此为计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面。
1. Active Appearance Models
活动表观模型和活动轮廓模型基本思想来源 Snake,现在在人脸三维建模方 面得到了很成功的应用,这里列出了三篇最早最经典的文章。对这个领域有兴趣 的可以从这三篇文章开始入手。
[1998 ECCV] Active Appearance Models
[2001 PAMI] Active Appearance Models
2. Active Shape Models
[1995 CVIU]Active Shape Models-Their Training and Application
翻译
主动外观模型
摘要 -我们描述外观的统计模型匹配图像的新方法。一组模型的参数的形状和灰度级的变化的控制模式从训练集学习。我们通过学习模型中的参数和引入图像误差扰动之间的关系构造的高效的迭代匹配算法。
关键词:外观模型,变形模板,模型匹配。
1 引言
以下简称 “解释通过合成” 的方式已经得到相当的重视,在过去几年中[3],[6],[11],[14]。其目的是通过产生尽可能相似的合成图像,使用外观的参数化模型“解释”新颖的图像。一个动机是通过使用模型来约束的解决方案是仿照类图像的有效实例来实现强大的分割。一种合适的模型也通过在一个紧凑的组的那些对场景的更高级别的解释有用参数方面编码一个给定的图像的外观提供了广泛的应用的基础。
建模照片般逼真的外观的合适的方法先前已被描述,例如,Edwards等人。 [3],Jones和Poggio[9],或 Vetter [14])。当应用到复杂的对象和可变对象的图像(例如,面对),这些模型通常需要大量的参数(50-100)。为了解释新颖的图像,需要找到模型和图像之间的最佳匹配的有效方法。在这个高维空间直接优化,可以使用标准方法,但它是缓慢的[9]和/或可变得被困在局部极小。
我们以前曾表明[11],[3]的外观的统计模型可以在两个步骤中被匹配到一个图像:首先,将主动形状模型在图像中相匹配的边界特性,则单独的特征脸模型被用于重建的形状归一化的帧纹理(在图形的意义上)。这种方法是没有,但是,保证给外观模型的最佳拟合到图像,因为在所述形状模型的匹配的小误差可能导致不能使用本征脸模型正确重建的形状归一化的纹理贴图。
在本文中,我们表明,同时相匹配的形状和质地,导致算法快速,准确,和强大的高效的直接优化方法。在我们的方法,我们不尝试每次我们希望将模型拟合到一个新的图像的时间来解决一般的优化问题。相反,我们利用的事实,优化问题是类似的,每次这样我们就可以离线学习这些相似之处。这使得我们即使搜索空间具有非常高维度找到快速收敛的方向。该方法具有与“差分解”跟踪算法的相似性[7],[8],[13],但不是跟踪单个变形对象我们匹配其可适合一整类的对象的模型。
2 背景
几位作者已经描述了方法的形状和外观的变形模型匹配新颖的图像。 Nastar等人[12]描述了使用强度景观的3D可变形模型的形状和强度变化的模型。他们利用最近点表面匹配算法进行拟合,这往往是初始化敏感。 Lanitis 等人[11]和Edwards等人 [3]使用的边界寻找算法(一种“主动形状模型”)找到最佳的形状,然后使用此来匹配图像纹理的模型。Poggio等人 [6],[9]使用光学流算法迭代地匹配的形状和纹理模型,和Vetter[14]使用的通用优化方法真实感人脸模型匹配的图像。最后两种方法是因为这个问题的高维和测试针对图像模型的拟合的质量为代价的慢。
快速模式匹配算法已经在追踪社区中发展了。 Gleicher [7]通过允许单个模板来在各种变换(仿射,投射等)的变形描述跟踪对象的方法。他选择的参数以最小化测量平方的总和,并且基本上预计算的差矢量的衍生物相对于所述变换的参数。Hager和Belhumeur [8]描述了类似的方法,但包括健壮内核和照明变化的模型。 Sclaroff和Isidoro[13]延伸跟踪哪些变形对象的方法中,使用目标的有限元模型的低能量模式建模变形。该方法已被用于跟踪使用的头部的圆柱形刚性模型头[10]。
下面描述的主动外观模型是这种方法[4],[1]的一个扩展。而不是跟踪特定对象,我们的外表的模型可以匹配于任何一类可变形对象中的(例如,任何面与任何表达式,而不是一个人脸与特定的表达)。为了快速匹配,我们预先计算的模型和对象图像之间的匹配的剩余的衍生物,并利用它们来计算迭代匹配算法更新步骤。为了使该算法不敏感的整体强度的变化,残差计算在归一化的参考帧。
3 外观造型
继 Edwards 等人[3]的做法,通过形状变化的模型组合与纹理变化的模型生成的我们的统计外观模型。通过“纹理”,我们指的强度或颜色的整个图像补丁的模式。要建立一个模型,我们要求地方相应的点都被标记上的每个例子注释的图像的训练集。例如,为了构建一个脸部模型,我们需要标有限定的主要特征(图1)的点的面部图像。我们应用普鲁克Procrustes分析对齐的点的集合(每个表示为向量,x)和建立一个统计形状模型[2]。然后,我们翘曲每个训练图像,从而这些点匹配那些平均形状的,获得一个“自由形状补丁”(图1)。这是光栅扫描到纹理向量,g,这是通过施加线性变换,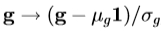 ,其中1是由1的向量归一化,
,其中1是由1的向量归一化,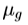 和
和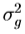 的平均值和g的元素的方差。归一化之后,中
的平均值和g的元素的方差。归一化之后,中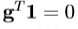 和
和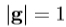 。本征分析方法,建立一个纹理模型。最后,形状和纹理之间的相关性被学习以生成组合的外观模型(参见[3]的详细信息)。
。本征分析方法,建立一个纹理模型。最后,形状和纹理之间的相关性被学习以生成组合的外观模型(参见[3]的详细信息)。

图1:一种标记的训练图像给出的形状自由贴片和一组点。
外观模型具有根据参数,C,控制形状和质地(在模型帧)

其中,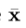 是均值形状,
是均值形状,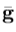 的平均纹理的平均形贴片,和
的平均纹理的平均形贴片,和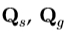 是描述从训练集导出的变化的模式矩阵。
是描述从训练集导出的变化的模式矩阵。
形状,X,在图像帧中可以通过施加合适的变换到点处产生,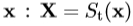 。典型地,
。典型地,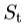 将是通过缩放,s中描述的相似变换,在面内旋转
将是通过缩放,s中描述的相似变换,在面内旋转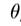 ,和平移
,和平移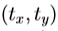 。对于线性,我们所代表的缩放和旋转为
。对于线性,我们所代表的缩放和旋转为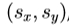 ,其中
,其中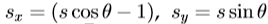 。姿态参数向量
。姿态参数向量 是然后为恒等变换和
是然后为恒等变换和 的零点。
的零点。
在图像帧中的纹理是通过应用缩放生成和偏移到的强度,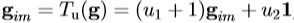 ,其中,u是变换参数的矢量,定义,以便为u = 0是恒等变换和
,其中,u是变换参数的矢量,定义,以便为u = 0是恒等变换和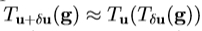 。
。
一个完整的重建是通过产生在平均形贴片纹理,然后翘曲它使得模型点位于图像点给出,X.在以下描述的实验中,我们使用基于三角测量的插值方法以限定连续的映射。
