20145238 《信息安全系统设计基础》第9周学习总结
教材学习内容总结
第十章知识点总结
(一)Unix I/O
Unix I/O:简单低级的应用接口,使所有输入输出都以统一的方式执行。
- 打开文件。一个应用程序通过要求内核打开相应文件,来宣告它想要访问一个I/O设备,内核返回描述符(小的非负整数)。每个进程开始时都有三个打开的文件:标准输入(描述符为0)、标准输出(描述符为1)、标准错误(描述符为2)。
- 改变当前的文件位置。每个打开的文件内核保持着一个文件位置k,初始为0。
- 读写文件。读操作就是从文件拷贝n>0个字节到存储器,从当前文件位置k开始将k增加到k+n。
- 关闭文件。将描述符恢复到可用的描述池中。
(二)打开和关闭文件
1.open:进程通过调用open函数来打开一个已存在的文件或创建一个新文件。
`#include<sys/types.h>
include<sys/stat.h>
include<fcntl.h>`
int open(char *filename, int flags, mode_t mode);
返回:若成功则为新文件描述符,若出错则为-1。
open函数将filename转换为一个文件描述符,并返回描述符数字。返回的描述符是在进程中当前没有打开的最小描述符。
flags参数指明进程打算如何访问这个文件:
- O_RDONLY:只读
- O_WRONLY:只写
- O_RDWR:可读可写
以只读的方式打开一个已存在的文件:fd = Open("foo.txt, O_RDONLY, 0")
打开一个已存在的文件,并在后面添加一些数据:fd = Open("foo.txt, O_WRONLY|O_APPEND, 0")
2.close:进程通过调用close函数关闭一个打开的文件。
#include<unistd.h> int close(int fd);
返回:若成功则为0,若出错则为-1。
关闭一个已关闭的描述符会出错。
(三)读和写文件
1.read和write函数:应用程序通过分别调用read和write函数来执行输入和输出。
#include<unistd.h> ssize_t read(int fd, void *buf, size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错则为-1。
ssize_t write(int fd, const void *buf, size_t n);
返回:若成功则为写的字节数,若出错则为-1。
- read函数从描述符为fd的当前位置拷贝最多n个字节到存储器位置buf。
- write函数从存储器位置buf拷贝至多n个字节到描述符fd的当前文件位置。
注:"csapp.h"是《深入理解计算机系统》这本书写的头文件,运行代码时需要将该头文件下载并移到/usr/include中。
2.ssize_ t 和 size_t 的区别
- size_t:read函数的输入参数,定义为unsigned int
- ssize_t:read函数的返回值,定义为int。因为出错时必须返回-1。
(四)用RIO包健壮地读写
1.RIO包:自动处理不足值,提供两类不同的函数
- 无缓冲的输入输出函数:直接在存储器和文件之间传送数据。
- 带缓冲的输入函数:高效地从文件中读取文本行和二进制数据。
2.RIO的无缓冲的输入输出函数
- 应用程序通过调用rio_ readn和rio_ writen函数可以在存储器和文件之间直接传送数据。
#include"csapp.h" ssize_ t rio_ readn(int fd, void *usrbuf, size_t n); ssize_ t rio_ writen(int fd, void *usrbuf, size_t n);
返回:若成功则为传送的字节数,若EOF则为0(只对rio_ readn而言),若出错则为-1。
rio_ readn函数从描述符fd的当前文件位置最多传送n个字节到存储器位置usrbuf。rio_ writen函数从存储器位置usrbuf传送n个字节到描述符fd。
3.RIO的带缓冲的输入函数**
-
一个文本行就是一个由换行符结尾的ASCII码字符序列。
-
调用包装函数rio_ readlineb,从一个内部读缓冲区拷贝一个文本行,当缓冲区变空时会自动调用read重新填满缓冲区。
#include"csapp.h" void rio_ readlineb(rio_t *rp, int fd); ssize_ t rio_ readlineb(rio_t *rp, void *usrbuf, size_t maxlen); ssize_ t rio_ readnb(rio_t *rp, void *usrbuf, size_t n);
返回:若成功则为读的字节数,若EOF则为0,若出错则为-1。
- rio_ readlineb函数从文件rp读出一个文本行(包括结尾的换行符),将它拷贝到存储器位置usrbuf,并用空(零)字符结束这个文本行。rio_ readlineb函数最多读maxlen-1个字节,余下一个字符留给结尾的空字符。
- rio_ readnb函数从文件rp最多读n个字节到存储器位置usrbuf。对同一描述符,对rio_ readlineb和rio_ readnb的调用可以任意交叉进行。
(五)读取文件元数据
