1.详解Transformer
https://zhuanlan.zhihu.com/p/48508221(非常好的文章)
2.Bert学习
https://zhuanlan.zhihu.com/p/46652512
模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
在针对后续任务微调的过程:
对于sequence-level的分类任务,BERT直接取第一个[CLS]token的final hidden state。
为什么可以直接用[CLS]的最终隐层输出,它的信息能够代表整个句子吗?(疑问)
bert存在的问题是,它将15%的token随机mask掉,最终损失函数只计算被mask掉的token。
Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。具体为什么这么分配,作者没有说。。。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
3.https://www.zhihu.com/question/318355038为何要mask?
回答:

4.Masked语言模型https://www.cnblogs.com/motohq/articles/11632412.html

5.但是bert具体在编码的时候是如何进行的呢?
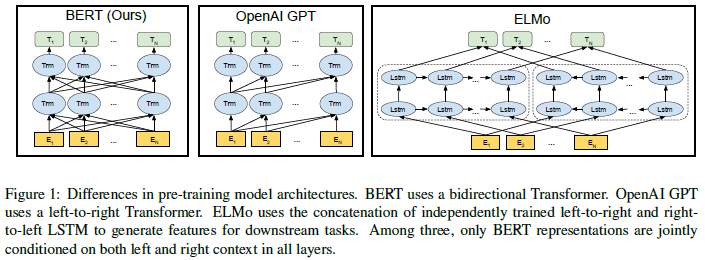
就看这个图我就不明白了,BERT是怎么实现并行的呢?看起来也是根据句子从前到后或者从后到前的顺序啊。
在进行self-att时,计算过程中使用的是QVK,这直接是可以预先得到所有的,那么上图中bert的每个trm节点,都可以同时计算,不需要依赖于前一个词的输出。(个人理解)
上图中三个模型的不同:

BERT是通过上下文去预测当前词,是连续的,而ELMo是独立的前向和后向。
这个讲https://blog.csdn.net/tiantianhuanle/article/details/88597132openai gpt模型,它是单向预测的:

6.bert的源码阅读
http://fancyerii.github.io/2019/03/09/bert-codes/(待看)
7.预训练过程
使用文档级别的语料库,而不是打乱的句子。
8.Bert原论文里提到:
双向的Trf模型通常被称为Transformer encoder,但是 只左上下文的版本称它为Transformer decoder,因为它可以被用来文本生成。
但是看到现在我还是不明白它为啥要随即设置[MASK]???为啥???
9.这里的BASE和LARGE的区别:

这里之前说:

那么正常介绍的tr是6层编码,6层解码,那么BASE就是正常的tr,H为块的隐层数,A是自注意力的个数。(个人理解)
LARGE是12个编码,12个解码。

BASE的结构是和GPT一样的,但是BERT使用双向自注意力,后者使用的是单向,只参考左边的作为上下文。
但是BERT左右上下文是怎么结合的?
https://zhuanlan.zhihu.com/p/69351731 这个文章说明了一下。
#而且这里提到的几个问题都是我想弄明白的点,但是却不知如何提问和如何搜索的!!!太好了。
#损失函数是什么?应该是应用到不同的任务上微调时产生的,和业务有关。
对于文中的第三个问题我还不太明白,可以看一下这个https://nlp.stanford.edu/seminar/details/jdevlin.pdf(待看)
文章里说,Bert可以看作Transformer的encoder部分,那到底是不是呢???如果只是encoder,那我上面就理解错了。
确实是上面理解错了,BERT是tr的encoder的堆叠,L是指有多少个encoder的块,而不包括decoder。
10.bert双向体现在哪?https://www.zhihu.com/question/314280363

原来真的是这个意思啊。

体现在训练策略,也就是遮蔽语言模型上,双向是指的语言模型,OMG。还是不怎么理解。
输入怎么就并行了???
句子中所有单词都是一齐进行计算的,self-att是对整个句子的范围计算。(个人理解)
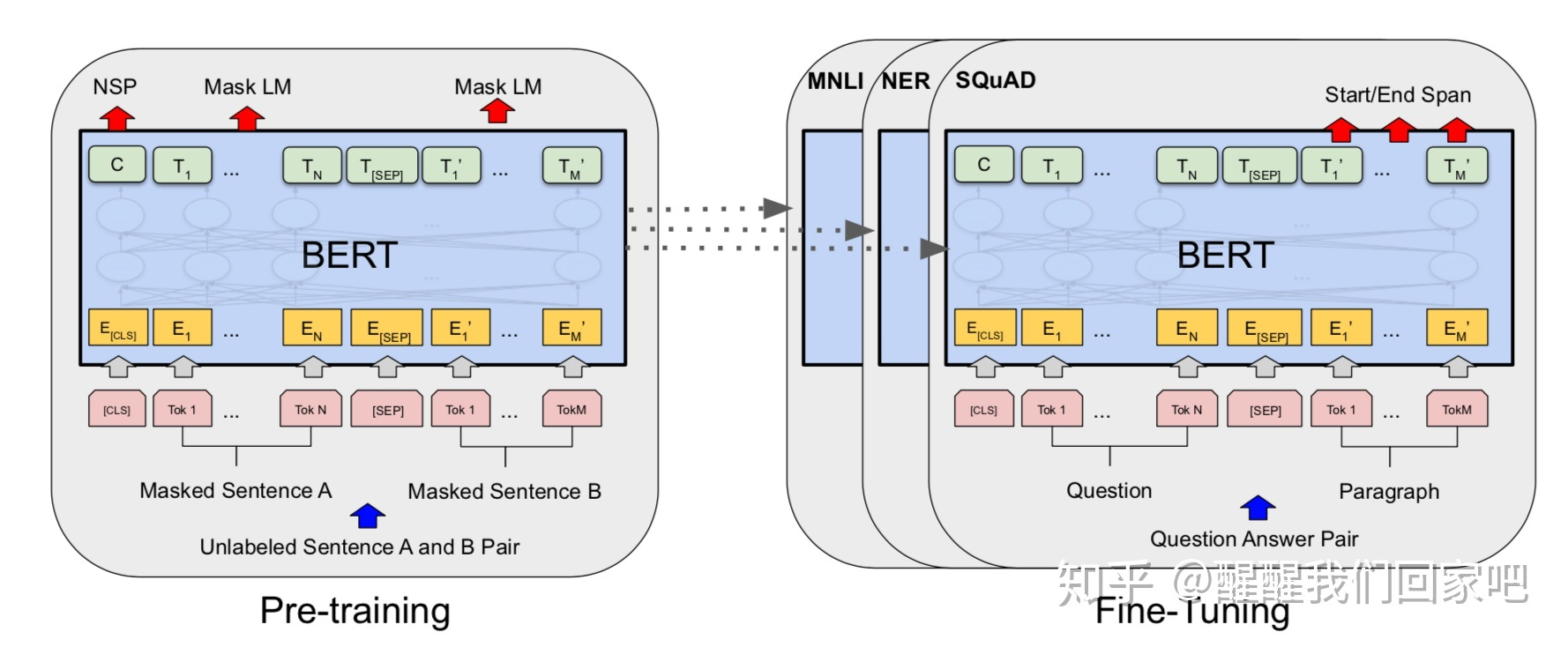
上图真的非常有意思!
11.为什么bert的[cls]可以用来做分类?
https://zhuanlan.zhihu.com/p/74090249

12.