当我们要向数据库中插入一条数据时,我们需要保证主键的唯一性。其实不仅仅是主键的唯一性,也可以是唯一索引列也是可以的
如果插入的数据主键不重复,那么就插入;如果主键已存在(重复),那么就执行update之后的语句。
如果插入的数据唯一索引列不重复,那么数据就会插入成功;如果唯一索引列已存在(重复),那么就执行update之后的语句。
使用方法:
| 单句使用 | 多句使用 |
| insert into 表名 values() on duplicate key update key=key+1 | insert into 表名 values() on duplicate key update key=key+1,updatetime=now() |
数据库表结构如下图所示:
1 CREATE TABLE `user_test` (
2 `user_id` bigint(255) NOT NULL,
3 `user_name` varchar(255) DEFAULT NULL,
4 `sex` varchar(255) DEFAULT NULL,
5 PRIMARY KEY (`user_id`),
6 UNIQUE KEY `user_id_index` (`user_id`) USING BTREE COMMENT '唯一索引'
7 ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
数据库初始化数据如下图所示:

执行下图sql:
1 INSERT INTO user_test
2 VALUES
3 ( 2, 'bbb', '男' )
4 ON DUPLICATE KEY UPDATE user_name = 'eee',
5 sex = '女'
执行上述sql之后,数据库数据如下图所示:
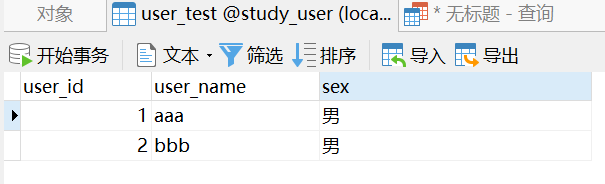
再次执行上述sql之后,数据库数据如下图所示:
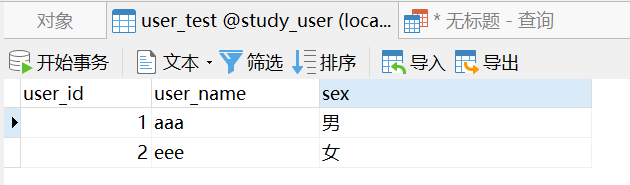
再次执行上述sql之后,数据库数据不会发生变化了。
总结如下所示:
优点:
开发简单,对已有表批量插入新数据时尤其方便(特别是做表数据同步脚本,真香!)
可以减少网络连接开销(减少了数据查询、操作次数),在一定量的数据操作时,效率上也提高。
缺点:
MySQL私有语法,非SQL92标准语法,当迁移数据时会造成麻烦,需要改写代码。例如MySQL迁移PgSQL。
当环境复杂时,数据量大的情况下,会出现意想不到的问题。(数据量大、产生并发,建议还是用原子操作)
业务逻辑分散在应用逻辑层和数据层,会对项目维护留下隐患。
建议:
1、不对存在多个唯一键的数据表使用此语句。
2、在有可能有并发事务执行的insert 语句情况下不使用该语句。
3、使用此语句要考虑以后是否会做数据迁移,数据量是否大,考虑后再使用!!!