(1)、环境准备
requests + pymongo 库
(2)、页面分析
首先登录拉钩并输入关键字:爬虫工程师
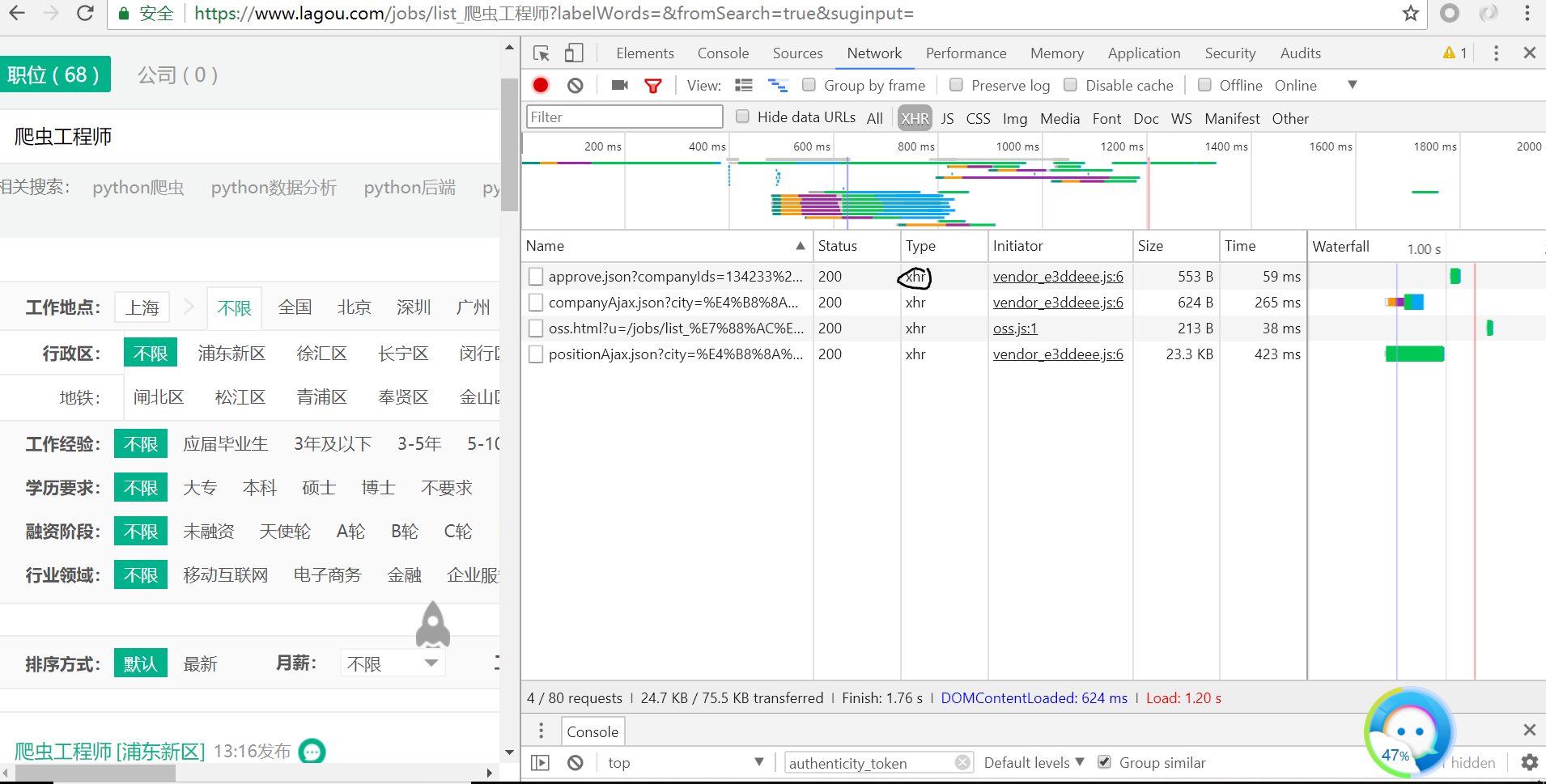
我们可以发现这些数据都是js加载的
接着打开chrome的开发者工具选项并勾选XHR

我们发现我们需要的信息包含在result中
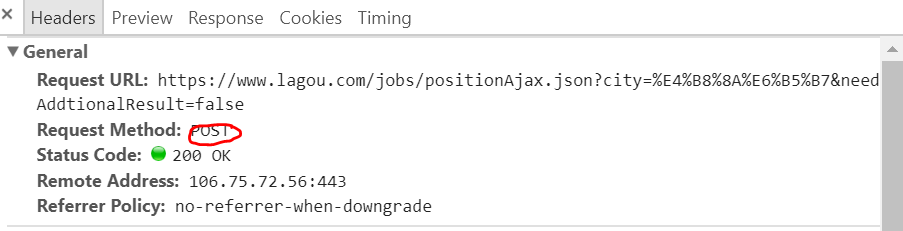
我们通过观察发现该请求为post请求

最后我们需要模拟该请求获取数据
(3)、代码实现
1 #author: "xian" 2 #date: 2018/5/29 3 import time 4 from pymongo import MongoClient 5 import requests 6 from fake_useragent import UserAgent #提供User-Agent的库 7 8 9 client = MongoClient() 10 db = client.lagou #链接test数据库,没有则自动创建 11 my_set = db.job2 #使用set集合,没有自动创建 12 13 ua = UserAgent() #初始化 14 15 url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false' 16 17 headers = { 18 'Cookies':'WEBTJ-ID=20180529193719-163abb02b0d71e-0a6a4200015d64-39614807-921600-163abb02b0f975; _ga=GA1.2.1134699470.1527593839; _gid=GA1.2.774560940.1527593839; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527593839; user_trace_token=20180529193719-a4f52e51-6334-11e8-b37e-525400f775ce; LGSID=20180529193719-a4f53070-6334-11e8-b37e-525400f775ce; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fs%3Fie%3Dutf-8%26f%3D8%26rsv_bp%3D0%26rsv_idx%3D1%26tn%3Dbaidu%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26rsv_pq%3D85d8099500018bc0%26rsv_t%3D08dcbrFGEAkrdozpbP9VW5IPYZ%252FKdnnU6DckaBTAZPPDI9zjjeFH4jkR3Lk%26rqlang%3Dcn%26rsv_enter%3D1%26rsv_sug3%3D11%26rsv_sug1%3D13%26rsv_sug7%3D100; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpt_baidu_pc; LGUID=20180529193719-a4f5323c-6334-11e8-b37e-525400f775ce; X_HTTP_TOKEN=d9c4fe4fb6df7a49db968f666c1e2bcd; _putrc=17CC21EA917C179E123F89F2B170EADC; JSESSIONID=ABAAABAAAGFABEFCDA862BCEB8F11FB3B97530AAA468C39; login=true; unick=%E9%99%86%E6%99%BA%E8%B4%A4; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; gate_login_token=a5d16c416fb70f73c1c1190d6c2443500230225d67aef0a0a2e0df73094566cd; index_location_city=%E4%B8%8A%E6%B5%B7; SEARCH_ID=995bf702a0534ef496cbb491ff7875be; _gat=1; LGRID=20180529194050-22d3aa6d-6335-11e8-b380-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1527594051; TG-TRACK-CODE=search_code', 19 'User-Agent':ua.random, 20 'Referer': 'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=', 21 #拉钩网对Referer提出了限制 22 23 } 24 25 def get_job_info(page,keyword): 26 for i in range(page): 27 payload = { 28 'first': 'true', 29 'pn': i, 30 'kd': keyword, 31 32 } 33 34 response = requests.get(url, data = payload , headers = headers) 35 36 if response.status_code == 200: 37 time.sleep(2) 38 print("正在爬取%s页!" %(i+1)) 39 my_set.insert(response.json()['content']['positionResult']['result']) #爬取content positionResult result字段信息 40 else: 41 print('爬取失败!') 42 43 if __name__ in '__main__': 44 get_job_info(5,'爬虫工程师')
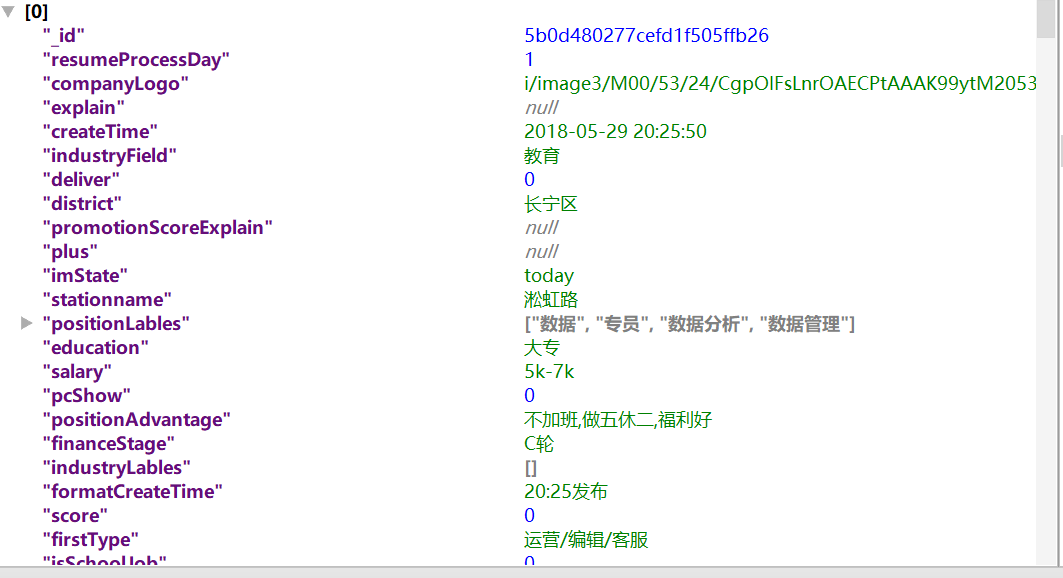
(4)、效果展示