传统工业实时历史数据库与时序数据库的区别?
本文介绍了实时数据库和时序数据库,并就其特点、应用场景、相关厂商、联系与区别做介绍。
实时历史数据库
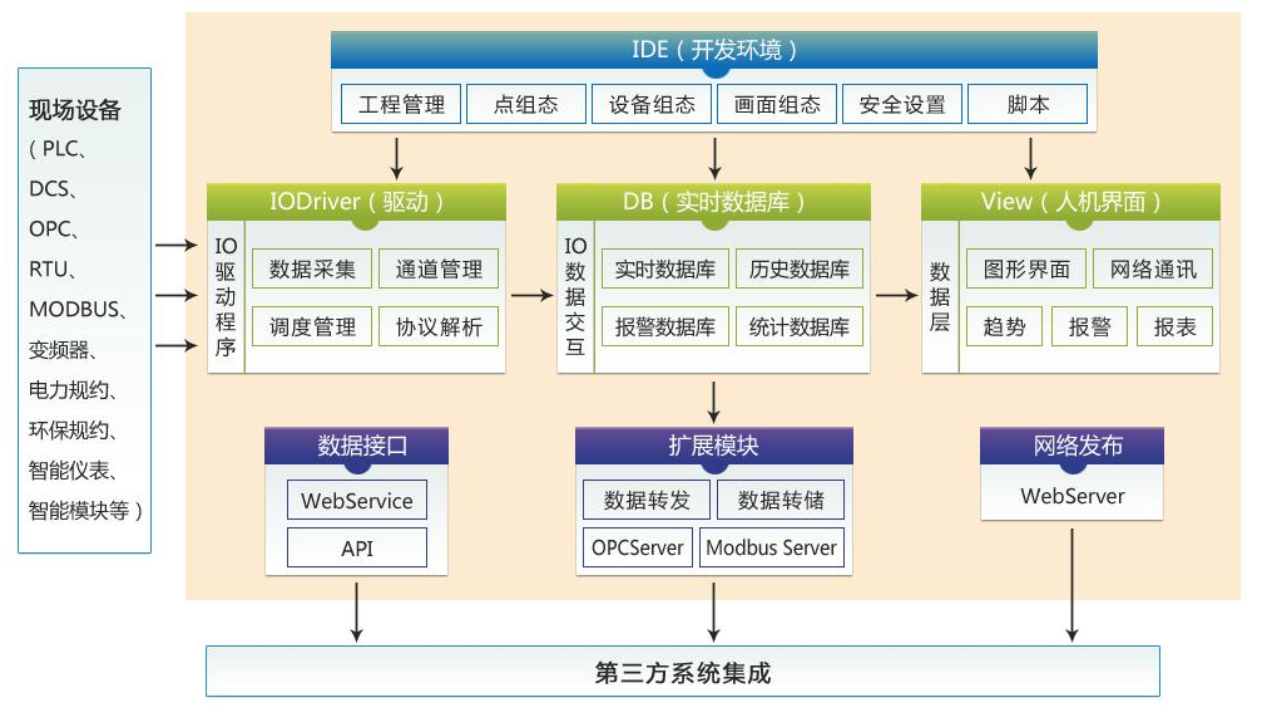
特点
实时数据库诞生于美国,主要是因为现代工业制造流程及大规模工业自动化的发展,导致大量的测量数据需要集成和存储,而采用关系数据库难以满足速度和容量的要求,因此在80年代中期,开始诞生了适用于工业监控领域的实时数据库。
在传统工业控制领域,由于其自身的特殊性,有很多对实时数据处理的要求,特别是在流程工业中,对各个生产环节的监控要求十分苛刻,需要通过监测数据实时反映出系统的状态,所以对于实时数据库的处理十分看重。因此工业实时数据库应运而生,其主要用于工业过程数据的采集、存储以及查询分析,以实现过程状态的实时监控。
实时数据库其实并不单单只是一个数据库,而是一个系统,包括对各类工业接口的数据采集,海量监测数据的压缩、存储及检索,基于监测数据的反馈及控制功能等。
实时数据库的出现,主要是为了解决当时关系型数据库不太擅长的领域,包括:
- 海量数据的实时读写操作
工业监控数据要求采集速度和响应速度均是毫秒级的,一个大型企业几万甚至几十万监测点都是常有的事情,这么大容量的高频数据,如果用关系数据库进行存储,由于关系库本身设计的理念,导致它很难进行每秒几十万的数据的读写操作,而实时数据库通过转为快速读写设计的时标型数据结构、高频缓存等技术,可以实现海量数据的实时读写操作。
- 大容量数据的存储
由于数据采集是海量的监控数据,那么如果用传统数据库进行存储,将会占用大量的存储空间,如果我们用关系数据库保存10000个监测点,每个监测点每秒钟采集一次双精度数的数据,即使不考虑索引等因素,也需要5-6T的存储空间,这里还不包括存储跟监测点相关的时间等因素,如果都包括,再建立索引,则需要15T-20T的存储空间。实时数据库采用了专门的压缩算法,包括哈佛曼算法、旋转门算法以及一些二次压缩算法,压缩比普遍能够达到30:1左右,再加上对于时间及索引的特殊处理,存储量能够缩小到关系库的1/40,因此,上面的例子只需要500G的空间就能够进行有效存储了。
- 集成了工业接口的数据采集
由于历史和垄断的原因,目前工业通讯、传输的协议种类繁多,实时库一般都集成了大量的工业协议接口,可以对各种类型的工业协议进行解析和传输。同时,随着实时数据库的发展,接口软件部分也慢慢被独立出来,即可以与实时数据库核心集中部署在1台计算机上,也可以单独部署在接口机上,从而提供了更好的可扩展性和稳定性。
- 集成控制功能,可实现实时控制
实时数据库一般都提供下行控制接口,并且是高速写出。写的效率严重依赖于接口通讯效率和执行机构。因此,实时数据库大都是从工控软件厂商发展而来的,他们就有丰富的工业控制写入的经验。即便如此,毕竟工业系统对时序有严格的要求,而数据库从读到写,会出现时滞,因此,实时数据库一般不适宜对快速开关量的控制。
应用场景
实时历史数据库主要应用于工业控制领域。工业生产分为两大类:流程型和离散型,流程型以大批量生产为主,离散型往往是多个零件经过一系列不连续的工序的加工为主。
比如:
- total defects for a particular shift(指定班次的总缺陷)
- vibrations of a motor fan on a production line(生产线上电机风扇的振动)
- pH levels for a water treatment plant(水处理厂的 pH 值)
