C++函数重载的原理
一、函数重载概述
1.1 为什么要有函数重载
- 在实际的开发中,有时候我们需要实现几个功能类似的函数,只是有些细节不同。例如希望交换两个变量的值,但是这两个变量可能有多种类型:int、char、double、bool等。在C语言中,程序员往往需要分别设计出多个不同名的函数,但是在C++中,这完全没有必要。C++允许多个函数拥有相同的名字,只要它们的参数列表不同就可以,这就是函数的重载。借助函数重载,一个函数名就可以有多种用途。
1.2 构成函数重载的条件
- 函数名相同
- 参数列表不同(即:参数个数不同/参数类型不同/参数顺序不同)
1.3 实例
- 如下swap()函数即可构成函数重载:
#include <iostream>
using namespace std;
void swap(int &v1,int &v2) {
int temp = v1;
v1 = v2;
v2 = temp;
}
void swap(char &v1, char &v2) {
char temp = v1;
v1 = v2;
v2 = temp;
}
int main() {
int a = 1, b = 2;
swap(a, b);
cout << "a=" << a << ",b=" << b << endl;
char c = 'q', d = 'w';
swap(c, d);
cout << "c=" << c << ",d=" << d << endl;
return 0;
}
1.4 注意
-
函数的返回值类型与函数重载无关。
- 如下代码便不构成函数重载
