第一次个人编程作业——————#论文查重#
一、GitHub链接githubwork
二、计算模块接口的设计与实现过程

1.定义了包'jc',里面包含了删除停用词的函数以及利用TD-IDF计算余弦相似度求文本相似度的函数:
用于删除停用词函数
def dec_stopwords(file_0):
dec_l = []
for word in file_0:
if word not in stop_words:
dec_l.append(word)
if len(dec_l) == 0:
print('文本为空')
return dec_l
利用tfidf计算余弦相似度

'''利用gensim生成论文的字典'''
dictionary = corpora.Dictionary(list_ori)
'''建立稀疏向量集'''
corpus = [dictionary.doc2bow(tt) for tt in list_ori]
'''对抄袭论文进行jieba分词'''
file_test = [word for word in jieba.cut(file_t)]
'''对抄袭论文建立稀疏向量'''
file_test_vec = dictionary.doc2bow(file_test)
'''建立tfidf'''
tfidf = models.TfidfModel(corpus)
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
'''进行相似度计算'''
sim_val = index[tfidf[file_test_vec]]
关于TF—IDF:


三、计算模块接口部分的性能改进。
1.经过测试发现,删去停用词算出的相似度更为准确。
2.使用pycharm自带的性能测试得出:jc.py占据较多的时间,gensim与停用词节省了许多时间。
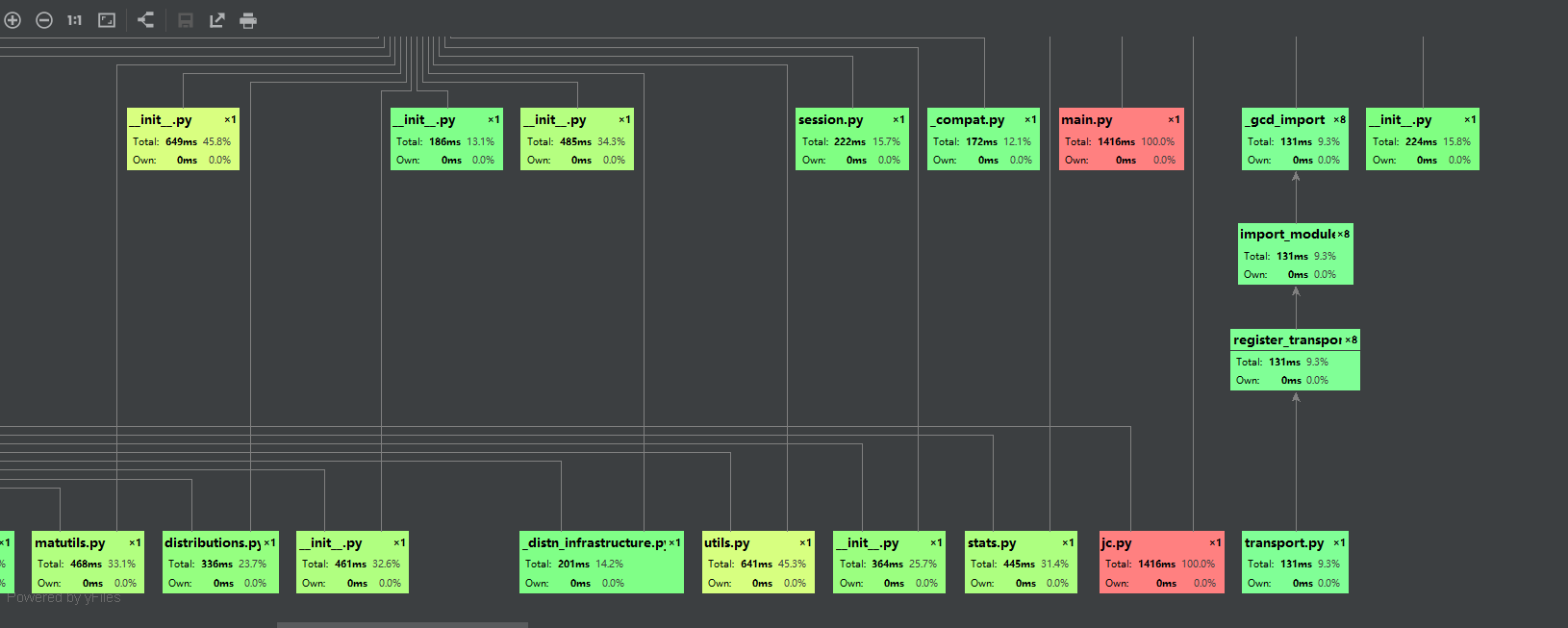
四、计算模块部分单元测试展示
1.测试思路,对于单元测试没有概念,于是看了一些厉害的博客,测试了10个样本数据,前9个为群里提供的样例,还有一个毫不相干的文本。
2.部分测试代码:
import unittest
import jc
import jieba
import logging
class Test_Sim(unittest.TestCase):
def setUp(self) -> None:
print("test start")
def tearDown(self) -> None:
print("test over!")
def test_add(self):
doc1 = open('sim_0.8/orig.txt', 'r', encoding='utf-8').read()
doc2 = open('sim_0.8/orig_0.8_add.txt', 'r', encoding='utf-8').read()
doc1 = jc.dec_stopwords(doc1)
doc2 = jc.dec_stopwords(doc2)
doc_1 = " ".join(doc1)
doc_2 = " ".join(doc2)
xx = jc.sim_value(doc_1, doc_2)
print(xx)
self.assertGreaterEqual(xx, 0)
self.assertLessEqual(xx, 1)
def test_del(self):
doc1 = open('sim_0.8/orig.txt', 'r', encoding='utf-8').read()
doc2 = open('sim_0.8/orig_0.8_del.txt', 'r', encoding='utf-8').read()
doc1 = jc.dec_stopwords(doc1)
doc2 = jc.dec_stopwords(doc2)
doc_1 = " ".join(doc1)
doc_2 = " ".join(doc2)
xx = jc.sim_value(doc_1, doc_2)
print(xx)
self.assertGreaterEqual(xx, 0)
self.assertLessEqual(xx, 1)
def test_dis1(self):
doc1 = open('sim_0.8/orig.txt', 'r', encoding='utf-8').read()
doc2 = open('sim_0.8/orig_0.8_dis_1.txt', 'r', encoding='utf-8').read()
