一、英文词频统计
1.下载一首英文的歌词或文章
We all know that environment is so important to ourselves and our future generations.
Natural resources have been depleted in an unprecedented scale.
The environment has been polluted in a way that never happened before.
It is certain that the world and all the living organism on it are going straight to hell.
But why those in power, no matter how loud they speak out environmental protection, very few of them really care. The reason is simple. Human beings are greedy in nature. In ancient times, technology is lacking, human beings did not have the right tool to exploit the nature on large scale. With industrial revolution and the development of science and technology, these things can be achieved with relative ease. It can be said that the development of science can be a gospel and a curse on human race at the same time. It is more than certain that the world is going straight to hell. Climate change comes at an unprecedented rate. We can see all the polar ice sheet melt in our own lifetime. Cities by the sea will be flooded. Summer will get unbearably hot. Almost all the natural resources will be depleted. It is not that world leaders are unaware of this , but because of their greed no one is able to put the interest of the general public and future generations over their own pride. Development sounds an untouchable truth. Anything that comes in its way will be neglected. One thing that we never ponder is that the space and resources on this planet is limited which means that the raw material and space for development is also limited. Now matter how great and intelligent human beings might be, we have our own weakness.
The more intelligent a creature is, the more physically vulnerable it is.
With the worsening of the living environment, one can rarely predict that how many of us will eventually survive this unprecedented change. It is time for us to think whether we should live in a more environmentally friendly manner so that our offsprings will also have space and resources to live with or we just pamper ourselves to the extreme and forget about our future generation and the human race at large.
2.将所有,.?!’:等分隔符全部替换为空格
sep = ''':.,?!'''
for i in sep:
article = article.replace(i,' ');
3.将所有大写转换为小写
article = article.lower();
4.生成单词列表
article_list = article.split(); print(article_list);
5.生成词频统计
# # ①统计,遍历集合
# article_dict={}
# article_set =set(article_list)-exclude# 清除重复的部分
# for w in article_set:
# article_dict[w] = article_list.count(w)
# # 遍历字典
# for w in article_dict:
# print(w,article_dict[w])
#方法②,遍历列表
article_dict={}
for w in article_list:
article_dict[w] = article_dict.get(w,0)+1
# 排除不要的单词
for w in exclude:
del (article_dict[w]);
for w in article_dict:
print(w,article_dict[w])
6.排序
dictList = list(article_dict.items()) dictList.sort(key=lambda x:x[1],reverse=True);
7.排除语法型词汇,代词、冠词、连词
exclude = {'the','to','is','and'}
for w in exclude:
del (article_dict[w]);
8.输出词频最大TOP20
for i in range(20):
print(dictList[i])
9.将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
file = open("test.txt", "r",encoding='utf-8');
article = file.read();
file.close()
二、中文词频统计,下载一长篇中文文章。
代码:
import jieba
#打开文件
file = open("gzccnews.txt",'r',encoding="utf-8")
notes = file.read();
file.close();
#替换标点符号
sep = ''':。,?!;∶ ...“”'''
for i in sep:
notes = notes.replace(i,' ');
notes_list = list(jieba.cut(notes));
#排除单词
exclude =[' ','
','你','我','他','和','但','了','的','来','是','去','在','上','高']
#方法②,遍历列表
notes_dict={}
for w in notes_list:
notes_dict[w] = notes_dict.get(w,0)+1
# 排除不要的单词
for w in exclude:
del (notes_dict[w]);
for w in notes_dict:
print(w,notes_dict[w])
# 降序排序
dictList = list(notes_dict.items())
dictList.sort(key=lambda x:x[1],reverse=True);
print(dictList)
#输出词频最大TOP20
for i in range(20):
print(dictList[i])
#把结果存放到文件里
outfile = open("top20.txt","a")
for i in range(20):
outfile.write(dictList[i][0]+" "+str(dictList[i][1])+"
")
outfile.close();
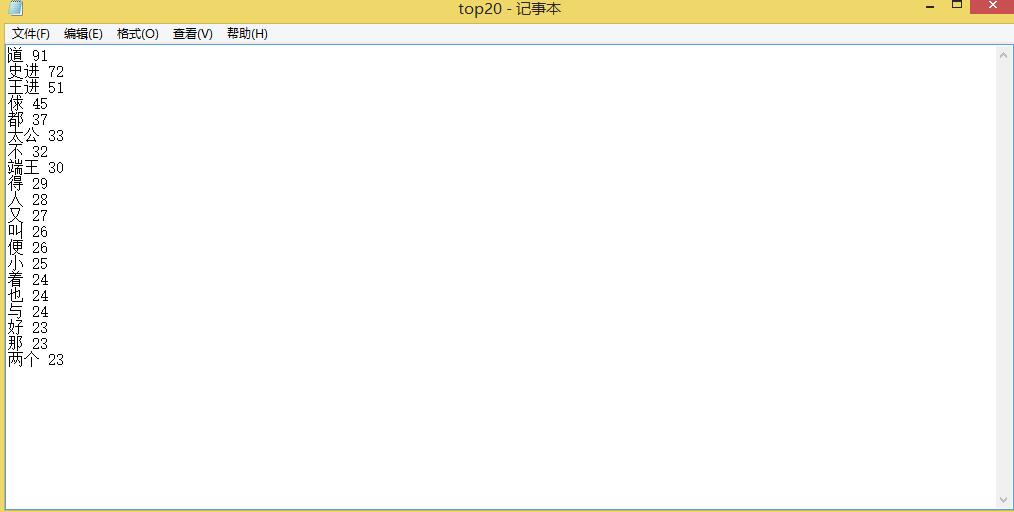
截图:
把文章转化为字典:

排序,输出Top20

写入文件: