os.walk()递归获取文件,深度优先查找
path = "D:lmj_work_file标注数据Annotationim" def get_inner_files(arg): count_round = 0 for root, dirs, files in os.walk(arg): # print("root>>", root, type(root)) # 这里打印的是根目录,因为是递归查找文件夹,所以每次循环的根目录不一样 # print("dirs>>", dirs, type(dirs)) # 这里打印的是root下面的文件目录名称,仅限一级目录下的文件夹名称,返回值是列表 print("list iterable files>>", [os.path.join(root, name)for name in files], " ") # 打印当前文件路径 print("files>>", files, type(files), " ") # root下的文件名,返回值是列表 # for i in dirs: # print("each dir>>>", i) count_round += 1 # 循环的次数,由嵌套的层级决定。 print(count_round) get_inner_files(path)
执行结果如下:

list iterable files>> ['D:\lmj_work_file\标注数据\Annotation\im\15311153701.xml', 'D:\lmj_work_file\标注数据\Annotation\im\_1A_2_20170615124904411I.xml'] files>> ['15311153701.xml', '_1A_2_20170615124904411I.xml'] <class 'list'> list iterable files>> ['D:\lmj_work_file\标注数据\Annotation\im\新建文件夹\_1A_1_20170523210544357I.xml'] files>> ['_1A_1_20170523210544357I.xml'] <class 'list'> list iterable files>> ['D:\lmj_work_file\标注数据\Annotation\im\新建文件夹\inner_two\_1A_2_20170518113348657I.xml'] files>> ['_1A_2_20170518113348657I.xml'] <class 'list'> list iterable files>> ['D:\lmj_work_file\标注数据\Annotation\im\新建文件夹\inner_two\inner_three\_1A_2_20170616123652362I.xml'] files>> ['_1A_2_20170616123652362I.xml'] <class 'list'> list iterable files>> ['D:\lmj_work_file\标注数据\Annotation\im\新建文件夹 (2)\_1A_1_20170621180306149I.xml'] files>> ['_1A_1_20170621180306149I.xml'] <class 'list'> 5
先在“新建文件夹”下一层一层找下去,找完之后再返回到根目录下找下一个分支,循环的层数跟文件夹数量保持一致。
文件的操作,读,写,只读只写,或者可读同时可写,追加写,以二进制的方式读,以二进制的方式写,以二进制的方式追加。
思维导图:
给你一个文件路径,从中找出所有的文件,方法如下:

# 方法一:(面试要求不使用os.walk) def print_directory_contents(sPath): import os for sChild in os.listdir(sPath): sChildPath = os.path.join(sPath, sChild) if os.path.isdir(sChildPath): print_directory_contents(sChildPath) else: print(sChildPath) # 方法二:(使用os.walk) def print_directory_contents(sPath): import os for root, _, filenames in os.walk(sPath): for filename in filenames: print(os.path.abspath(os.path.join(root, filename))) print_directory_contents('.')