- current speed of a conveyor(传送带的当前速度)
- when a human-entered data event occurred(当发生人为输入的数据事件时)
- total amount of ingredient added to tank(添加到罐中的成分总量)
相关厂商
国内:北京三维力控、亚控、北京和利时、紫金桥
国外:GE iHistorian、OSI PI

时序数据库
时序数据库全称为时间序列数据库。时间序列数据库指主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
时序数据库诞生于互联网,兴起于物联网,主要为了支持海量网络监控及传感器数据的快速写入和分析需求。
应用场景
- 监控软件系统: 虚拟机、容器、服务、应用
- 监控物理系统: 水文监控、制造业工厂中的设备监控、国家安全相关的数据监控、通讯监控、传感器数据、+ 血糖仪、血压变化、心率等
- 资产跟踪应用: 汽车、卡车、物理容器、运货托盘
- 金融交易系统: 传统证券、新兴的加密数字货币
- 事件应用程序: 跟踪用户、客户的交互数据
- 商业智能工具: 跟踪关键指标和业务的总体健康情况
- 在互联网行业中,也有着非常多的时序数据,例如用户访问网站的行为轨迹,应用程序产生的日志数据等等。
相关产品
国外:influxDB、Prometheus、TimescaleDB、Graphite、QuestDB、AWS Timestream、OpenTSDB
国内:TDengine、IoTDB(清华开源)
实时数据库和时序数据库区别
实时数据库的特点:
优势:
- 与工控软件的结合、协议的兼容性好,毕竟发展这么多年,特别是协议有好几百种;
- 实时数据库有成熟的解决方案;从数据采集、传输、压缩存储、数据的展示与分析;
- 运维部署简单;人员易上手,可以相对快速的投入到项目中
局限性:
- 成本高;在项目中,可以看到分各种不同的种类收费,比如测点、网关、服务器;国外的比国内的更高。
- older technology limits scale and analysis(较旧的技术限制了规模和分析)
- difficult to link the data to context(很难将数据与上下文联系起来)
后面这两点,我认为是实时数据库到时序数据库发展的两个重要原因。目前实时数据库里面的数据资源大部分都锁在硬盘里面吃灰,随着大数据、云计算技术的发展,我们想把这部分数据利用起来,就需要提高其扩展性、易用性。
时序数据库特点:
优势:
- 可大规模横向扩展;主要得益于云计算、虚拟化技术的发展,时序数据库几乎可以无限扩展;
- 性能: An open-source database like Influx can handle a thousand more tags than the industry-leading proprietary data historian. And they can do this 10 times faster.(数据测点更多,速度更快,引用的,未验证)
- 易于集成;没啥可说的,本身就是应互联网需求诞生的
- 开源;开源意味着有有一个生态圈,而不是某些厂商垄断、封闭;当然这也是双刃剑(从安全角度考虑)
- 数据处理和分析:可以利用现有的大数据技术,融合多种类型数据,进行分析,辅助决策。
局限性:
- 对于工控行业,发展不如实时数据库成熟;这也有好的发展方向,统一协议不行吗,发展了好几百种协议,层层壁垒,干嘛呢?
