左偏树能干什么?它支持(O(logn))完成插入,删除,查询最值,合并。
看到前三个我们想到堆(优先队列),所以左偏树是可并堆的一种。
说到可并堆,主要有左偏树,配对堆,二项堆,斐波那契堆等几种。而(OI)界主要使用前两种,主要是好写的缘故。
配对堆似乎是一种比左偏树时间复杂度及常数更小且代码复杂度略小的可并堆,而左偏树的优势则是可持久化。
闲话说完了,左偏树长什么样子?有什么性质?
先放一张百度百科的图解。
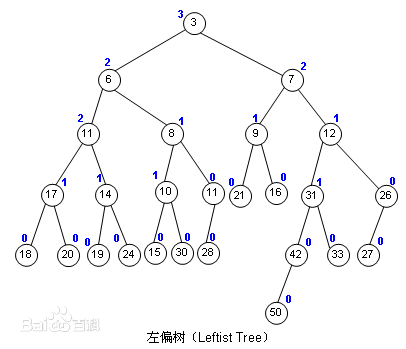
一个左偏树的节点有两个权值,一个为键值(val)满足二叉堆的性质,另一个为距离(dis)满足左偏性质。
键值不解释,那么距离是什么?
定义外节点为左、右儿子有任一者为空节点的节点
一个点的距离,即是该节点到最近的外节点的距离。
不明白的看看图解就懂了。
那距离满足什么性质?
即左偏性质。
看上去和上面的一个意思,但这条推论很有用。
不过这个左偏性质看起来并不强,左子树一个点右子树一条长链似乎也满足左偏性质。那么复杂度如何保证呢?看另一条推论:
这个也很好证明。设距离为(d),若左偏树为完全二叉树,则(n=2^{d+1}-1),等价于(d=log_2(n+1)-1),如果左偏树不为二叉堆,显然(d)更小,该推论得证。
考虑几种操作(默认为大根堆)
merge
最重要的一个操作,但很好完成。
两棵左偏树(x, y),令(val_xgeq val_y)(不满足就交换)。
递归合并(rs_x, y),并把合并的信息记在(rs_x)上。
此时已保证堆的性质,为保证左偏性质,令(dis_xgeq dis_y)(不满足就交换)。
分析一下复杂度,可以看出每次操作(dis_x+dis_y)减(1),又有(dis_x+dis_y=log(size_x)+log(size_y)-2),所以一次操作复杂度为(O(logn))
这个比较重要,放一下代码
int Merge(int x, int y)
{
if (!x || !y) return x | y;
if (val[x] < val[y]) swap(x, y);
rs[x] = Merge(rs[x], y);
if (dis[ls[x]] < dis[rs[x]]) swap(ls[x], rs[x]);
dis[x] = dis[rs[x]] + 1;
return x;
}
find
取左偏树顶的值即可,复杂度(O(1))
insert
把一个节点(即一个节点构成的左偏树)与一棵左偏树合并,复杂度(O(logn))
delete
将根节点的左右儿子合并,复杂度(O(logn))
int Delete(int x){return Merge(ls[x], rs[x]);}
build
这个(O(nlogn))插入即可,好像有(O(n))的方法,但是我不会。
所以最重要也最常用的是(merge)和(delete)两种操作
注意这道题要维护每个数所在集合,用并查集维护。(市面上很多题解说不能路径压缩,我不是很能理解,不用不就(O(nm))了吗)
#include<cstdio>
#include<algorithm>
#define rep(i, a, b) for (register int i=(a); i<=(b); ++i)
#define per(i, a, b) for (register int i=(a); i>=(b); --i)
using namespace std;
const int N=100005;
int rt[N], ls[N], rs[N], val[N], dis[N];
inline int read()
{
int x=0,f=1;char ch=getchar();
for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1;
for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0';
return x*f;
}
int find(int x){return x==rt[x]?x:rt[x]=find(rt[x]);}
int Merge(int x, int y)
{
if (!x || !y) return x|y;
if (val[x]>val[y] || (val[x]==val[y] && x>y)) swap(x, y);
rs[x]=Merge(rs[x], y);
if (dis[ls[x]]<dis[rs[x]]) swap(ls[x], rs[x]);
rt[x]=rt[ls[x]]=rt[rs[x]]=x; dis[x]=dis[rs[x]]+1;
return x;
}
int Delete(int x)
{
val[x]=-1;
rt[ls[x]]=ls[x]; rt[rs[x]]=rs[x];
rt[x]=Merge(ls[x], rs[x]);
}
int main()
{
int n=read(), m=read(); dis[0]=-1;
rep(i, 1, n) rt[i]=i, val[i]=read();
rep(i, 1, m)
{
int opt=read(), x=read();
if (opt==1)
{
int y=read();
if ((!~val[x]) || (!~val[y])) continue;
int fx=find(x), fy=find(y);
if (fx^fy) rt[fx]=rt[fy]=Merge(fx, fy);
}
else
{
if (!~val[x]) puts("-1");
else printf("%d
", val[find(x)]), Delete(find(x));
}
}
return 0;
}
