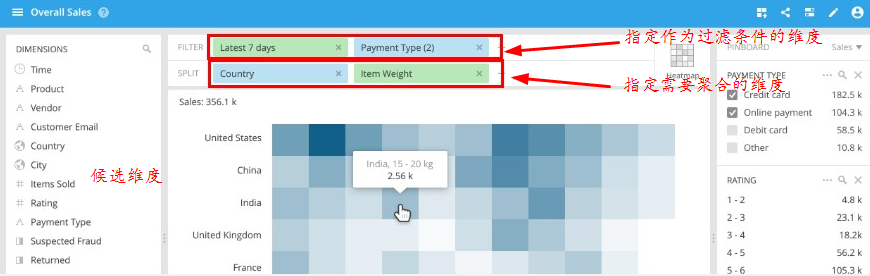
Druid是分布式的OLAP平台,支持实时和批量两种数据灌入模式,在亿级数据规模上能够提供秒级的查询响应。如下图所示,用户可以对指定维度的条件进行过滤(包括等于、模糊匹配等,这部分内容后面会详细解释),也可以按照指定的维度进行聚合。
基本概念
在我们讨论之前,先让我们看看一个数据集的例子 (来源于线上广告):
timestamp publisher advertiser gender country click price
2011-01-01T01:01:35Z bieberfever.com google.com Male USA 0 0.65
2011-01-01T01:03:63Z bieberfever.com google.com Male USA 0 0.62
2011-01-01T01:04:51Z bieberfever.com google.com Male USA 1 0.45
2011-01-01T01:00:00Z ultratrimfast.com google.com Female UK 0 0.87
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 0 0.99
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 1 1.53
这个数据集有三部分组成(这种划分方法来自传统OLAP领域)
Timestamp(时间)列: 将时间列区别开是因为Druid所有的查询都以时间为中心。
Dimension(维度)列: 对应事件的维度,通常用于筛选过滤数据。 在我们例子中的数据有四个维度: publisher, advertiser, gender和 country。
Metric(指标)列: 用于聚合和计算的列。在我们的例子中,click和price就是指标。Metrics通常是数字,并且包含支持count、sum、mean等计算操作;在Druid中可以通过Hyperloglog+和Theta sketch等技术支持distinct count、留存分析等需求。
Roll-up
Druid原始数据的聚合过程我们称作roll-up。 Roll-up是在一系列维度选定后的数据之上做的第一级聚合,类似于(伪代码):
GROUP BY timestamp, publisher, advertiser, gender, country :: impressions = COUNT(1), clicks = SUM(click), revenue = SUM(price) 我们原始数据的合并后看起来如下:
timestamp publisher advertiser gender country impressions clicks revenue
2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70
2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18
2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31
2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01
事实上,这种预聚合的方式可以很显著的减少数据的存储(从我们线上的经验来看,只要数据中中不存在高基数的维度,压缩率能达到1/30)。 Druid也是通过这种方式来减少数据的存储。 这种减少存储的方式也会带来副作用,比如我们没有办法再查询到每条数据具体的明细。换句话说,数据聚合的粒度是我们能查询数据的最小粒度。 因此,Druid在ingestionSpecs中需要定义queryGranularity作为数据的粒度,最小能支持的queryGranularity是毫秒。一般天级导入的数据使用天作为最小查询粒度即可,实时导入的数据则应该根据具体的业务需求决定,一般而言最小查询粒度越大,数据压缩率越高(这是几乎是显然的)。
数据分片
Druid以segments的形式进行分片,并且以时间作为分片的依据。在上面我们合并的数据集中,我们可以每小时一个,创建两个segments。
例如:
Segment sampleData_2011-01-01T01:00:00:00Z_2011-01-01T02:00:00:00Z_v1_0 包含
2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70 2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18
Segment sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_0 包含
2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31 2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01
Segments是自包含容器,包含着一个时间段内的数据。Segments包括基于列的压缩,以及这些列的索引。
Segments通过datasource(sampleData), interval(2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z), version(v1), 和一个可选的partition number(如果某次导入只产生了一个segment,那么这个字段就是缺省的)来区分。
数据格式
提升Druid速度部分依赖于它的存储格式。Druid是列式存储,这就意味这每一个列都是单独存储,在查询的过程中Druid只扫描查询中涉及到的列即可。不同的列可以采用不同的压缩方式,也可以关联不同的索引。大家经常可以看到有人讨论Druid的列式存储格式,下面我们简单介绍一下。以下图为例

时间列、指标列的存储是简单直观的:这些列可以认为是整数数组或者浮点数数组,将这些数组序列化,然后使用LZ4压缩即可。因为维度需要支持过滤、聚合等操作,所以其存储格式也更为复杂一些,由三部分组成
- 将具体的值映射到整数ID的字典;
- 这一列中值的顺序列表(已经以ID的形式存在);
- 对于每一个不同的取值,使用bitmap数据结构表征哪些行包含了这个值(这种索引技术也被称为倒排索引技术)
示例中page维度的存储格式如下所示
1: Dictionary that encodes column values { "Justin Bieber": 0, "Ke$ha": 1 } 2: Column data [0, 0, 1, 1] 3: Bitmaps - one for each unique value of the column value="Justin Bieber": [1,1,0,0] value="Ke$ha": [0,0,1,1]
数据加载
Druid有实时和批量两种数据加载方式。
批量数据导入一般用作T+1的多维数据分析,本质上用户提交schema到overlord节点,druid将其转换为MR作业将原始数据进行预聚合引入druid集群;
