
定位有问题的语句
检查执行计划
检查执行过程中优化器的统计信息
分析相关表的记录数、索引情况
改写SQL语句、调整索引、表分析
有些SQL语句不具备优化的可能,需要优化处理方式
达到最佳执行计划

SELECT temp.* FROM ( SELECT t.MODULE 进程, t.PARSING_SCHEMA_NAME 用户, t.EXECUTIONS 执行次数, trunc ( t.CPU_TIME / 1000 / 1000 / t.EXECUTIONS, 5 ) 平均时间, t.OPTIMIZER_MODE 优化方式, t.SQL_TEXT SQL语句, t.CPU_TIME / 1000 / 1000 CPU_TIME, t.DISK_READS 读盘次数, decode( t.COMMAND_TYPE, 3, 'select', 2, 'insert', 6, 'update', 7, 'delete', 'plsql' ) 命令类型, t.SQL_FULLTEXT 完整 SQL, t.SHARABLE_MEM 占用 sharedpool内存, t.BUFFER_GETS 读取缓冲区的次数 FROM V$SQLAREA t WHERE t.EXECUTIONS > 0 AND t.PARSING_USER_ID NOT IN ( 0, 51 )) temp ORDER BY temp.平均时间 DESC, temp.执行次数 DESC

举例: 低效: SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = ’31-DEC-95’ UNION SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = ’31-DEC-95’ 高效: SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = ’31-DEC-95’ UNION ALL SELECT ACCT_NUM, BALANCE_AMT FROM DEBIT_TRANSACTIONS WHERE TRAN_DATE = ’31-DEC-95’

①存在数据类型隐形转换
②列上有数学运算
③使用不等于(<>)运算
④使用substr字符串函数
⑤‘%’通配符在第一个字符
在很多情况下可能无法避免这种情况:
SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.JJDBH like '%2013%'
但是一定要心中有底,通配符如此使用会降低查询速度。然而当通配符出现在字符串其他位置时,优化器就能利用索引。
在下面的查询中索引得到了使用:
SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.JJDBH like '2013%'
⑥字符串连接(||)

如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性.
在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引.
举例:
SELECT t.jjdbh,T.JJYXM,T.JJYGH FROM JJDB t WHERE T.GXDWDM = 330105510000 AND T.JJDBH = '1307221530510234'
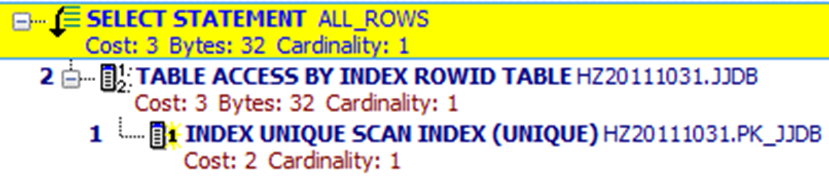

如果索引是建立在多个列上, 只有在它的第一个列被where子句引用时,优化器才会选择使用该索引

SELECTt.jjdbh,T.JJYXM,T.JJYGH FROM JJDB t WHERE T.HRSJ > sysdate -1

SELECTt.jjdbh,T.JJYXM,T.JJYGH FROM JJDB t WHERE T.JJLXDM =1
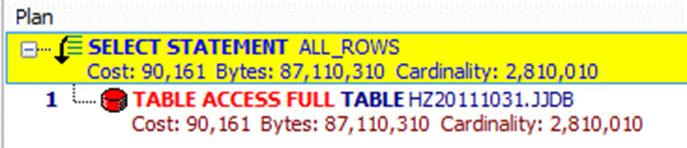

WHERE子句中,如果索引列是函数的一部分.优化器将不使用索引而使用全表扫描.
SELECT t.JJDBH,T.JJYXM,T.JJYGH FROM JJDB t WHERE T.JJDBH || '88' = '138722153851823488';
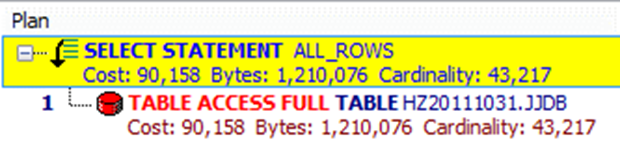
SELECT t.JJDBH,T.JJYXM,T.JJYGH FROM JJDB t WHERE T.JJDBH =substr( '138722153851823488',0,16);
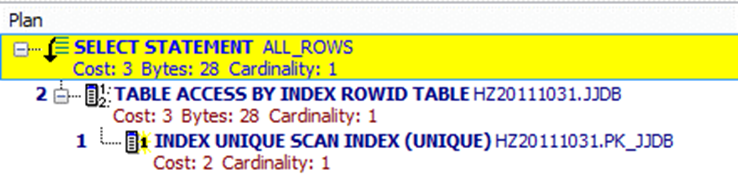