这题多一个插入操作,写起来也差不多。
#include<cstdio>
#include<cstring>
#include<algorithm>
#define rep(i, a, b) for (register int i=(a); i<=(b); ++i)
#define per(i, a, b) for (register int i=(a); i>=(b); --i)
using namespace std;
const int N=100005;
int rt[N], ls[N], rs[N], val[N], dis[N];
inline int read()
{
int x=0,f=1;char ch=getchar();
for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1;
for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0';
return x*f;
}
int find(int x){return x==rt[x]?x:rt[x]=find(rt[x]);}
int Merge(int x, int y)
{
if (!x || !y) return x|y;
if (val[x]<val[y]) swap(x, y);
rs[x]=Merge(rs[x], y); rt[rs[x]]=x;
if (dis[ls[x]]<dis[rs[x]]) swap(ls[x], rs[x]);
dis[x]=dis[rs[x]]+1;
return x;
}
int Delete(int x)
{
int l=ls[x], r=rs[x];
rt[l]=l; rt[r]=r; ls[x]=rs[x]=dis[x]=0;
return Merge(l, r);
}
int main()
{
int n;
while (scanf("%d", &n)==1)
{
memset(ls, 0, sizeof(ls));
memset(rs, 0, sizeof(rs));
memset(dis, 0, sizeof(dis)); dis[0]=-1;
rep(i, 1, n) rt[i]=i, val[i]=read();
int m=read();
rep(i, 1, m)
{
int x=read(), y=read();
int fx=find(x), fy=find(y), u, v;
if (fx==fy) {puts("-1"); continue;}
val[fx]>>=1; u=Delete(fx); u=Merge(u, fx);
val[fy]>>=1; v=Delete(fy); v=Merge(v, fy);
printf("%d
", val[Merge(u, v)]);
}
}
return 0;
}
对每个节点维护一个左偏树,处理节点时将儿子节点的左偏树合并过来,如果薪水总值(> m),删除左偏树中(c_i)最大值直到(leq m)为止,然后更新答案。插入,删除,合并的次数都为(n),所以复杂度为(O(nlogn))。
#include<cstdio>
#include<vector>
#include<algorithm>
#define rep(i, a, b) for (register int i=(a); i<=(b); ++i)
#define per(i, a, b) for (register int i=(a); i>=(b); --i)
using namespace std;
const int N=100005;
int dis[N], size[N], c[N], l[N], ls[N], rs[N], rt, n, m;
long long sum[N], ans;
vector<int> G[N];
inline int read()
{
int x=0,f=1;char ch=getchar();
for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1;
for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0';
return x*f;
}
int Merge(int x, int y)
{
if (!x || !y) return x|y;
if (c[x]<c[y]) swap(x, y);
rs[x]=Merge(rs[x], y);
if (dis[ls[x]]<dis[rs[x]]) swap(ls[x], rs[x]);
dis[x]=dis[rs[x]]+1;
return x;
}
int Delete(int x){return Merge(ls[x], rs[x]);}
int dfs(int u)
{
int now=u;
sum[u]=c[u]; size[u]=1;
for (int v: G[u])
{
int nxt=dfs(v); now=Merge(now, nxt);
sum[u]+=sum[v]; size[u]+=size[v];
}//先全部合并
while (sum[u]>m) sum[u]-=c[now], size[u]--, now=Delete(now);//贪心删去多余的
ans=max(ans, 1ll*size[u]*l[u]);
return now;
}
int main()
{
n=read(); m=read(); dis[0]=-1;
rep(i, 1, n)
{
int f=read();
if (f) G[f].push_back(i); else rt=i;
c[i]=read(); l[i]=read();
}