实时数据加载我们采用Kafka Indexing Service这套解决方法,抽象而言,用户将数据发送到kafka,druid按照用户指定的方式实时消费Kafka中的数据。
数据查询
Druid原生的查询方式是通过http发送json到broker节点。在本质上OLAP平台提供的都是Groupby查询(某些维度用作过滤、某些维度用来聚合),但是除了groupby查询之外,druid还提供另外两种查询,即TopN和TimeSeries查询。这两种查询可以认为是GroupBy在某些场景下的替代。因为Groupby查询对集群资源的开销比较大,在TopN或者TimeSeries能满足业务场景的情况下,建议尽量采用这两种查询。
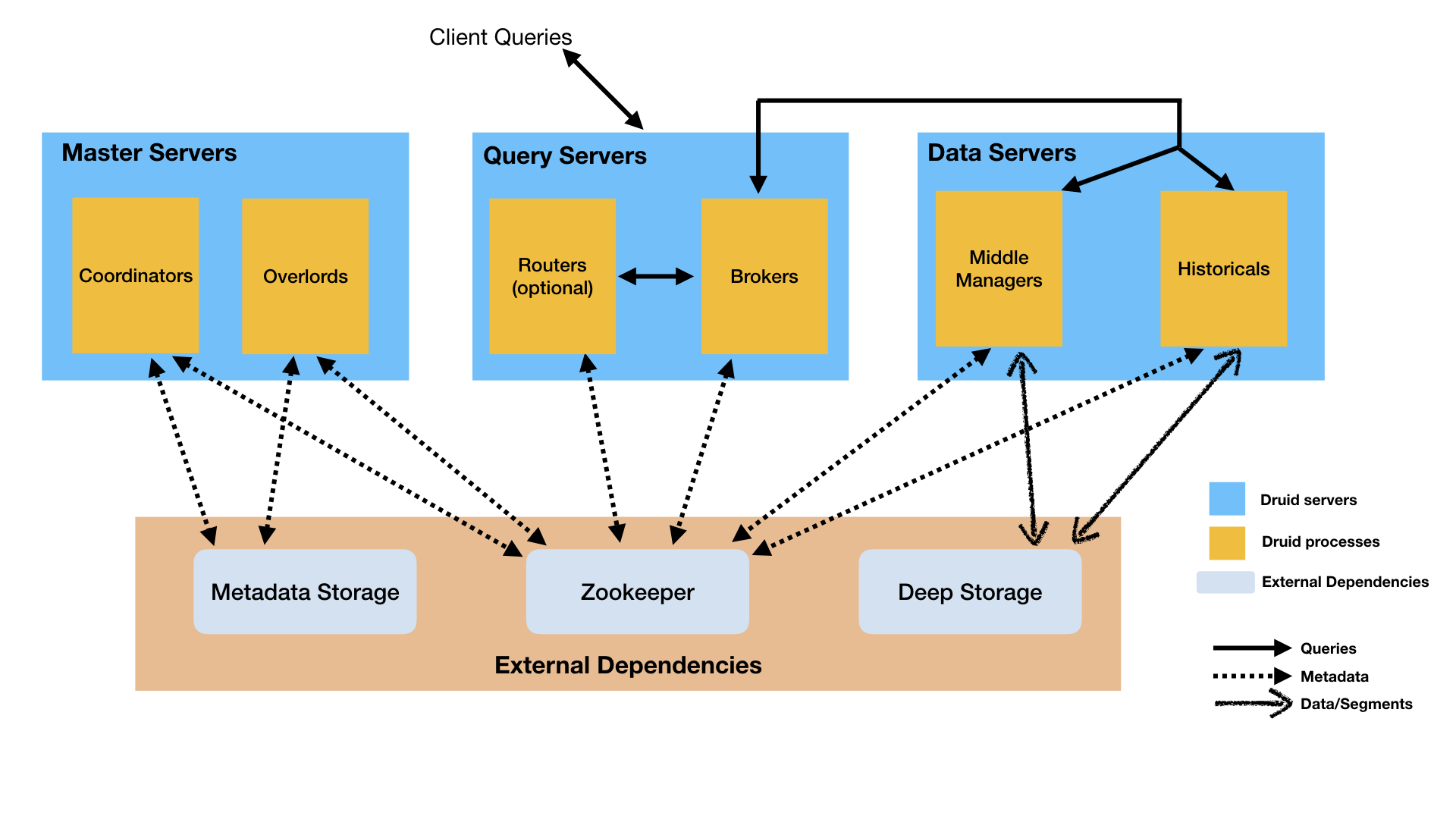
Druid集群
Druid集群由以下几种不同的角色构成(Druid各角色都是以多副本的方式运行, 确保没有单点问题)。
-
Overlord节点负责处理用户的数据导入请求,将这些请求调度到MiddleManager节点进行执行; -
MiddleManager节点负责处理Overlord调度的作业,启动Peon进行进行具体的处理(比如批量导入时会启动HadoopIndexTask任务将Hadoop数据灌入Druid,实时导入数据时会启动KafkaIndexTask执行相应的操作); -
Coordinator节点负责管理、调度集群中Historical节点所承担的数据分片。Coordinator节点通知historical节点从HDFS下载新的数据分片,删除旧的数据分片,以及迁移数据分片以达到负载均衡。 -
Historical节点从HDFS下载数据分片到本地,并提供这部分数据分片的查询服务。Historical节点根据Coordinator的指令能够清楚下载、删除哪些数据分片。 -
Broker节点用户从Druid查询数据的地方。Broker节点负责将查询分解、分发到Historical节点分发查询,以及收集和合并结果。 Broker节点清楚每一个segment在哪个Historical节点查询。 -
Router进程是可选进程,可在Druid Broker,Overlord和Coordinator之前提供统一的API网关。 它们是可选的,因为也可以直接联系Druid Broker,Overlord和Coordinator。
Router还运行Druid控制台,Druid控制台是用于数据源,段,任务,数据过程(Historical和MiddleManager)以及coordinator动态配置的管理UI。 用户还可以在控制台中运行SQL和本机Druid查询。
一般而言,作为Druid的用户需要和Druid的以下角色打交道
-
将数据导入的请求发送给Overlord(端口是8090),提交完成之后,通过浏览器访问http://overlord:8090 可以查看现在作业运行状态,以及运行过程中的日志(方便以后对build失败等情况进行分析),示例如下

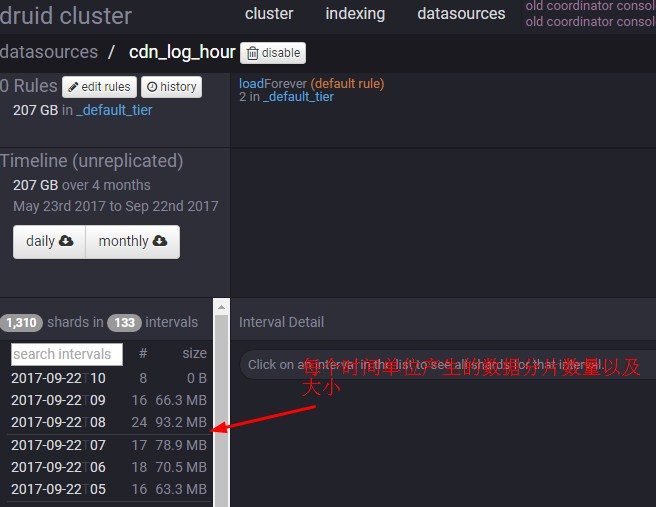
2.查看Coordinator的页面(http://coordinator:8081 ), 可以掌握到自己datasource的时间分布、数据大小以及加载情况
3.查询Broker节点(8082端口),比如使用curl命令向Broker的8082节点发送查询请求
curl -X POST 'http://broker:8082/druid/v2/?pretty' -H 'Content-Type:application/json' -d @query.json