- 需要专业运维人员;
另外摘录了网上针对这两者的比较:
- 虽然都注重高速的写入能力,但能力上有差别。
传统工业实时数据库,一般是单节点支持200万以上的数据点、5000并发用户数、数据写入速度高于100万条记录/秒。而时序数据库方面,1000万是目前的单节点性能瓶颈,他的软件优化方向也是侧重写多于读,其平衡了数据的压缩和读写放大,主要采用列存储的方式,吸收了软件行业中新技术的观点。 - 在场景和生态工具方面,二者也有差别
传统的工业实时数据库,其实是一套从数据采集开始到可视化的解决方案,针对工业场景的工具包更为丰富,尤其是对上百种工业协议的支持,以及各个工业场景的数据模型,比如OPC接口OPC是一个标准,用于规定控制系统和数据源的协议)。但时序数据库,其实不仅仅是工业监控场景,在DevOps、IoT、金融等场景下其也有用武之地。 - 在横向扩展性方面工业实时数据库也有一些瓶颈。
传统的实时数据库多是主备的部署架构,通常要求有较高配置的机器,来追求单机极致的性能;同时,在稳定性方面,会对运行软件的稳定性做极高的要求,完全由高质量的代码来保证运行的稳定。但时序数据库的分布式架构,使得系统能够轻松地进行水平扩展,让数据库不再依赖昂贵的硬件和存储设备,以集群天然的优势来实现高可用,不会出现单点的瓶颈或故障,在普通的 x86 服务器甚至是虚拟机上都可以运行,大大降低了使用成本。 - 价格差异明显。
传统的工业实时数据库解决方案价格都十分昂贵,一般只有大型企业能接受。比如美国OSI公司的 PI ( Plant Information System ) 产品,其每个接口就要6000美元,整套产品需要百万美元。相比之下,时序数据库都是开源免费的,更便于大家上手。 - 部署方式的不同
时序数据库更适合上云方向。传统的工业实时数据都会使用私有化部署,机器、软件以及后续的服务是一笔十分高昂的开销,还需要配备专业的技术人员进行系统的维护。随着网络和云计算技术的成熟,相关的性能和安全性不断升级,时序数据库多在拥抱云,更符合大趋势。
智能化煤矿的建设过程中,综合自动化平台这块目前主要用到实时数据库、组态软件等技术架构,原因上面也提到。随着智能化的发展,煤矿上私有云,以后可能出现的国资云,甚至是公有云以及大数据、物联网等技术的运用,时序数据库肯定会得到进一步运用。
参考
实时数据库:一夜之间,我感受到了时序数据库的威胁
时序数据库 VS 工业实时数据库
工业互联网平台的七种武器之时序数据库
2021工业实时数据库行业白皮书
7 Powerful Time-Series Database for Monitoring Solution
数据库排名
Data historians vs time-series: which is better for data analysis
Operational Historians and Time-Series Data Platforms for Digital Transformation
TDengine在华夏天信露天煤矿智慧矿山操作系统的应用https://www.taosdata.com/blog/2022/03/04/4983.html
11 亿条数据压缩到 12 GB,TDengine 在陕煤矿山项目的落地实践https://www.taosdata.com/blog/2022/01/26/4904.html
TDengine在华夏天信露天煤矿智慧矿山操作系统的应用https://www.taosdata.com/blog/2020/06/09/1588.html