老师的笔记:
内存 存不长久
硬盘 数据储存的持久化
文件操作 —— 数据持久化储存的一种
全栈开发:框架类
初识文件操作:


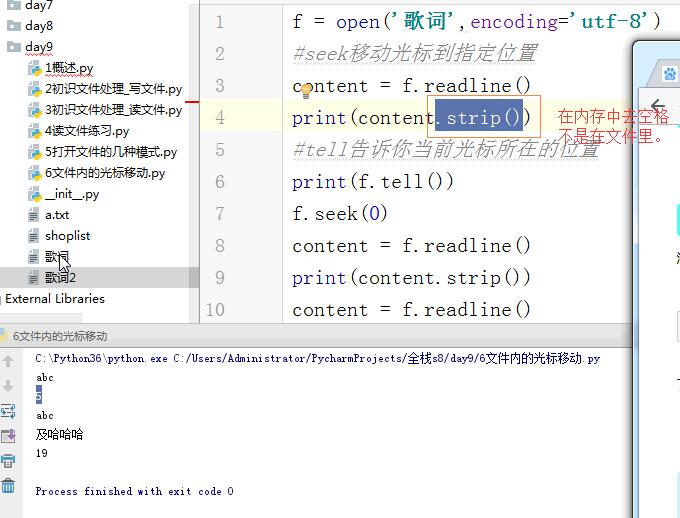
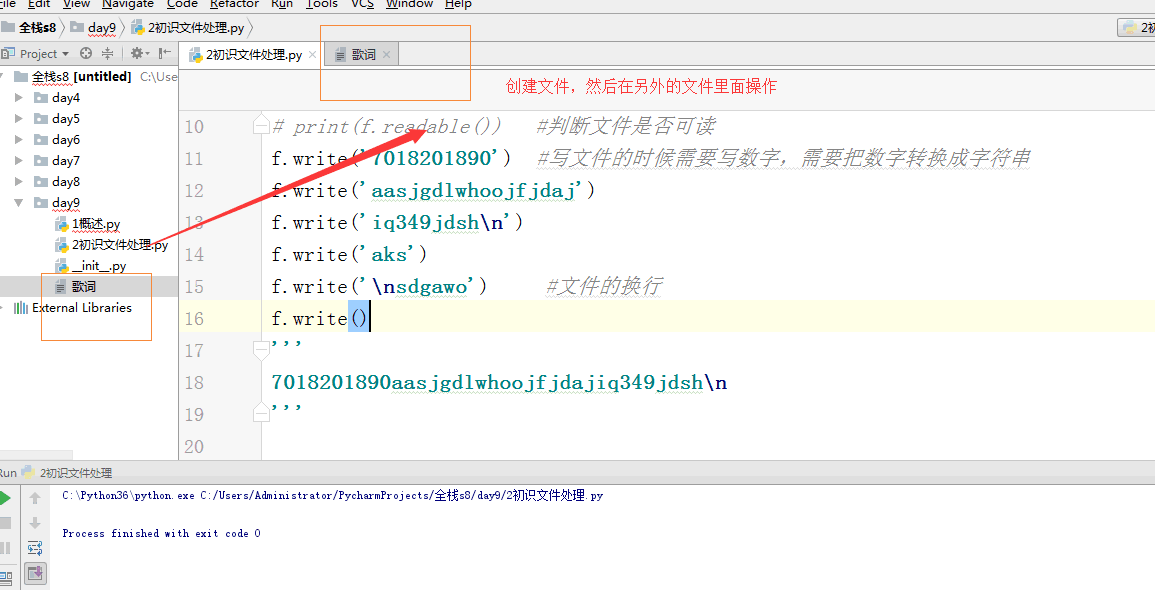
1 #找到文件 2 #打开文件 3 #操作:读 写 4 #关闭 5 f = open('歌词','w',encoding='utf-8') #f:文件操作符 文件句柄 文件操作对象 6 f.write('7018201890') 7 f.close() 8 #open打开文件是依赖了操作系统的提供的途径 9 #操作系统有自己的编码,open在打开文件的时候默认使用操作系统的编码 10 #win gbk mac/linux utf-8 11 12 #习惯叫 f file f_obj f_handler fh 13 # print(f.writable()) #判断文件是否可写 14 # print(f.readable()) #判断文件是否可读 15 # f.write('7018201890') #写文件的时候需要写数字,需要把数字转换成字符串 16 # f.write('aasjgdlwhoojfjdaj') 17 # f.write('iq349jdsh ') 18 # f.write('aks') 19 # f.write(' sdgawo') #文件的换行 20 # f.write('志强德胜') #utf-8 unicode gbk 21 f.close() 22 23 24 #找到文件详解:文件与py的执行文件在相同路径下,直接用文件的名字就可以打开文件 25 #文件与py的执行文件不在相同路径下,用绝对路径找到文件 26 #文件的路径,需要用取消转译的方式来表示:1.\ 2.r'' 27 #如果以写文件的方式打开一个文件,那么不存在的文件会被创建,存在的文件之前的内容会被清空 28 ' \n' 29 f = open(r'C:UsersAdministratorDesktops8_tmp.txt','w',encoding='utf-8') #文件路径、操作模式、编码 30 f.write('哈哈哈') 31 f.close() 32 33 #关闭文件详解
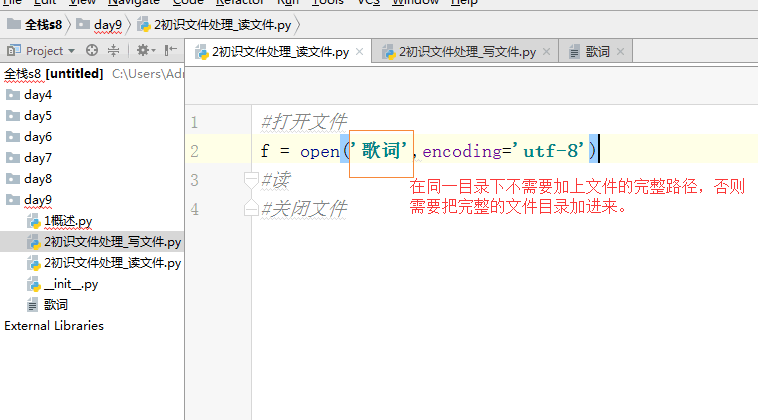
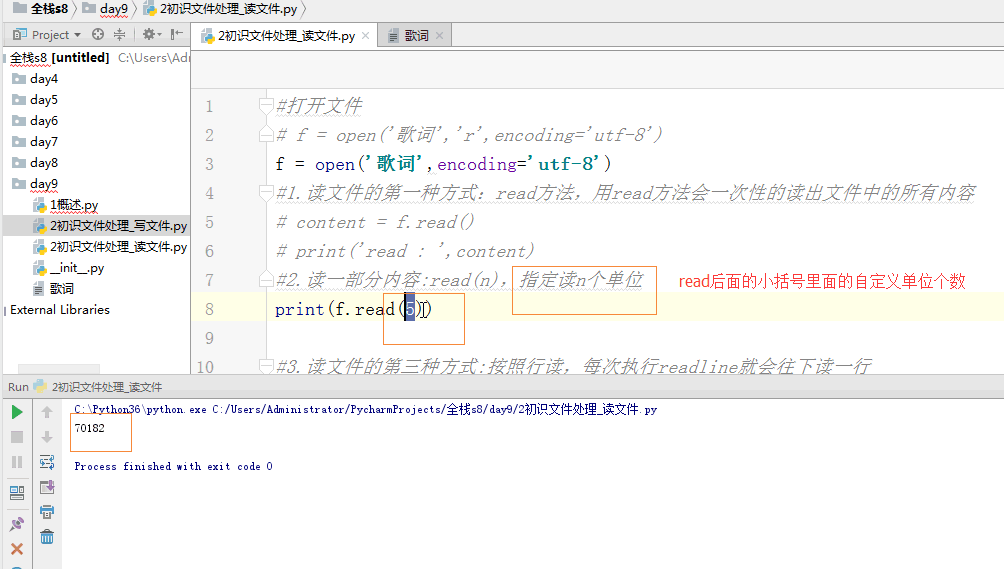
1 #打开文件 2 # f = open('歌词','r',encoding='utf-8') 3 f = open('歌词',encoding='utf-8') 4 #1.读文件的第一种方式:read方法,用read方法会一次性的读出文件中的所有内容 5 # content = f.read() 6 # print('read : ',content) 7 #2.读一部分内容:read(n),指定读n个单位 8 # print(f.read(5)) 9 10 #3.读文件的第三种方式:按照行读,每次执行readline就会往下读一行 11 # content = f.readline() 12 13 # print('readline : ',content.strip()) #strip去掉空格、制表符、换行符 14 # content2 = f.readline() 15 # print(content2.strip()) 16 17 # print(1) #--> 1 18 # print('1 ') #--> 1 19 20 #4.读文件的第四种方式:readlines,返回一个列表,将文件中的每一行作为列表中的每一项返回一个列表 21 # content = f.readlines() 22 # print('readlines : ',content) 23 24 #5.读:最常用 25 for l in f: 26 print(l.strip()) 27 28 #关闭文件 29 f.close()
课堂练习:此练习只有后半部分,前半部分需要创建一个文件,里面要存储一些内容,然后用这个练习的方法把内容打印出来,按照一定的格式的方式。
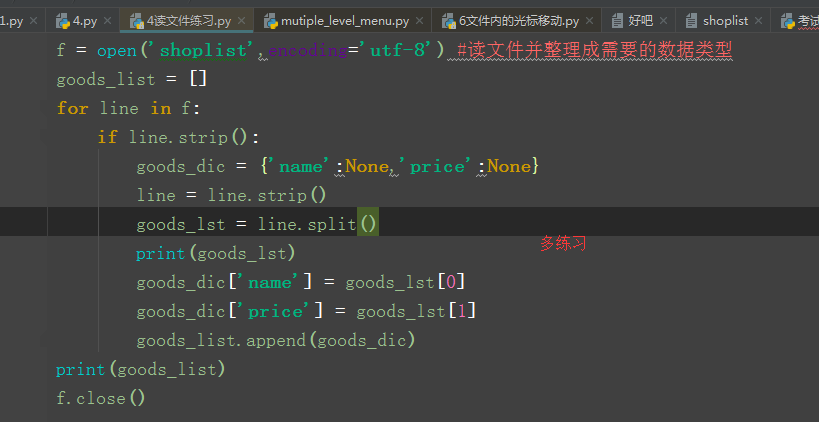
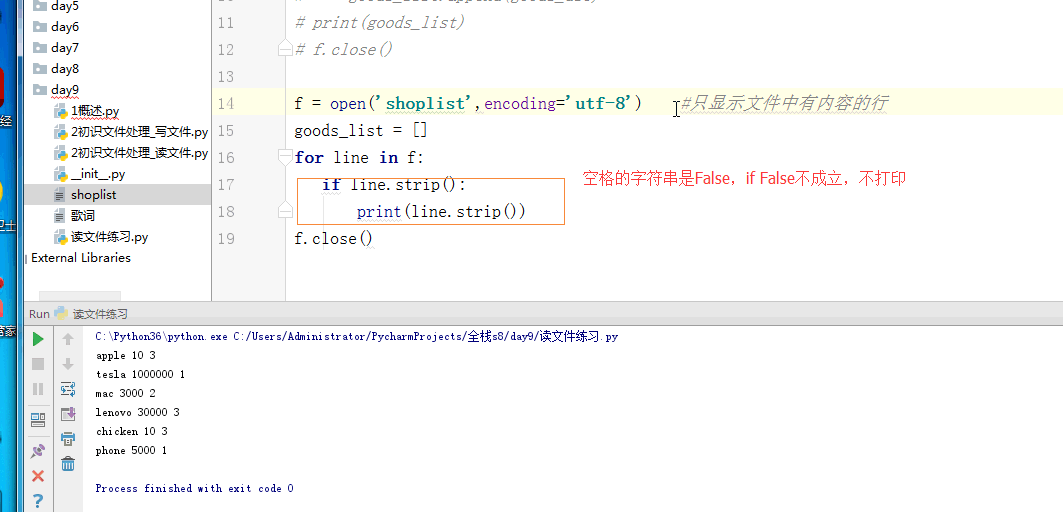
1 f = open('shoplist',encoding='utf-8') #读文件并整理成需要的数据类型 2 goods_list = [] 3 for line in f: 4 if line.strip(): 5 goods_dic = {'name':None,'price':None} 6 line = line.strip() 7 goods_lst = line.split() 8 print(goods_lst) 9 goods_dic['name'] = goods_lst[0] 10 goods_dic['price'] = goods_lst[1] 11 goods_list.append(goods_dic) 12 print(goods_list) 13 f.close() 14 15 f = open('shoplist',encoding='utf-8') #只显示文件中有内容的行 16 goods_list = [] 17 for line in f: 18 if line.strip(): 19 print(line.strip()) 20 f.close()
打开文件的方式:
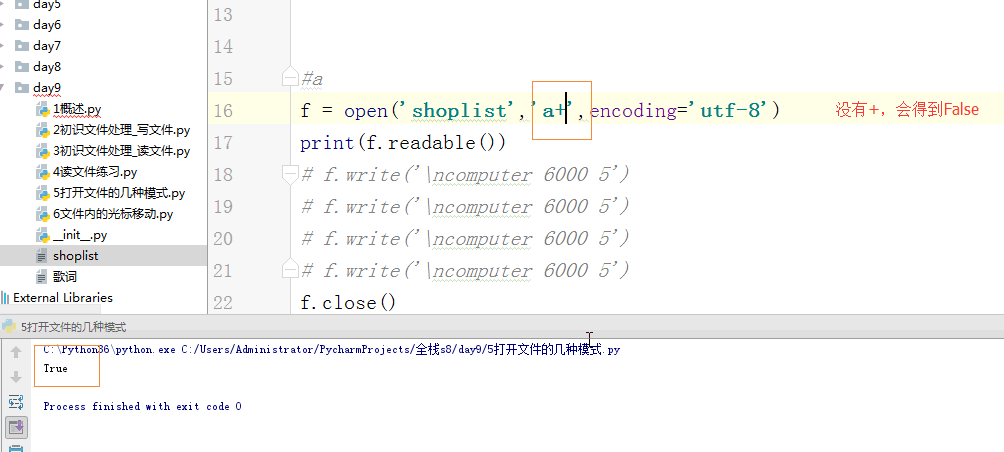
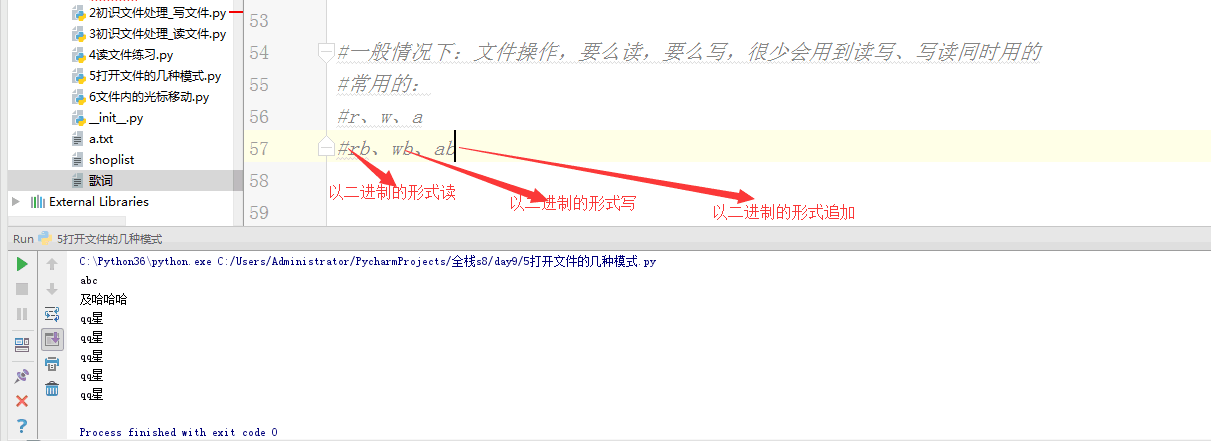
1 # f = open('歌词','rb') 2 # f.close() 3 #b:图片、音乐、视频等任何文件 4 #传输:上传、下载 5 #网络编程: 6 7 #修改文件的编码——非常不重要,不重要程度五颗星 8 #utf-8 用utf8的方式打开一个文件 9 #读文件里的内容str 10 #将读出来的内容转换成gbk 11 #以gbk的方式打开另一个文件 12 #写入 13 14 15 #a+ 16 # f = open('shoplist','a+',encoding='utf-8') 17 # print(f.readable()) 18 # f.write(' computer 6000 5') 19 # f.write(' computer 6000 5') 20 # f.write(' computer 6000 5') 21 # f.write(' computer 6000 5') 22 # f.close() 23 24 25 #1.被动接受知识 - 主动提出问题 26 #2.主动的找到问题,并且找到对应的解决方法 27 #3.主动的学习 28 29 # r+ 可读可写: 30 #1.先读后写:写是追写 31 #2.先写后读:从头开始写 32 # f = open('歌词','r+',encoding='utf-8') 33 # # line = f.readline() 34 # # print(line) 35 # f.write('0000') 36 # f.close() 37 # w+ 可写可读:一上来文件就清空了, 38 # 尽管可读:1.但是你读出来的内容是你这次打开文件新写入的 39 # 2.光标在最后,需要主动移动光标才可读 40 # f = open('歌词','w+',encoding='utf-8') 41 # f.write('abc ') 42 # f.write('及哈哈哈') 43 # f.seek(0) 44 # print(f.read()) 45 # f.close() 46 # a+ 追加可读 47 # f = open('歌词','a+',encoding='utf-8') 48 # f.write(' qq星') 49 # f.seek(0) 50 # print(f.read()) 51 # f.close() 52 53 54 #一般情况下:文件操作,要么读,要么写,很少会用到读写、写读同时用的 55 #常用的: 56 #r、w、a 57 #rb、wb、ab,不需要指定编码了 58 59 f = open('歌词','rb') 60 content = f.read() 61 f.close() 62 print(content) 63 f2 = open('歌词2','wb') 64 f2.write(content) 65 f2.close()
文件内的光标操作:
1 f = open('歌词','r+',encoding='utf-8') 2 #seek 光标移动到第几个字节的位置 3 # f.seek(0) 移动到最开始 4 # f.seek(0,2) 移动到最末尾 5 f.truncate(3) #从文件开始的位置只保留指定字节的内容 6 # f.write('我可写了啊') 7 #tell 告诉我光标在第几个字节 8 #seek移动光标到指定位置 9 # content = f.readline() 10 # print(content.strip()) 11 #tell告诉你当前光标所在的位置 12 # print(f.tell()) 13 # f.seek(4) #光标移动到三个字节的地方‘ ’ 14 # content = f.read(1) #读一个字符 15 # print('***',content,'***') 16 # content = f.readline() 17 # print(content.strip()) 18 # print(f.tell()) 19 f.close() 20 21 22 23 #tell 24 #seek:去最开始、去最结尾 25 #truncate:保留n个字节 26 27 #文件的修改 28 #文件的删除 29 30 #购物车的商品都写在文件里,完成文件的解析之后再写购物车作业
如下是课堂内容的截图:


 绝对路径就是文件的保存路径,查找方法就是点击该文件然后点击右键,点击属性即可查到。
绝对路径就是文件的保存路径,查找方法就是点击该文件然后点击右键,点击属性即可查到。

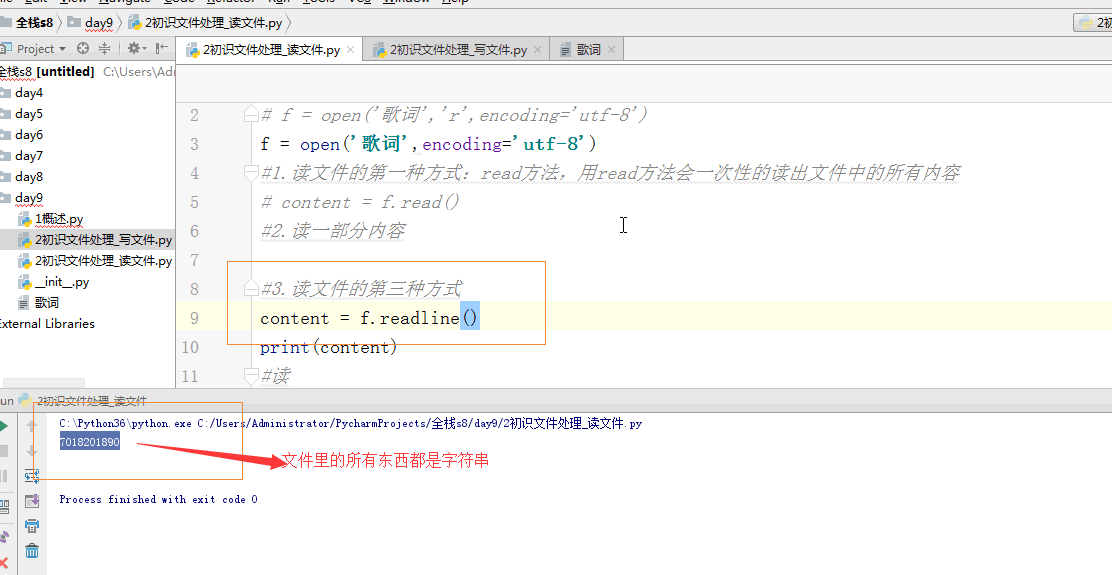

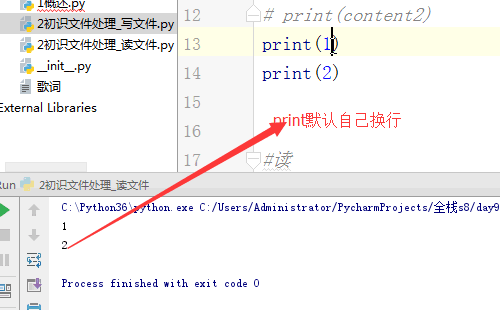
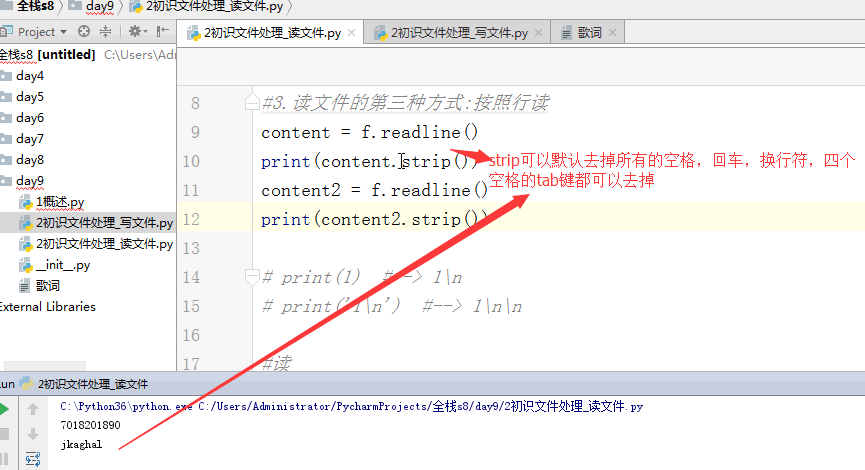


一个 回车键占两个单位,一个单位是一个字符


f=open('shoplist',encoding'utf-8')这一句中没有r,也没有w,因为如果不写‘r,w’默认就是‘读’
下图中的if line.strip():这句话翻译过来就是:line.strip()如果字符串就是空的,那么就等于False,if False是不成立的,不会打印。如果文件中有空格的时候这句话的作用就是遇到空格直接掠过,不读取该空格。