1.元数据 应用程序能通过调用stat和fstat函数检索到关于文件的信息。
`#include<unistd.h>
include<sys/stat.h>
int stat(const char *filename, struct stat *buf);
int fstat(int fd, struct stat *buf);`
返回:若成功则为0,若出错则为-1。
2.tat数据结构成员:st_ mode、st_ size……
st_ size成员包含了文件的字节数大小,st_ mode成员编码了文件访问许可位和文件类型。
(六)共享文件
** 内核用三个相关的数据结构来表示打开的文件**:
- 描述符表
- 文件表
- v-node表
多个描述符可以通过不同的文件表表项来引用同一个文件。每个描述符都有它自己的文件位置,所以对不同描述符的读操作可以从文件的不同位置获取数据。
调用fork后,子进程有一个父进程描述符表的副本,共享相同的文件位置。在内核删除相应文件表项之前,父子进程必须都关闭它们的描述符。
(七)I/O重定向
I/O重定向操作符:允许用户将磁盘文件和标准输入输出联系起来。I/O重定向可使用dup2函数工作。
#include<unistd.h> int dup2(int oldfd, int newfd);
返回:若成功则为非负的描述符,若出错则为-1。
dup2函数拷贝描述符表表项oldfd到描述符表表项newfd,覆盖描述符表表项newfd以前的内容。如果newfd已经打开了,dup2会在拷贝oldfd之前关闭newfd。
(八)标准I/O
- 标准I/O库提供打开和关闭文件的函数(fopen和fclose)、读和写字节的函数(fread和fwrite)、读和写字符串的函数(fgets和fputs),以及复杂的格式化的I/O函数(scanf和printf)。
(九)错误处理
- 错误处理包装函数
定义:给定某个基本的系统级函数foo,定义一个有相同参数、只不过开头字母大写的包装函数Foo。包装函数调用基本函数并检查错误。如果包装函数发现错误,则打印一条信息并终止进程。否则它返回到调用者。
- Unix系统中的错误处理
三种风格:
- Unix风格的错误处理:遇到错误返回-1,成功则返回有用的结果。
- Posix风格的错误处理:只用返回值来表明成功(0)或者失败(非0)
- DNS风格的错误处理:失败时返回NULL指针,并设置全局变量h_errno
- 错误处理包装函数
- Unix风格:
pid_t Wait(int *status)
{
pid_t pid;
if(pid = wait(status)<0)
unix_error("wait error");
return pid;
}
- Posix风格:
void Pthread_detach(pthread_t tid)
{
int rc;
if(rc=pthread_detach(tid) != 0)
posix_error(rc,"Pthread_detach error");
}
- DNS风格:
struct hostent *Gethostbyname(const char *name)
{
struct hostname *p;
if((p = gethostbyname(name)) == NULL)
dns_error("Gethostbyname error");
return p;
}
教材学习中的问题和解决过程
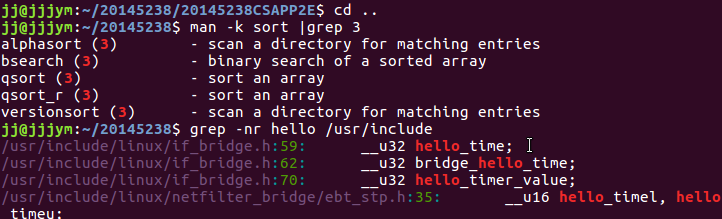
- 关于grep -nr xxx /usr/include 命令的使用
grep -nr 这条语句可以用来查找关键字,全文搜索,并且可以直接查找文件内的内容
- 使用man -k sort | grep 3,可以查找C语言的标准函数库
代码调试中的问题和解决过程
问题:调试习题10.1的时候按照书上的代码,出错:找不到csapp.h

- 解决:看了同学的博客发现为了exit(0)能正常运行,要添加”stdlib.h”,此外还要将open所需的头文件加上,不然会返回出错。
之后解决了
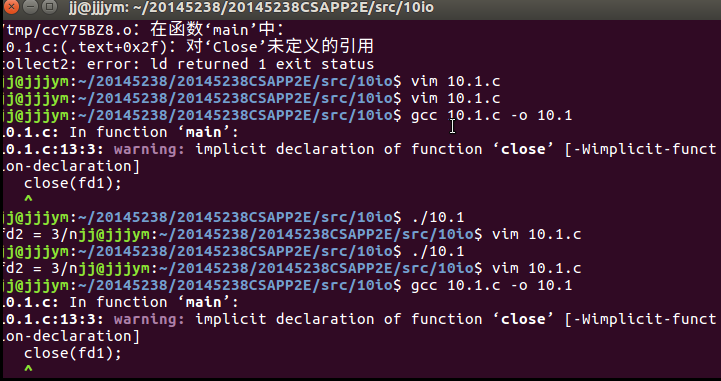
- 上图的这个警告还是没有解决,但可以成功运行了。

本周代码托管截图
其他(感悟、思考等,可选)
本周虚拟机崩了...重新安装了虚拟机,以及重新建立了git链接,有了以前的失败经历这次从虚拟机的安装到git的建立链接都非常的顺畅,只是偶尔有一点小问题,翻阅以前的博客都可以解决。我觉得自己出现问题通过搜索引擎,捕捉到自己的需要的知识这种能力非常重要,拥有了这种方式自我解决问题的能力就会提高的很快,同时也能自强自己的自信心,不至于下一次问题来到无从解决。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 | |
| 第五周 | 500/1000 | 3/12 | 22/120 | |
| 第六周 | 100/1300 | 2/15 | 30/150 | |
| 第七周 | 500/1000 | 3/18 | 22/180 | |
| 第八周 | 100/1500 | 2/20 | 30/210 | |
| 第九周 | 500/1600 | 2/22 | 32/242 |
参考资料
- 《深入理解计算机系统V2》学习指导
- ...