-rw——- (600) 只有所有者才有读和写的权限
-rw-r–r– (644) 只有所有者才有读和写的权限,组群和其他人只有读的权限
-rwx—— (700) 只有所有者才有读,写,执行的权限
-rwxr-xr-x (755) 只有所有者才有读,写,执行的权限,组群和其他人只有读和执行的权限
-rwx–x–x (711) 只有所有者才有读,写,执行的权限,组群和其他人只有执行的权限
-rw-rw-rw- (666) 每个人都有读写的权限
-rwxrwxrwx (777) 每个人都有读写和执行的权限
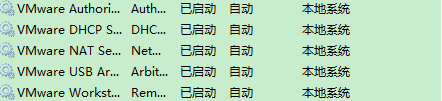
虚拟机莫名奇妙无法联网时:查看windows VM服务是否全部开启
https://www.cnblogs.com/starzy/p/11441131.html
Hive是一个数据仓库基础的应用工具,在Hadoop中用来处理结构化数据,它架构在Hadoop之上,通过SQL来对数据进行操作。
Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的Hive SQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业。
下面总结一下Hive操作常用的一些SQL语法:
"[ ]"括起来的代表我们可以写也可以不写的语句。
创建数据库
CREATE DARABASE name;
- 显示查看操作命令
|
show tables; --显示表 show databases; --显示数据库 show partitions table_name; --显示表名为table_name的表的所有分区 show functions ; --显示所有函数 describe extended table_name col_name; --查看表中字段 |
DDL(Data Defination Language)
数据库定义语言
- 创建表结构
|
table_name col_comment], ...)] table_comment] col_comment], ...)] (col_name, col_name, ...) num_buckets BUCKETS] FORMAT row_format] file_format] [LOCATION hdfs_path] |
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
- EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
- LIKE 允许用户复制现有的表结构,但是不复制数据
- COMMENT可以为表与字段增加描述
- ROW FORMAT 设置行数据分割格式
|
] ] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] |
- STORED AS
|
SEQUENCEFILE | TEXTFILE | RCFILE | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname |
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。
如果数据需要压缩,使用 STORED AS SEQUENCE 。
创建简单表:
|
CREATE TABLE person(name STRING,age INT); |
创建外部表:
|
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, , ) COMMENT '这里写表的描述信息' ROW FORMAT DELIMITED FIELDS TERMINATED BY '�54' TEXTFILE LOCATION '<hdfs_location>'; |
创建分区表:
|
CREATE TABLE par_table(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ) COMMENT 'This is the page view table' STRING, pos STRING) ROW FORMAT DELIMITED ' ' FIELDS TERMINATED BY ' ' STORED AS SEQUENCEFILE; |
创建分桶表:
|
CREATE TABLE par_table(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ) COMMENT 'This is the page view table' STRING, pos STRING) 32 BUCKETS ' FIELDS TERMINATED BY ' ' STORED AS SEQUENCEFILE; |
创建带索引字段的表:
|
CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (dindex STRING); |
复制一个空表:
|
CREATE TABLE empty_key_value_store LIKE key_value_store; |
显示所有表:
|
SHOW TABLES; |
按正则表达式显示表:
|
SHOW TABLES '.*s'; |
表中添加一个字段:
|
ALTER TABLE pokes ADD COLUMNS (new_col INT); |
添加一个字段并为其添加注释:
|
ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment'); |
删除列:
|
ALTER TABLE test REPLACE COLUMNS(id BIGINT, name STRING); |
更改表名:
|
ALTER TABLE events RENAME TO new_events; |
增加、删除分区
|
--增加: ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
--删除: ALTER TABLE table_name DROP partition_spec, partition_spec,... |
改变表的文件格式与组织:
|
ALTER TABLE table_name SET FILEFORMAT file_format ALTER TABLE table_name CLUSTERED BY(userid) SORTED BY(viewTime) INTO num_buckets BUCKETS --这个命令修改了表的物理存储属性 |
创建和删除视图:
--创建视图:
|
CREATE VIEW [IF NOT EXISTS] view_name [ (column_name [COMMENT column_comment], ...) ][COMMENTview_comment][TBLPROPERTIES (property_name = property_value, ...)] AS SELECT;
--删除视图: DROP VIEW view_name; |
DML(Data manipulation language)
数据操作语言,主要是数据库增删改三种操作,DML包括:INSERT插入、UPDATE新、DELETE删除。
向数据表内加载文件:
|
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION(partcol1=val1, partcol2=val2 ...)] --load操作只是单纯的复制/移动操作,将数据文件移动到Hive表对应的位置。 --加载本地 LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
--加载HDFS数据,同时给定分区信息 LOAD DATA INPATH '/user/myname/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15'); |
将查询结果插入到Hive表:
|
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
--多插入模式: FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 ...] select_statement2] ...