doc1 = jc.dec_stopwords(doc1)
doc2 = jc.dec_stopwords(doc2)
doc_1 = " ".join(doc1)
doc_2 = " ".join(doc2)
xx = jc.sim_value(doc_1, doc_2)
print(xx)
self.assertGreaterEqual(xx, 0)
self.assertLessEqual(xx, 1)
def test_dis3(self):
doc1 = open('sim_0.8/orig.txt', 'r', encoding='utf-8').read()
doc2 = open('sim_0.8/orig_0.8_dis_3.txt', 'r', encoding='utf-8').read()
doc1 = jc.dec_stopwords(doc1)
doc2 = jc.dec_stopwords(doc2)
doc_1 = " ".join(doc1)
doc_2 = " ".join(doc2)
xx = jc.sim_value(doc_1, doc_2)
print(xx)
self.assertGreaterEqual(xx, 0)
self.assertLessEqual(xx, 1)
def test_dis7(self):
doc1 = open('sim_0.8/orig.txt', 'r', encoding='utf-8').read()
doc2 = open('sim_0.8/orig_0.8_dis_7.txt', 'r', encoding='utf-8').read()
doc1 = jc.dec_stopwords(doc1)
doc2 = jc.dec_stopwords(doc2)
doc_1 = " ".join(doc1)
doc_2 = " ".join(doc2)
xx = jc.sim_value(doc_1, doc_2)
print(xx)
self.assertGreaterEqual(xx, 0)
self.assertLessEqual(xx, 1)
def test_dis10(self):
doc1 = open('sim_0.8/orig.txt', 'r', encoding='utf-8').read()
doc2 = open('sim_0.8/orig_0.8_dis_10.txt', 'r', encoding='utf-8').read()
doc1 = jc.dec_stopwords(doc1)
doc2 = jc.dec_stopwords(doc2)
doc_1 = " ".join(doc1)
doc_2 = " ".join(doc2)
xx = jc.sim_value(doc_1, doc_2)
print(xx)
self.assertGreaterEqual(xx, 0)
self.assertLessEqual(xx, 1)
3.测试覆盖率截图:
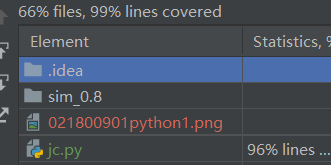
可以看到jc.py几乎全覆盖了。
五、计算模块部分异常处理说明。
1.当没有参数输入时报错
except:
print("缺少参数!")
except:
print("%s打开失败 " % (sys.argv[3]))
六、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 120 |
| Estimate | 估计这个任务需要多少时间 | 150 | 210 |
| Development | 开发 | 30 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 60 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 30 | 60 |
| Coding | 具体编码 | 60 | 120 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 30 | 30 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
七、总结
这次软工作业有太多新的东西要学了,作业发布不久,就开始看python了,然后还有一堆的东西学不完,这次作业开始的比较迟,第一次也不会用github,没能实时签入,后来也网上冲浪学会了大概,还有单元测试什么的。总之,软工课带来一定的压力,从而促进学习,真正学到些东西,不管见没见过,学,都可以学。