在实践中,我们构造基于高斯图像金字塔多分辨率模式。这允许多分辨率的方法来匹配,从而提高速度和稳定性。对于金字塔的每个级别,我们建立了一个单独的纹理模型,图像中的目标区域的采样数成正比的区域中的像素(像素)。因此,在第1级,该模型具有四分之一级别0处为简单的像素的数目,我们使用相同的一组地标在每个水平和相同的形状模型。虽然点的严格的数量应该在较低的分辨率降低,任何细节模糊由纹理模型加以考虑。在给定水平的外观模型然后,计算给定的全局形状模型和该级别的特定纹理模型。
3.1 面孔外观模型
我们使用上述构建面部外观的模型的方法。我们使用了训练设定面400幅的图像,每一个标有周围的主要特征(图1)68点,并且从面部区域采样的约10,000的强度值。从此,我们产生这需要55个参数来解释观察到的变化的95%的外观模型。图2示出从C改变第一四个参数,示出了身份,姿势,和表达的变化的效果。注意形状和强度变化之间的相关性。

图2:不同的前四个面部外观模型参数的影响,C1-C4 通过从平均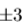 个标准偏差。
个标准偏差。
4 ACTIVE外观模型搜索
我们现在转到由本文解决的核心问题:我们必须解释新的图像,上面的位置,方向和比例的和粗略初始估计在此模型应该被放置在如所描述的完整的外观模型图片。我们需要用于调整模型参数,使得合成的例子中产生,其中所述图像尽可能紧密匹配的有效方案。
4.1 模拟图像残差
外观模型参数,c和形状变换参数,t,定义在所述图像帧中,X,这使得所述图像块的形状,以由模型表示的模型点的位置。在匹配过程中,我们样品中的图像,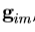 ,和项目的这个区域中的像素到纹理模型框架,
,和项目的这个区域中的像素到纹理模型框架,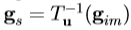 。当前模型的纹理是由
。当前模型的纹理是由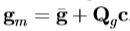 给定的模型和图像(在归一化的纹理帧测量的)之间的电流差是这样
给定的模型和图像(在归一化的纹理帧测量的)之间的电流差是这样

其中,p是模型, 的参数。
的参数。
差的一个简单的标量量度是r,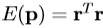 的元素的平方和。 (2)给出了一阶泰勒展开
的元素的平方和。 (2)给出了一阶泰勒展开
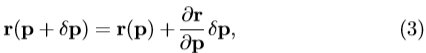
其中矩阵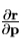 的第 ij 个元件为
的第 ij 个元件为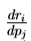
假设在匹配我们当前的剩余为r。我们希望选择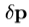 以尽量减少
以尽量减少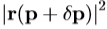 。通过等同(3)为零,我们得到RMS溶液,
。通过等同(3)为零,我们得到RMS溶液,
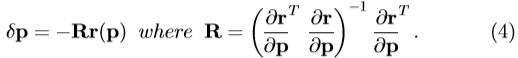
在标准的优化方案,将有必要在每一步,一个昂贵的操作来重新计算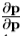 。然而,我们假设,因为它是在归一化的参考帧被计算,它可以被认为是近似固定。我们可以从这样的训练组估计一次。我们估计
。然而,我们假设,因为它是在归一化的参考帧被计算,它可以被认为是近似固定。我们可以从这样的训练组估计一次。我们估计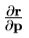 由数字分化。第j列被系统地从移位上典型图像的已知的最佳值的每个参数和计算的残差的加权平均来计算。为了提高测量的估计的鲁棒性,在不同程度的位移残差,