--自动分区模式 INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement; |
将查询结果插入到HDFS文件系统中:
|
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ... from_statement ] DIRECTORY directory1 select_statement1 [INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] |
INSERT INTO
|
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1FROM from_statement; |
insert overwrite和insert into的区别:
- insert overwrite 会覆盖已经存在的数据,假如原始表使用overwrite 上述的数据,先现将原始表的数据remove,再插入新数据。
- insert into 只是简单的插入,不考虑原始表的数据,直接追加到表中。最后表的数据是原始数据和新插入数据。
DQL(data query language)数据查询语言 select操作
SELECT查询结构:
|
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference where_condition] ]] col_list col_list] ] [LIMIT number] |
- 使用ALL和DISTINCT选项区分对重复记录的处理。默认是ALL,表示查询所有记录DISTINCT表示去掉重复的记录
- Where 条件 类似我们传统SQL的where 条件
- ORDER BY 全局排序,只有一个Reduce任务
- SORT BY 只在本机做排序
- LIMIT限制输出的个数和输出起始位置
将查询数据输出至目录:
|
INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>'; |
将查询结果输出至本地目录:
|
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a; |
将一个表的结果插入到另一个表:
|
FROM invites a INSERT OVERWRITE TABLE events SELECT a.bar, count(1) WHERE a.foo > 0 GROUP BYa.bar; INSERT OVERWRITE TABLE events SELECT a.bar, count(1) FROM invites a WHERE a.foo > 0 GROUP BYa.bar; JOIN FROM pokes t1 JOIN invites t2 ON (t1.bar = t2.bar) INSERT OVERWRITE TABLE events SELECTt1.bar, t1.foo, t2.foo; |
将多表数据插入到同一表中
|
FROM src INSERT OVERWRITE TABLE dest1 SELECT src.* WHERE src.key < 100 INSERT OVERWRITE TABLE dest2 SELECT src.key, src.value WHERE src.key >= 100 and src.key < 200 INSERT OVERWRITE TABLE dest3 PARTITION(ds='2008-04-08', hr='12') SELECT src.key WHERE src.key>= 200 and src.key < 300 INSERT OVERWRITE LOCAL DIRECTORY '/tmp/dest4.out' SELECT src.value WHERE src.key >= 300; |
Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left semi joins)。Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务。
- LEFT,RIGHT和FULL OUTER关键字用于处理join中空记录的情况
- LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现
- join 时,每次 map/reduce 任务的逻辑是这样的:reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
-
实际应用过程中应尽量使用小表join大表
join查询时应注意的点:
|
--只支持等值连接 SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b a.department = b.department)
--可以 join 多个表 SELECT a.val, b.val, c.val FROM a JOIN b = b.key2)
--如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务 |
LEFT,RIGHT和FULL OUTER关键字
|
--左外连接 SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key) --右外链接 SELECT a.val, b.val FROM a RIGHT OUTER JOIN b ON (a.key=b.key) --满外连接 SELECT a.val, b.val FROM a FULL OUTER JOIN b ON (a.key=b.key) |
LEFT SEMI JOIN关键字
|
--LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT子句或其他地方过滤都不行 value a WHERE a.key in (SELECT b.key B); --可以被写为: SELECT a.key, a.val FROM a LEFT SEMI JOIN b on (a.key = b.key) |
UNION 与 UNION ALL
|
--用来合并多个select的查询结果,需要保证select中字段须一致 select_statement ... --UNION 和 UNION ALL的区别 --UNION只会查询到两个表中不同的数据,相同的部分不会被查出 --UNION ALL会把两个表的所有数据都查询出 |