WHERE子句中, 如果索引列所对应的值的第一个字符由通配符开始, 索引将不被采用.
SELECT t.jjdbh,T.JJYXM,T.JJYGH FROM JJDB t WHERE T.JJDBH LIKE '%1387221538518234';
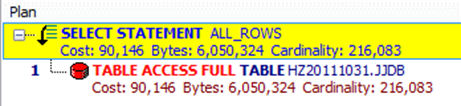
SELECT t.JJDBH, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.JJDBH LIKE '1387221538518234%';
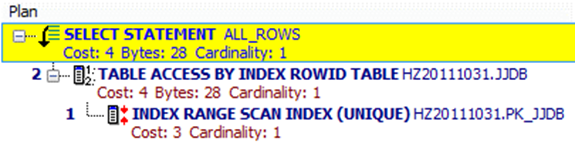

任何在 WHERE子句中使用IS NULL或IS NOT NULL的语句优化器是不允许使用索引的
SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.HRSJ IS NOT NULL SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.HRSJ IS NULL
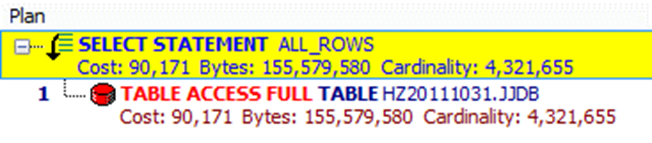
避免出现索引列自动转换
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换.因为内部发生的类型转换, 这个索引将不会被用到!
SELECT t.JJDBH, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.JJDBH = '66666666‘
SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.JJDBH = 66666666
减少访问数据库的次数
当执行每条SQL语句时, ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等等.
由此可见, 减少访问数据库的次数 , 就能实际上减少ORACLE的工作量
使用DECODE来减少处理时间
SELECT COUNT (*), SUM (t.jjsc) FROM JJDB t WHERE T.HRSJ > TO_DATE ('2013-7-26', 'yyyy-mm-dd') AND T.HRSJ < TO_DATE ('2013-7-29', 'yyyy-mm-dd') AND T.BJLBDM = 10; SELECT COUNT (*), SUM (t.jjsc) FROM JJDB t WHERE T.HRSJ > TO_DATE ('2013-7-26', 'yyyy-mm-dd') AND T.HRSJ < TO_DATE ('2013-7-29', 'yyyy-mm-dd') AND T.BJLBDM = 99; SELECT COUNT (DECODE (t.BJLBDM, 10, 1, NULL)) count_lb10, COUNT (DECODE (t.BJLBDM, 99, 1, NULL)) count_lb99, SUM (DECODE (t.BJLBDM, 10, t.jjsc, NULL)) sum_lb10, SUM (DECODE (t.BJLBDM, 99, t.jjsc, NULL)) sum_lb99 FROM JJDB t WHERE T.HRSJ > TO_DATE ('2013-7-26', 'yyyy-mm-dd') AND T.HRSJ < TO_DATE ('2013-7-29', 'yyyy-mm-dd')
减少对表的查询
在含有子查询的SQL语句中,要特别注意减少对表的查询.
SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE T.JJYXM = (SELECT xm FROM jjyb WHERE bh = 307) AND T.JJYGH = (SELECT jjyjh FROM jjyb WHERE bh = 307);
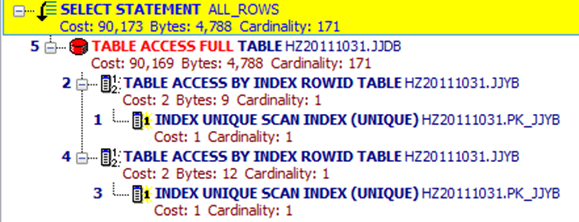
SELECT t.jjdbh, T.JJYXM, T.JJYGH FROM JJDB t WHERE (T.JJYXM, T.JJYGH) = (SELECT xm, jjyjh FROM jjyb WHERE bh = 307)
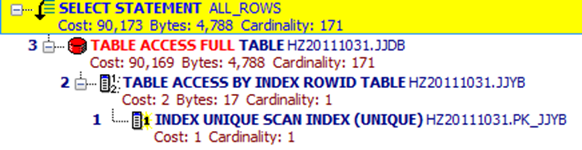
组合索引
由多个列构成的索引,如create index IDX_JJDB1 on JJDB (HRSJ, JJDM, BSDM, JJYGH) ,
则我们称IDX_JJDB1索引为组合索引。在组合索引中有一个重要的概念:引导列,在上面的例子中, HRSJ列为引导列。
当我们进行查询时可以使用”where HRSJ = ? ”,也可以使用”where HRSJ = ? and JJDM= ?”,这样的限制条件都会使用索引,
但是”where BSDM= ? ”查询就不会使用该索引。
所以限制条件中包含先导列时,该限制条件才会使用该组合索引。
常用Sql _ 查看表空间
SELECT b.file_name 物理文件名, b.tablespace_name 表空间, b.bytes / 1024 / 1024 大小 M, ( b.bytes - sum( nvl ( a.bytes, 0 ))) / 1024 / 1024 已使用 M, substr(( b.bytes - sum( nvl ( a.bytes, 0 ))) / ( b.bytes ) * 100, 1, 5 ) 利用率 FROM dba_free_space a, dba_data_files b WHERE a.file_id = b.file_id GROUP BY b.tablespace_name, b.file_name, b.bytes ORDER BY b.tablespace_name;
更改表空间大小
ALTER DATABASE datafile '/ora/oradata/radius/undo.dbf' resize 10240m;
常用Sql _ 查看当前连接会话
SELECT * FROM v$ SESSION WHERE username IS NOT NULL; SELECT username, count( username ) FROM v$ SESSION WHERE username IS NOT NULL GROUP BY username;
常用 SQL _ 表锁相关
1.查看被锁的表 SELECT
SELECT p.spid,a.serial#,c.object_name, b.session_id, b.oracle_username,b.os_user_name FROM v$process p, v$ SESSION a, v$locked_object b, all_objects c WHERE p.addr = a.paddr AND a.process = b.process AND c.object_id = b.object_id
2.查看是哪个进程锁的
SELECT sid,serial#, username, osuser FROM v$session where osuser = 'dsdb'
3.杀掉这个进程
ALTER system KILL SESSION 'sid,serial#';
如果表中的时间字段是索引,那么时间字段不要使用函数,函数会使索引失效。
例如:
select * from mytable where trunc(createtime)=trunc(sysdate);
--不走索引,慢吞吞。createtime字段有时分秒,使用trunc()函数去除时分秒,只保留年月日
改进方案:
select * from mytable where createtime between to_date(to_char(trunc(SYSDATE), 'yyyy/mm/dd hh24:mi:ss'), 'yyyy/mm/dd hh24:mi:ss') and to_date(to_char(trunc(SYSDATE), 'yyyy/mm/dd hh24:mi:ss'), 'yyyy/mm/dd hh24:mi:ss');
--走索引,效率飞升
避免使用 *
当你想在SELECT子句中列出所有的列时,使用动态 SQL列引用 ‘*’ 是一个方便的方法.这是一个非常低 效的方法. 实际上,
ORACLE在解析的过程中, 会将’*’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间;
ORACLE在解析sql语句的时候对FROM子句后面的表名是从右往左解析的,是先扫描最右边的表,然后在扫描左边的表,然后用左边的表匹配数据,匹配成功后就合并。
所以,在对多表查询中,一定要把小表写在最右边,如果有中间表,中间表写在最右边,然后是最小表。
ORACLE采用自下而上、从右向左的顺序解析WHERE子句,可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。
影响查询速度的条件写在WHERE子句的最前面。像索引查询速度快的就放在where条件的末尾。
在含有子查询的SQL语句中,不要同一个表查询多次。
通常来说 ,采用表连接的方式比EXISTS更有效率 。
最终结果如何,请参考实际测试的运行时间
具体参考:https://www.cnblogs.com/zjfjava/p/7092503.html