由数字分化。第j列被系统地从移位上典型图像的已知的最佳值的每个参数和计算的残差的加权平均来计算。为了提高测量的估计的鲁棒性,在不同程度的位移残差,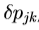 ,被测量(典型地高达0.5标准偏差,
,被测量(典型地高达0.5标准偏差,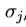 ,对于每个参数,
,对于每个参数,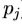 ),并用加权正比于
),并用加权正比于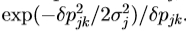 求和。然后,我们预先计算R和与模型中的所有后续搜索使用它。
求和。然后,我们预先计算R和与模型中的所有后续搜索使用它。
在的计算中所使用的图像可以是从使用所述外观模型本身产生的训练集或合成影像的例子。当使用合成的图像,一个可以使用一个合适的(例如,随机的)的背景下,或者可以从模型构建过程检测重叠的背景模型的区域,取出那些像素。后者使得最终的关系更加独立的背景。其中背景是可预测的(例如,医学图像),这是没有必要的。
4.2 迭代模型细化
使用(4),我们可以提出一个校正在基于测量的残余r处的模型参数。这使得我们可以构建我们的解决优化问题的迭代算法。给定模型参数,C,姿势 t,纹理变换 u,并在当前估计的图像样品,的当前估计,迭代过程的一个步骤如下:

1.项目纹理样品放入使用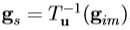 纹理模型框架
纹理模型框架
2.估计误差矢量,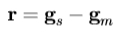 ,和当前误差
,和当前误差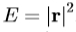
3.计算所预测的位移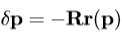
4.更新模型参数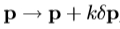 ,最初那里
,最初那里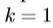
5.计算新点,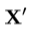 和模框纹理
和模框纹理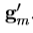 。
。
6.在样本图像以获得一个新的点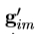 。
。
7.计算新的误差向量,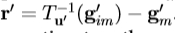 。
。
8.如果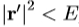 ,新的估计被接受;否则,尝试为
,新的估计被接受;否则,尝试为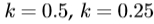 等。
等。
重复这个过程,直到没有改善的错误,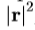 制成,并且假定收敛。在实践中,我们使用了多分辨率的实现,在此我们以粗分辨率开始,遍历每个级别突出当前的解决方案,以模型的一个新的水平之前接轨。这是更有效,更可以从更远不是在一个分辨率搜索收敛到正确的解决方案。该算法的复杂度是在给定的级别
制成,并且假定收敛。在实践中,我们使用了多分辨率的实现,在此我们以粗分辨率开始,遍历每个级别突出当前的解决方案,以模型的一个新的水平之前接轨。这是更有效,更可以从更远不是在一个分辨率搜索收敛到正确的解决方案。该算法的复杂度是在给定的级别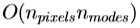 操作。本质上,每个迭代包括采样
操作。本质上,每个迭代包括采样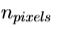 个点从图像然后通过乘以
个点从图像然后通过乘以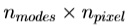 矩阵。
矩阵。
