爬取编程常用的英文单词
网站分析:
通过抓包工具进行分析,页面并非为动态加载;
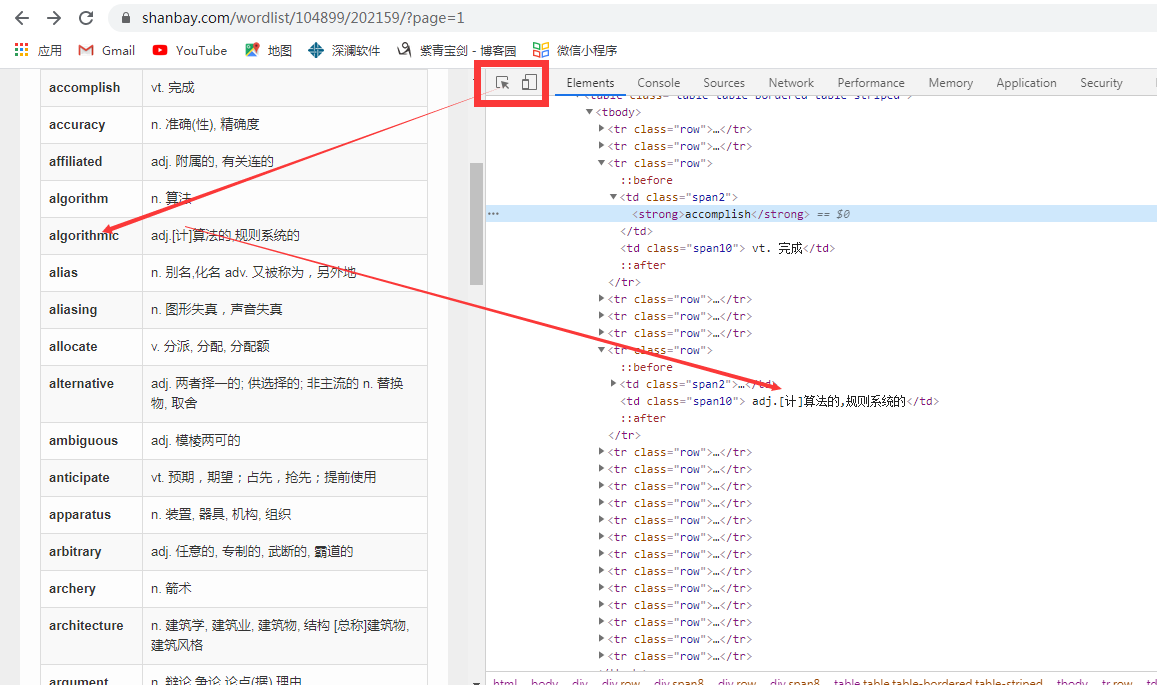
代码编写:
#author:ziqingbajin # title:爬取扇贝网编程需背单词 import requests from time import sleep from lxml import etree from SQL import Sql url='https://www.shanbay.com/wordlist/104899/202159/?page=1' # https://www.shanbay.com/wordlist/104899/202159/?page=2 # 分析url我们可以得知page的变化在改变不同的页面 # 访问url def get_url(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response=requests.get(url=url,headers=headers).text return response # 数据解析 def analysis(response): tree=etree.HTML(response) tr_list=tree.xpath('/html/body/div[3]/div/div[1]/div[2]/div/table/tbody/tr') word_list=[]#定义储存数据的列表 for tr in tr_list: # 将每条单词及汉语存为一条记录 record=[] english_word=tr.xpath('./td[1]//text()')[0]#英语单词 chinese_word=tr.xpath('./td[2]/text()')[0]#汉语翻译 record.append(english_word) record.append(chinese_word) word_list.append(record) return word_list # 数据存储 def save_data(word_list): #接收过来传送的数据 for word_record in word_list: english_word=word_record[0] chinese_word=word_record[1] with open('shanbei.txt','a',encoding='utf-8')as fp: fp.write(english_word) fp.write('\t') fp.write(chinese_word) fp.write('\n') # 保存到数据库中 def save_sql(word_list):
# 此处使用的是自己封装的数据库操作的类。读者可根据 pymssql进行数据库的建立,本案例中创建的数据表是id,English,Chinese三个字段。 conn=Sql('PC') for word_record in word_list: english_word=word_record[0] chinese_word=word_record[1] sqlstr="insert into shanbay(English,Chinese)values('%s','%s')"%(english_word,chinese_word)
#进行异常检测 try: conn.insert(sqlstr) except Exception as e: print(e) if __name__ == '__main__': #构造通用的url for page in range(1,10): print('第%s页数据爬取中······'%(page)) url = 'https://www.shanbay.com/wordlist/104899/202159/?page=%s'%(page) response=get_url(url) word_list=analysis(response) save_data(word_list) save_sql(word_list) print('下载完成!!!')
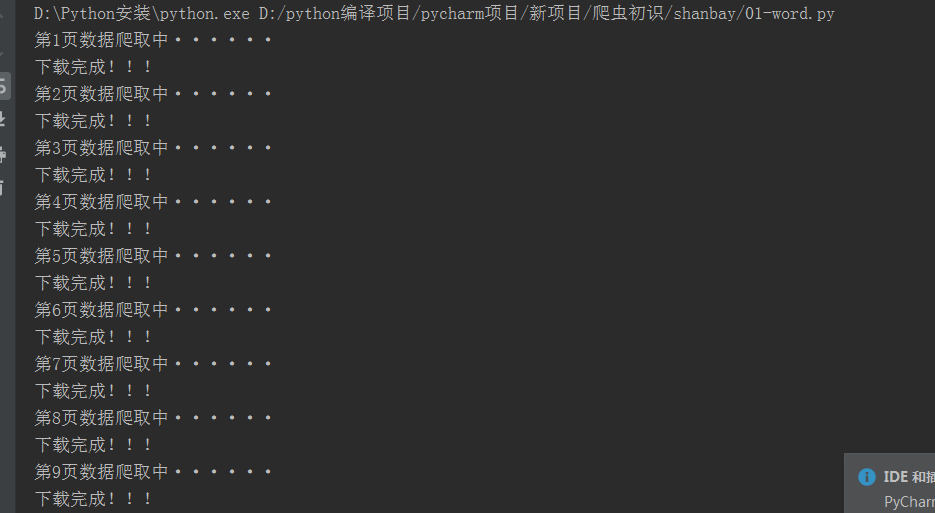
实现效果:
运行时:
存储:


谢谢观看!