第一次数据学习报告
Python操作数据库读书笔记
一、SQLite3 数据库
SQLite3 可使用 sqlite3 模块与 Python 进行集成,一般 python 2.5 以上版本默认自带了sqlite3模块,因此不需要用户另外下载。
在 学习基本语法之前先来了解一下数据库是使用流程吧 ↓↓↓
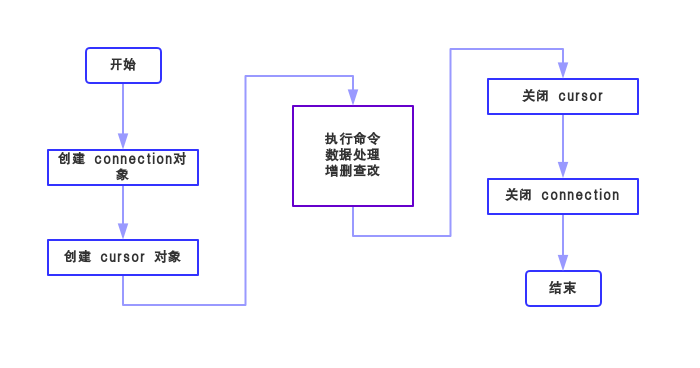
首先要创建一个数据库的连接对象,即connection对象,语法如下:
sqlite3.connect(database [,timeout,其他可选参数])
function: 此API打开与SQLite数据库文件的连接。如果成功打开数据库,则返回一个连接对象。
database: 数据库文件的路径,或 “:memory:” ,后者表示在RAM中创建临时数据库。
timeout: 指定连接在引发异常之前等待锁定消失的时间,默认为5.0(秒)
有了connection对象,就能创建游标对象了,即cursor对象,如下:
connection.cursor([cursorClass])
function: 创建一个游标,返回游标对象,该游标将在Python的整个数据库编程中使用。
接下来,看看connection对象 和 cursor对象的 “技能” 吧 ↓↓↓
| 方法 | 说明 |
| connect.cursor() | 上述,返回游标对象 |
| connect.execute(sql [,parameters]) | 创建中间游标对象执行一个sql命令 |
| connect.executemany(sql [,parameters]) | 创建中间游标对象执行一个sql命令 |
| connect.executescript(sql_script) | 创建中间游标对象, 以脚本的形式执行sql命令 |
| connect.total_changes() | 返回自打开数据库以来,已增删改的行的总数 |
| connect.commit() | 提交当前事务,不使用时为放弃所做的修改,即不保存 |
| connect.rollback() | 回滚自上次调用commit()以来所做的修改,即撤销 |
| connect.close() | 断开数据库连接 |
| 方法 | 说明 |
| cursor.execute(sql [,parameters]) | 执行一个sql命令 |
| cursor.executemany(sql,seq_of_parameters) | 对 seq_of_parameters 中的所有参数或映射执行一个sql命令 |
| cursor.executescript(sql_script) | 以脚本的形式一次执行多个sql命令 |
| cursor.fetchone() | 获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
| cursor.fetchmany([size=cursor.arraysize]) | 获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。size指定特定行数。 |
| cursor.fetchall() | 获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
一、操作数据库读书笔记
SQLite是一种嵌入式数据库,它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用。
1、在使用SQLite前,我们先要搞清楚几个概念:
(1)表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,表和表之间通过外键关联。
(2)要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection;
(3)连接到数据库后,需要打开游标,称之为Cursor,游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联。因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。游标对象有以下的操作:
execute() – 执行sql语句
executemany() – 执行多条sql语句
close() – 关闭游标
fetchone() – 从结果中取一条记录,并将游标指向下一条记录
fetchmany() – 从结果中取多条记录
scroll() – 游标滚动

学号后四位为3022
1 import pandas 2 import sqlite3 3 conn= sqlite3.connect("2015大学排名(22).db") 4 k = pandas.read_csv('2015中国大学排名爬虫.csv',encoding='gbk') 5 k.to_sql('University', conn, if_exists='append', index=False) 6 print('success') 7 conn = sqlite3.connect('2015大学排名(22).db') 8 cur = conn.cursor() 9 cur.execute('SELECT * FROM University') 10 li = cur.fetchall() 11 i=0 12 for line in li: 13 i+=1 14 for item in line: 15 print(item, end=' ') 16 print() 17 if i==192: 18 break 19 conn.close() 20
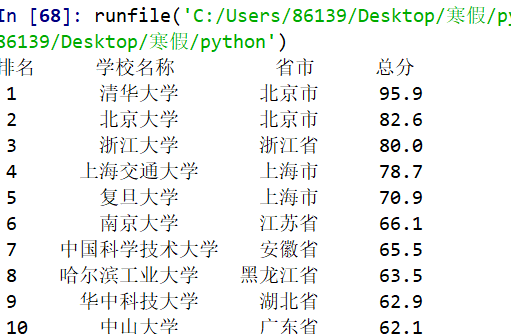
查询广东技术师范大学的大学排名以及培养结果
1 import requests 2 from bs4 import BeautifulSoup 3 allUniv=[] 4 def getHTMLText(url): 5 try: 6 r=requests.get(url,timeout=30) 7 r.raise_for_status() 8 r.encoding = 'utf-8' 9 return r.text 10 except: 11 return "" 12 def fillUnivList(soup): 13 data = soup.find_all('tr') 14 for tr in data: 15 ltd = tr.find_all('td') 16 if len(ltd)==0: 17 continue 18 singleUniv = [] 19 for td in ltd: 20 singleUniv.append(td.string) 21 allUniv.append(singleUniv) 22 def printUnivList(num): 23 a="广东" 24 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养结果")) 25 for i in range(num): 26 u=allUniv[i] 27 #print(u[1]) 28 if a in u: 29 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[5])) 30 def main(): 31 url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' 32 html = getHTMLText(url) 33 soup = BeautifulSoup(html,"html.parser") 34 fillUnivList(soup) 35 num=len(allUniv) 36 printUnivList(num) 37 main()
运行结果

![]()
查询广东技术师范学院的排名和培养结果
1 import requests 2 from bs4 import BeautifulSoup 3 allUniv=[] 4 def getHTMLText(url): 5 try: 6 r=requests.get(url,timeout=30) 7 r.raise_for_status() 8 r.encoding = 'utf-8' 9 return r.text 10 except: 11 return "" 12 def fillUnivList(soup): 13 data = soup.find_all('tr') 14 for tr in data: 15 ltd = tr.find_all('td') 16 if len(ltd)==0: 17 continue 18 singleUniv = [] 19 for td in ltd: 20 singleUniv.append(td.string) 21 allUniv.append(singleUniv) 22 def printUnivList(num): 23 a="广东技术师范学院" 24 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养结果")) 25 for i in range(num): 26 u=allUniv[i] 27 #print(u[1]) 28 if a in u: 29 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[5])) 30 def main(): 31 url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html' 32 html = getHTMLText(url) 33 soup = BeautifulSoup(html,"html.parser") 34 fillUnivList(soup) 35 num=len(allUniv) 36 printUnivList(num) 37 main()
运行结果