在先前的工作[4],[1]中,我们描述了基于回归对残差矢量随机位移矢量训练算法。因为线性假设制成,在极限这将给与上述相同的结果。然而,在实践中,我们发现上面的方法更快,更可靠。
5 一个主动外观模型FACES

图3:第一模式和位移的权重。
图4:第二模式和位移的权重。
我们采用主动外观模型训练算法在3.1节中描述的人脸模型。矩阵R 的行的元素得到对于给定模型参数每个纹理采样点的权重。图3和图4示出了外观模型的前两个模式和相应的权重的图像。其表现出的模式最大的变化的区域是由训练过程中指派的最大权重。
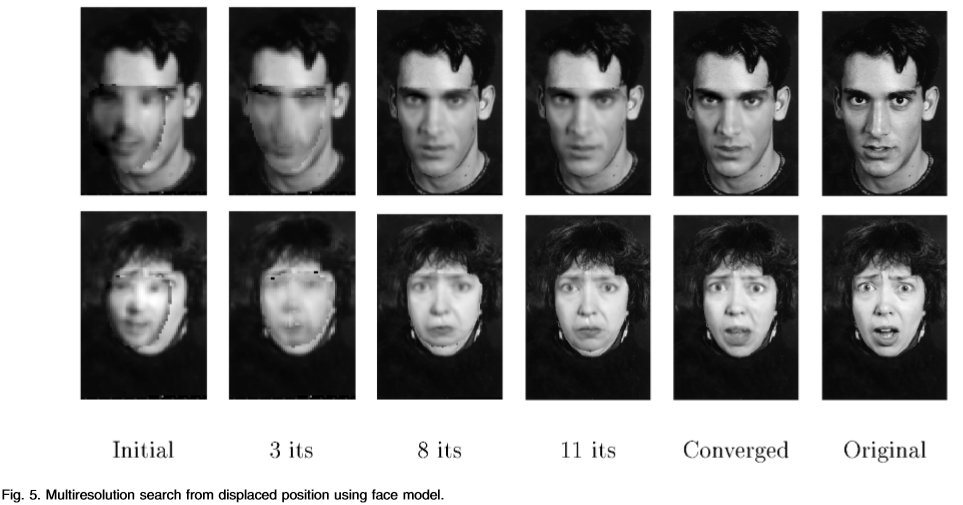
图5:使用脸部模型位移位置的多分辨率搜索。(初始的 融合的 原始的)
我们使用的面部AAM搜索在前所未见的影像面孔。图5示出从一个AAM搜索两个面,每个开始与来自真实面中心偏移的平均模型帧。在每一种情况下,一个好的结果被发现。搜索需要一个400MHz的奔腾Ⅱ代电脑(Pentium II PC)上不到一秒。
6 定量评价
为了获得AAM算法的性能的定量评估,我们培训了100手标记的人脸图像的模型,并测试了一组不同的标记100个的图像。每个面大约200像素宽。各种不同的人,表情都包括在内。该AAM被训练集的前10个影像系统取代模型参数训练。
每一个测试图像上,我们系统地通过在 x 和 y 面宽度的 10% 移位从真实位置的模型,并且通过 10% 的改变了它的规模。然后,我们跑了多分辨率搜索,从平均外观参数。 共运行2700次搜查。这些中,13% 未能收敛到令人满意的结果(平均点的位置误差为每点面宽度的大于5%)。那些没有收敛的,模型点和目标点之间的RMS误差为面宽度的约0.8%。相对于该最佳模型的拟合给出的标记点,在归一化帧中的最终纹理的误差向量的平均量值为0.84(标准差:0.2),这表明该算法定位比由标记提供了更好的结果点。这是可以预料的,因为算法是最小化的质感误差向量,如果这导致纹理匹配的整体改善将危及形状。
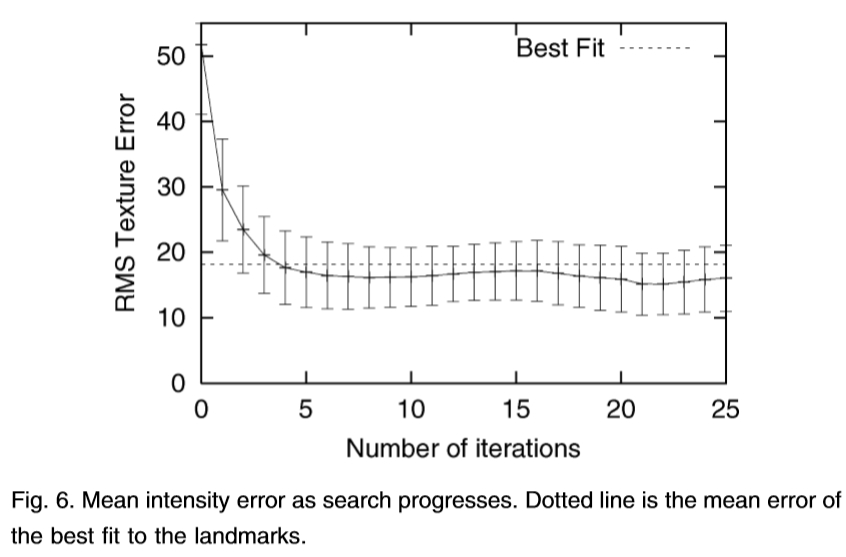
图6:平均强度误差搜索过程。虚线是最适合的标志性建筑的平均误差。
图6示出每个像素的平均强度误差(对于使用256个灰度级的图像)相对于迭代次数,平均超过一组的搜索中的一个单一的分辨率。该模型最初由面部宽度的5%的位移。虚线使用手标记标志点,这表明了良好的结果由搜索获得给出了平均重构误差。

图7:从不同的初始位移收敛搜索的比例。
图7示出的该融合型正确地给定由在 x 和 y 至多50个像素(面宽度的25%)的各种移位的起始位置100个的多分辨率搜索的比例。该模型显示具有最多20个像素(面部宽度的10%)初始位移良好的结果。
7 讨论和结论
我们已经证明了匹配统计外观模型新图像的迭代方案。该方法利用了在模型参数中的差错,并将所得残余纹理误差之间的相关性学习的。给定一个合理的初始起始位置,搜索快速,可靠收敛。该方法是用于定位任何对象类,可以使用上面描述的统计外观模型被充分表示的例子是有价值的。这包括其表现出形状和纹理的变化,其为可对应不同的例子之间定义的对象。例如,不能使用该方法对于像与不同分支的数目的结构树,但可用于表现出形状变化,但在不拓扑改变各种器官。我们已经与脸的图像和与其他域中的医用图像[1],[5],并取得了令人鼓舞的结果广泛的测试方法。虽然 AAM 搜索比主动形状模型搜索[2]稍慢,但是由于使用所有的图像证据,程序往往比单独 ASM 搜索更健壮。
该算法已经为灰度级图像进行了说明,但可简单地通过在每个采样点采样每个颜色被扩展到彩色图像(例如,每个像素的三个值的RGB图像)。搜索算法的性质也使其适于跟踪对象在图像序列,其中可以示出,得到稳定的结果[5]。
致谢
Cootes博士下EPSRC高级奖学金资助。在大部分工作,爱德华博士通过与英国电信研究实验室的EPSRC案例奖资助。
For further information on this or any computing topic, please visit our Digital Library at http://computer.org/publications/dlib.
