事后HR回邮件被刷,总结下面试经历。
面试比较全面,主要是oracle的sql开发,博主傻傻的把数据结构和各种算法看了一上午,下午去完全没问。
话说面试大叔记忆力真的好,啥都记得清清楚楚的。
一、Oracle开发
1.取差集
not in、not exists不去重(not in() 中有null值则查询结果为空)
minus去重
集合操作符总结(UNION:由每一个查询 选择的 全部不反复的行组成。并集不包括反复值, 默认按第 1 个查询的第 1 列升序排列。
UNION ALL: 由每一个查询 选择的 全部的行。全然并集包括反复值。 不排序。
MINUS : 在第一个查询中。 不在后面查询中的行。不包括反复。 按第1 个查询的第 1 列升序排列。
INTERSECT: 取每一个查询结果的交集。 不包括反复行。 按第1 个查询的第 1 列升序排列。)
2.行列转换
链接中的基本都用到。
1)wm_concat、listagg
select listagg(sales,',') within GROUP (order by s_date) ,wm_concat(sales) from sales

2)实现split
博主这里没记住正则,开始傻傻的用循环暴力,后来面试的大叔让我随便用什么语言
博主就写了个java的List数组拆分,后来想想完全不同,这里应该是String的split,
用oracle的话就用正则,其他语言支持正则的都可以用正则。这是老夫版的,
面试写的随意,使用方法名递归,估计面试官替我着急。
public static List<String> split1(String a) {
char[] b=(a+",").toCharArray();
String c="";
List<String> d = new ArrayLixt<String>();
for(char x:b) {
if(x==','){
d.add(c);
c="";
}else {
c=c+x;
}
}
return d;
}
3.分析函数
1)普通分析函数就不说了,博主有些遗忘的关于开窗函数的使用吧,具体要的结果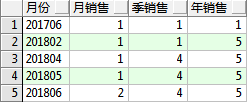
select distinct to_char(s_date,'yyyymm') 月份, sum(sales) over(partition by to_char(s_date,'yyyymm')) 月销售, sum(sales) over(partition by to_char(s_date,'yyyy')||to_char(s_date,'Q')) 季销售, sum(sales) over(partition by to_char(s_date,'yyyy')) 年销售 from sales order by to_char(s_date,'yyyymm')
https://www.jb51.net/article/91232.htm
https://blog.csdn.net/fujiakai/article/details/51066389
2)博主忘记名字的 Lag和Lead函数(可以在一次查询中取出某个字段的前N行和后N行的数据)
4.start with 和prior组合使用
大致上就是查找树关系
select*from tab start with id=1 connect by prior id=fid
大致上开发的问题就这些,其他的可能就是些人尽皆知的问题。
二、数据库优化和相关知识
主要被提及的就是一些优化方面的知识,一般都是程序运行慢了优化的处理过程
吾想面试官君应该想要这类答案
博主思路
1.看执行计划
怎么看:https://blog.csdn.net/java3344520/article/details/5506718
这里博主说了用plsql和oracle的包。
然后是执行计划给的信息都有什么
https://www.cnblogs.com/Dreamer-1/p/6076440.html
博主说主要看反应时间(这里博主已经陷入混乱状态,自己攻击了自己)
然后说了看CPU消耗···(这里估计中年大叔也陷入了混乱状态,他表示问号,炎热的下午)
2.sql优化
https://blog.csdn.net/t0404/article/details/51893311
这里博主大概答了不到一半,因为面试大叔反复问我还有呢还有呢···后来大叔的领导中年大叔也问的是这些
3.数据库优化
这里就是分区分表建立索引,优化redo日志(这里估计不是面试大叔想要的答案,毕竟公司肯定有DBA干这个了)
三、Oracle数据库相关
这里大叔问了一下存储架构,然后博主在纸上涂涂画画写出来了,从表空间到块解释一遍,后来问了个rowid的问题
这里答主说是物理地址(其实不对,可能不太多人知道),然后大叔问我是rowid是的具体含义(这个N个月前有个老爷爷讲过,然鹅...)
废多看链接 https://blog.csdn.net/wxwpxh/article/details/50532464
(普通的堆表中的rowid是物理rowid,索引组织表(IOT)的rowid是逻辑rowid;
你可以像使用其它列一样使用它,只是不能对该列的值进行增、删、改操作;
一旦一行数据插入后,则其对应的ROWID在该行的生命周期内是唯一的,即使发生行迁移,该行的ROWID值也不变。
让我们再回到 TABLE ACCESS BY ROWID 来:行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID可以快速定位到目标数据上,这也是Oracle中存取单行数据最快的方法)
高水位线问题,解释存储架构时一并解释了下(存储结构《oracle内核揭秘》讲的比较详细)