dfs(rt);
printf("%lld
", ans);
return 0;
}
求递增序列不太好求,等价于把(a_i-i)后求非降序列。
考虑简单的情况
若(a_1<a_2<dots<a_n),则(b_i=a_i)
若(a_1>a_2>dots>a_n),则(b_i=a_{frac{n}{2}})
所有的数列可以分为若干个递增或递减的段,考虑如何合并答案,对于前后两段,若(b_lleq b_r),无需修改,若(b_l>b_r),需要合并前后两部分答案并取中位数。
求中位数的方法在这道题,用堆维护。
回到本题,需要合并的中位数用可并堆即左偏树维护即可。
#include<cstdio>
#include<algorithm>
#define rep(i, a, b) for (register int i=(a); i<=(b); ++i)
#define per(i, a, b) for (register int i=(a); i>=(b); --i)
using namespace std;
const int N=1000005;
int ls[N], rs[N], dis[N], rt[N], size[N], l[N], r[N];
long long val[N], a[N], b[N], ans;
inline int read()
{
int x=0,f=1;char ch=getchar();
for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1;
for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0';
return x*f;
}
int Merge(int x, int y)
{
if (!x || !y) return x|y;
if (a[x]<a[y] || (a[x]==a[y] && x>y)) swap(x, y);
rs[x]=Merge(rs[x], y);
if (dis[ls[x]]<dis[rs[x]]) swap(ls[x], rs[x]);
dis[x]=dis[rs[x]]+1;
return x;
}
int Delete(int x){return Merge(ls[x], rs[x]);}
int main()
{
int n=read(), j=0; dis[0]=-1;
rep(i, 1, n) a[i]=read()-i;
rep(i, 1, n)
{
j++; rt[j]=l[j]=r[j]=i;
size[j]=1; val[j]=a[i];
while (j>1 && val[j]<val[j-1])
{
j--; rt[j]=Merge(rt[j], rt[j+1]);
size[j]+=size[j+1]; r[j]=r[j+1];
while ((size[j]<<1)>r[j]-l[j]+2)
size[j]--, rt[j]=Delete(rt[j]);
val[j]=a[rt[j]];
}//处理下降的情况
}
rep(i, 1, j) rep(k, l[i], r[i])
b[k]=val[i], ans+=abs(a[k]-b[k]);
printf("%lld
", ans);
rep(i, 1, n) printf("%lld ", b[i]+i);
return 0;
}
我当然不会这样的神题,所以都是抄网上题解的
设(f_x)为以(x)为根的子树中叶子距离皆为(x)的最小代价,它是一个下凸函数,并且每一段是一个一次函数。
设([L,R])为一段斜率为(0)且包含最低点的区间,考虑(son)到(x)(边权为(w))的转移
描述一下就是([0,L])上移(w),([L,R])右移(w),中间插一段斜率为(-1)的线段,右边补上一段斜率为(1)的线段。
然后(x)将所有(son)的函数值叠加,因为每个函数斜率都是(-1->0->1),所以最后得到的函数值有若干个拐点,且每个拐点斜率(+1)。
要求最后的值,我们先需要求(f_0)。显然(f_0=sum_{win subtree}w),(w)值边权。
然后我们需要知道拐点的横坐标,我们对每个点开一个左偏树,然后合并,注意每个点只要保存斜率(leq 0)的位置即可。
#include <cstdio>
#include <algorithm>
#define rep(i, a, b) for (register int i = (a); i <= (b); ++i)
#define per(i, a, b) for (register int i = (a); i >= (b); --i)
using namespace std;
const int N=600005;
int rt[N], ls[N], rs[N], dis[N], deg[N], w[N], fa[N], n, m, tot;
long long sum, val[N];
int Merge(int x, int y)
{
if (!x || !y) return x | y;
if (val[x] < val[y]) swap(x, y);
rs[x] = Merge(rs[x], y);
if (dis[ls[x]] < dis[rs[x]]) swap(ls[x], rs[x]);
dis[x] = dis[rs[x]] + 1;
return x;
}
int Delete(int x){return Merge(ls[x], rs[x]);}
inline int read()
{
int x = 0, f = 1; char ch = getchar();
for (; ch < '0' || ch > '9'; ch = getchar()) if (ch == '-') f = -1;