有关此或进一步信息的任何计算的话题,请访问我们的数字图书馆在 http://computer.org/publications/dlib
参考文献
[1] T.F. Cootes, G.J. Edwards, and C.J. Taylor, "Active Appearance Models," Proc. Fifth European Conf. Computer Vision, H. Burkhardt and B. Neumann, eds., vol. 2, pp. 484-498, 1998.
[2] T.F. Cootes, C.J. Taylor, D. Cooper, and J. Graham, "Active Shape ModelsÐTheir Training and Application," Computer Vision and Image Understanding, vol. 61, no. 1, pp. 38-59, Jan. 1995.
[3] G. Edwards, A. Lanitis, C. Taylor, and T. Cootes, "Statistical Models of Face ImagesÐImproving Specificity," Image and Vision Computing, vol. 16, pp. 203-211, 1998.
[4] G. Edwards, C.J. Taylor, and T.F. Cootes, "Interpreting Face Images Using Active Appearance Models," Proc. Third Int'l Conf. Automatic Face and Gesture Recognition, pp. 300-305, 1998.
[5] G.J. Edwards, C.J. Taylor, and T.F. Cootes, "Face Recognition Using the Active Appearance Model," Proc. Fifth European Conf. Computer Vision, H. Burkhardt and B. Neumann, eds., vol. 2, pp. 581-695, 1998.
[6] T. Ezzat and T. Poggio, "Facial Analysis and Synthesis Using Image-Based Models," Proc. Second Int'l Conf. Automatic Face and Gesture Recognition 1997, pp. 116-121, 1997.
[7] M. Gleicher, "Projective Registration with Difference Decomposition," Proc. IEEE Conf. Computer Vision and Pattern Recognition, 1997.
[8] G. Hager and P. Belhumeur, "Efficient Region Tracking with Parametric Models of Geometry and Illumination," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 20, no. 10, pp. 1025-1039, Oct. 1998.
[9] M.J. Jones and T. Poggio, "Multidimensional Morphable Models: A Framework for Representing and Matching Object Classes," Int'l J. Computer Vision, vol. 2, no. 29, pp. 107-131, 1998.
[10] M. La Cascia, S. Sclaroff, and V. Athitsos, "Fast, Reliable Head Tracking under Varying Illumination: An Approach Based on Registration of Texture Mapped 3D Models," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 22, no. 4, pp. 322-336, Apr. 2000.
[11] A. Lanitis, C.J. Taylor, and T.F. Cootes, "Automatic Interpretation and Coding of Face Images using Flexible Models," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 19, no. 7, pp. 743-756, July 1997.
[12] C. Nastar, B. Moghaddam, and A. Pentland, “Generalized Image Matching: Statistical Learning of Physically-Based Deformations,” Computer Vision and Image Understanding, vol. 65, no. 2, pp. 179-191, 1997.
[13] S. Sclaroff and J. Isidoro, ”Active Blobs,“ Proc. Sixth Int'l Conf. Computer Vision, pp. 1146-1153, 1998.
[14] T. Vetter, “Learning Novel Views to a Single Face Image," Proc. Second Int'l Conf. Automatic Face and Gesture Recognition, pp. 22-27, 1996.