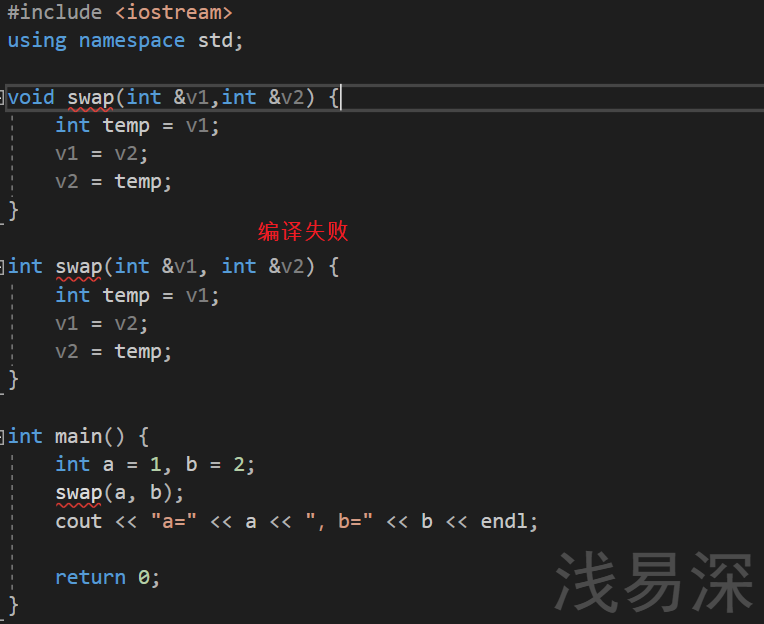
- 如下代码便不构成函数重载
-
调用函数时,实参的隐式类型转换可能会产生二义性。
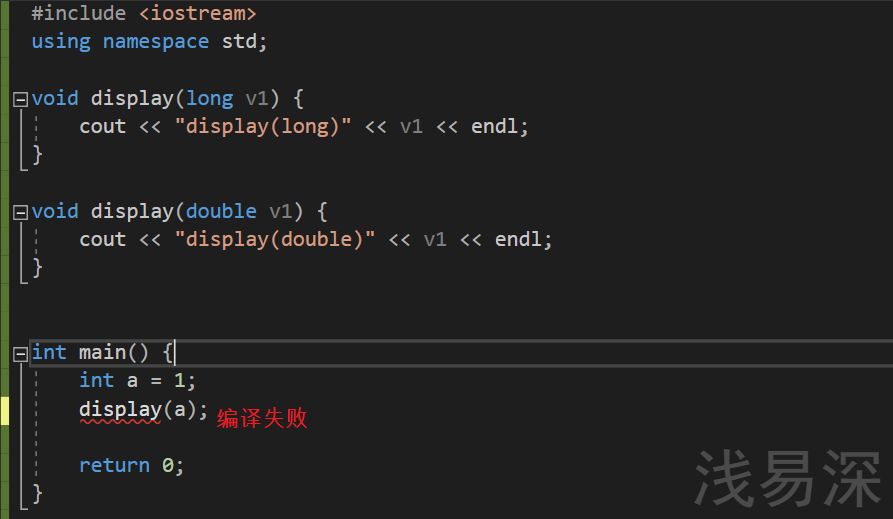
- 如下代码便会因此产生二义性
- 在下面的代码中,main函数调用了display函数,传入的实参为int类型的变量,但是代码中所定义的display函数的形参类型只有long类型和double类型,因此编译器想要匹配成功的话,就必须进行数据类型的隐式转换,但是int类型既可以隐式转换成long类型,也可以隐式转换成double类型,所以就导致编译器不知道要调用以哪个函数,从而造成了二义性,导致编译失败。
二、函数重载的实现原理
2.1 概述
- C++代码在编译时会根据参数列表对函数名进行命重名(该技术被官方称为:name mangling),例如 void swap(int v1, int v2)会被重命名为 _swapii ,void swap(char v1,char v2)会被重命名为 _swapcc(不同的编译器会有不同的重命名规范,这里仅仅举例说明,实际情况可能并非如此)。当发生函数调用时,系统便会根据这些被重新命名的函数名去调用相应的函数。
- 因此从这个角度来讲,函数重载仅仅是语法层面上的,本质上它们还是不同的函数,占用不同的内存,入口地址也不一样。
2.2 证明
- 实验环境:
- windows10 64位
- Visual Studio 2017 社区版
- 我们先创建一个FunctionOverload.cpp源文件,文件中的代码如下所示:
#include <iostream>
using namespace std;
void display(int v1) {
cout << "display(int)" << v1 << endl;
}
void display(char v1, int v2) {
cout << "display(char)" << v1 << "," << v2 << endl;
}
int main() {
display(1);
display('a',2);
return 0;
}
-
然后进行编译生成(注意:在编译生成的时候要把debug模式改为release模式,并且要禁止release模式的优化),如下图:

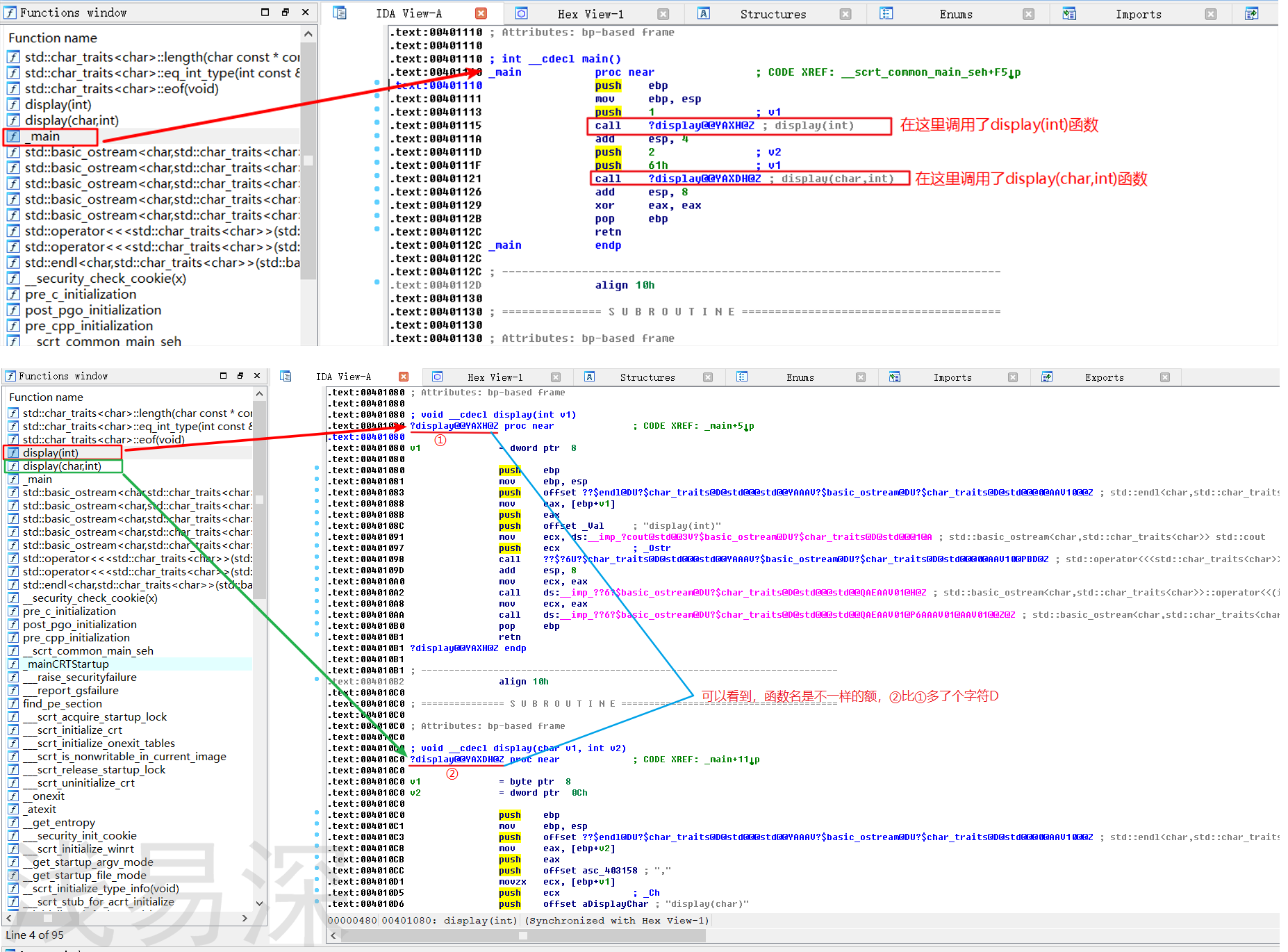
-
再将生成好的release版exe文件使用IDA打开,由下图我们可以看到,两函数名是不同的,这也就印证了我们以上的说法。
2.3 题外话
- 之所以要将debug模式改为release模式,是因为在debug模式下生成的exe中含有需要大量调试信息,而这些调试信息会影响我们的分析。
- 之所以要禁止release模式的优化,是由于我们所编写的display函数太过简单,到时候编译器进行编译时,很可能会把我们的display优化掉,如下图:
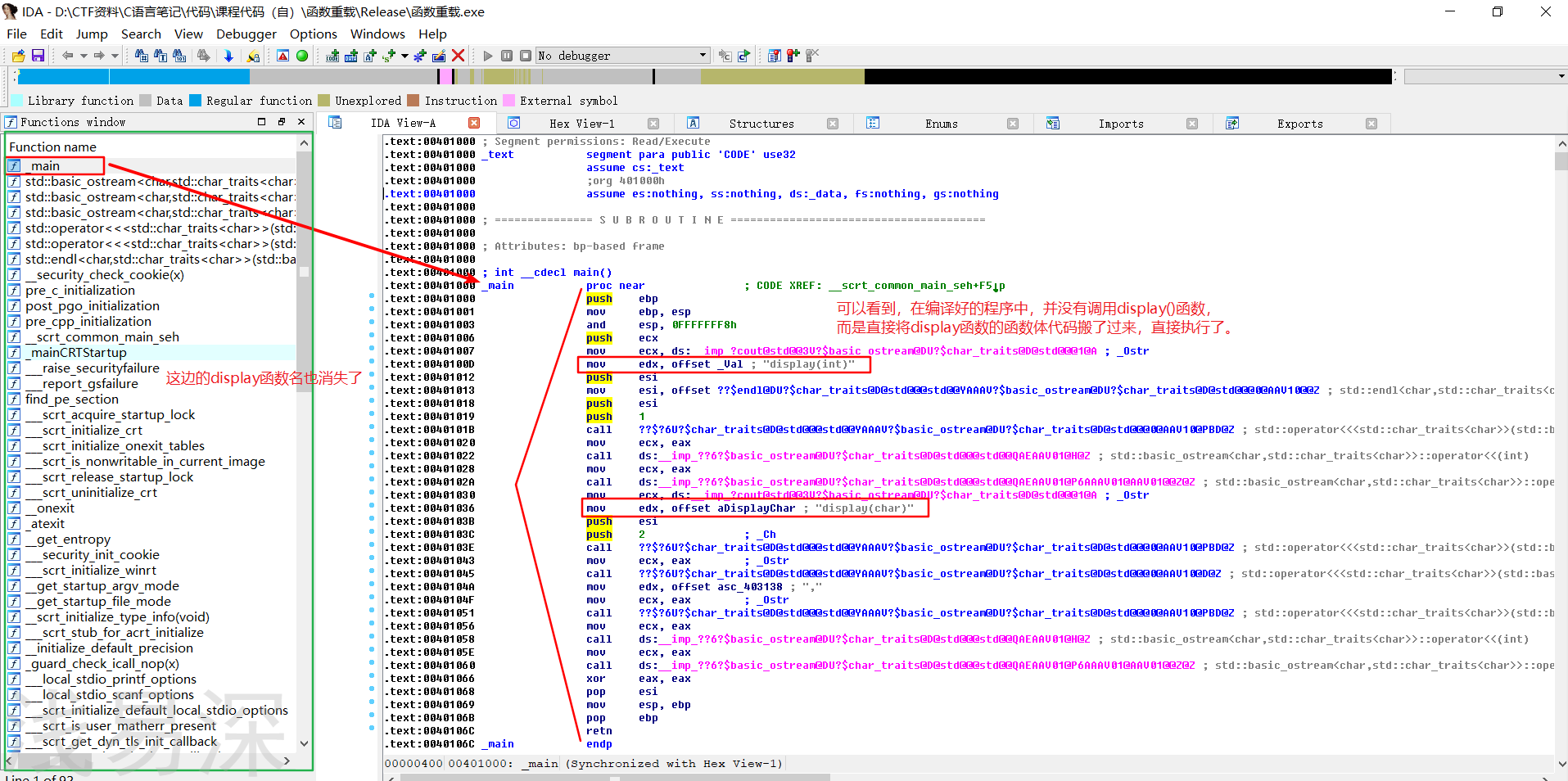
- 可以看到,左边绿框中的display函数名消失了,且右边main函数中并没有调用display函数的痕迹,而是直接将display函数的函数体搬进main函数中的函数体中,直接执行了(编译器之所以这样优化是因为可以减低函数调用的开销)。