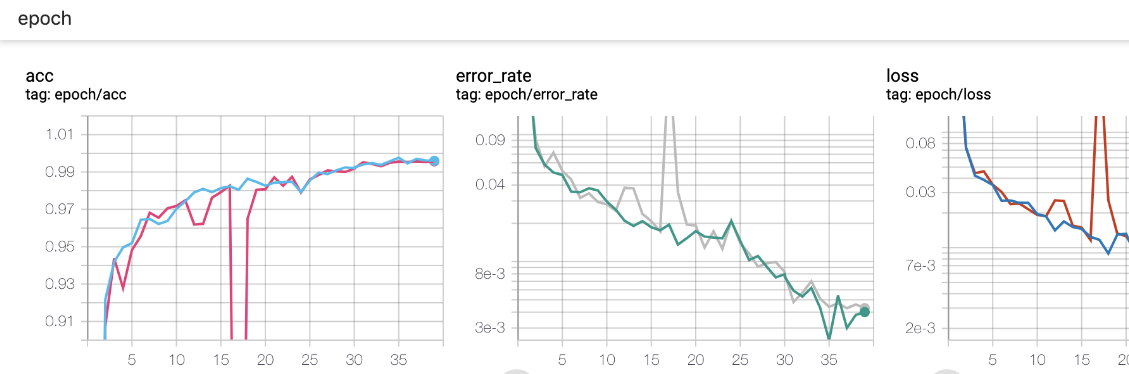
因为要统一横坐标,所以才记录的epoch,因为train和valid的样本量不同,所以batch也不同,这样就会有不同的iteration,就无法统一下标了。
综上所述,记录epoch和iteration都可以,主要看当前的需要是什么。