承接上一篇博文中的线性回归中的的cost function。我们想要找出能使得 J(θ)最小的θ(也叫weights)。
其中J(θ)如下所示:
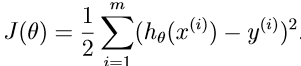
为了做到使其值最小,让我们使用一个search algorithm,起先对θ做初始猜测,并且不断的改变θ来使得J(θ)最小,直到我们有希望地收敛于θ值最小化J(θ)。具体来说,我们考虑一下梯度下降算法(gradient desent algorithm)。
一、梯度下降算法(gradient desent algorithm)、batch gradient descent(批梯度下降)、stochastic gradient descent (also incremental gradient descent)随机梯度下降(递增梯度下降)
它开始于某个初始化的θ,并且不断地执行update(更新):
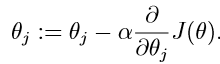 这个更新同时执行了j从0到n。
这个更新同时执行了j从0到n。
参数: α是learning rate(学习率)。
这是一个很自然的算法,它就是不断重复执行一个朝J的最大减速方向(最陡下降方向)的步骤。
为了执行这个算法,我们必须弄清楚等式右边的偏导数项是什么。让我们首先解决这个问题,如果我们只有一个训练样例(x,y)(training sample),那么我们就可以忽略J的定义公式中的求和sum。
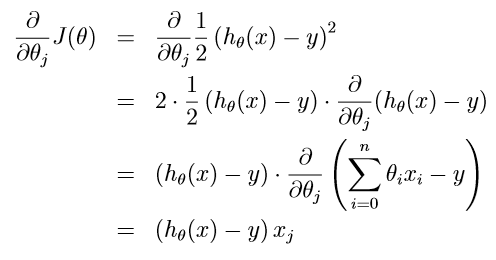
针对一个单一的训练样例,给定update rule:
 (这个rule就叫做LMS update rule,也叫做Widrow-Hoff learning rule)
(这个rule就叫做LMS update rule,也叫做Widrow-Hoff learning rule)
当只有一个训练样例的时候,我们得出了LMS rule。对于多个示例的训练集,有两种方法可以修改此方法。
第一种方法就是用以下的算法替代它,
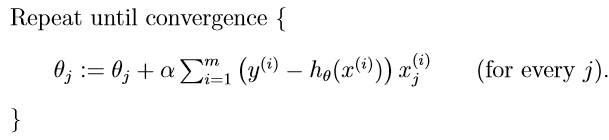
此算法查看每个步骤中整个训练集中的每个示例,并且也叫做batch gradient descent(批梯度下降)
第二种方法可以代替批梯度下降算法,同样也很好:
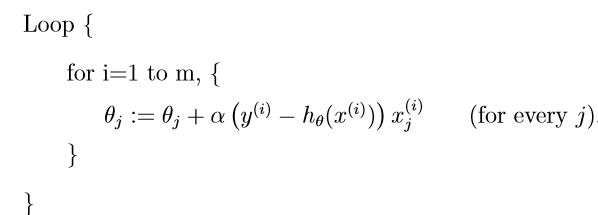
在这个算法中,我们反复运行训练集,并且每次遇到训练样例时,我们仅根据与单个训练样例相关的误差梯度来更新参数。这个算法叫做 stochastic gradient descent (also incremental gradient descent)随机梯度下降(递增梯度下降)。 batch gradient descent在执行一个step之前都要浏览一下整个训练集,但是这在m非常大的情况下是一个costly 的操作,同时,stochastic gradient descent 就可以make progress,并且持续对它所look at的每个样例make progress.因此,通常情况下,stochastic gradient descent 得到接近使得J最小值的θ要比batch gradient descent要更加快。但是要注意,它可能永远不会“收敛”到最低限度,和参数θ将振荡最小的J(θ);但在实践中,大部分接近最小值的值都是合理的接近最小值的近似。由于这些原因,特别是当训练集很大时,随机梯度下降通常比批量梯度下降更受欢迎。