for (; ch >= '0' && ch <= '9'; ch = getchar()) x = (x << 1) + (x << 3) + ch - '0';
return x * f;
}
int main()
{
int n = read(), m = read();
rep(i, 2, n + m) deg[fa[i] = read()]++, sum += w[i] = read();
per(i, n + m, 2)
{
long long L = 0, R = 0;//斜率为0的区间
if (i <= n)
{
while (--deg[i]) rt[i] = Delete(rt[i]);//注意到函数最右端的斜率为儿子个数,所以弹出儿子的个数次即可。
L = val[rt[i]]; rt[i] = Delete(rt[i]);
R = val[rt[i]]; rt[i] = Delete(rt[i]);
}
val[++tot] = L + w[i]; val[++tot] = R + w[i];
rt[i] = Merge(rt[i], Merge(tot, tot-1));
rt[fa[i]] = Merge(rt[fa[i]], rt[i]);
}
while (deg[1]--) rt[1] = Delete(rt[1]);
while (rt[1]) sum -= val[rt[1]], rt[1] = Delete(rt[1]);
printf("%lld
", sum);
return 0;
}
这题似乎可以用堆(+)启发式合并做,不过这不在本文的讨论范围内。
骑士从下往上聚集,每次(<h)的删除,这种操作很容易想到可并堆。不过这次又加法和乘法操作,肯定不能对所有元素直接做,打个标记然后(pushdown)一下就行了。
#pragma GCC optimize (2)
#include<cstdio>
#include<vector>
#include<algorithm>
#define int long long
#define rep(i, a, b) for (register int i=(a); i<=(b); ++i)
#define per(i, a, b) for (register int i=(a); i>=(b); --i)
using namespace std;
const int N=300005;
vector<int> G[N];
int v[N], c[N], a[N], m[N], ans[N], num[N], dep[N], h[N], n, q;
int rt[N], ls[N], rs[N], dis[N], mul[N], add[N];
inline int read()
{
int x=0,f=1;char ch=getchar();
for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1;
for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0';
return x*f;
}
void upd(int a,int b,int c){if(a)v[a]*=b,v[a]+=c,mul[a]*=b,(add[a]*=b)+=c;}
void pushdown(int x)
{
upd(ls[x], mul[x], add[x]);
upd(rs[x], mul[x], add[x]);
mul[x]=1; add[x]=0;
}
int Merge(int x, int y)
{
if (!x || !y) return x | y;
pushdown(x); pushdown(y);
if (v[x] > v[y]) swap(x, y);
rs[x] = Merge(rs[x], y);
if (dis[ls[x]] < dis[rs[x]]) swap(ls[x], rs[x]);
dis[x]=dis[rs[x]]+1;
return x;
}
int Delete(int x){return Merge(ls[x], rs[x]);}
void dfs(int u)
{
for (int v: G[u]) dep[v]=dep[u]+1, dfs(v), rt[u]=Merge(rt[u], rt[v]);
while (rt[u] && h[u]>v[rt[u]])
{
pushdown(rt[u]);
ans[u]++; num[rt[u]]=dep[c[rt[u]]]-dep[u];
rt[u]=Delete(rt[u]);
}
if (a[u]) upd(rt[u], m[u], 0);
else upd(rt[u], 1, m[u]);
}
signed main()
{
n=read(); q=read(); dis[0]=-1;
rep(i, 1, n) h[i]=read();
rep(i, 2, n) G[read()].push_back(i), a[i]=read(), m[i]=read();
rep(i, 1, q) v[i]=read(), c[i]=read(), mul[i]=1, rt[c[i]]=Merge(rt[c[i]], i);
dep[1]=1; dfs(1);
while (rt[1]) pushdown(rt[1]), num[rt[1]]=dep[c[rt[1]]], rt[1]=Delete(rt[1]);
rep(i, 1, n) printf("%lld
", ans[i]);
rep(i, 1, q) printf("%lld
", num[i]);
return 0;
}