一. 背景介绍
在MySQL中,几乎所有的数据表都会有一个主键,主键是不允许重复的,所以表中的每一条数据的id都不会相同。
主键id可以是数字,也可以是字符串,一般情况下都会选择数字做主键id,数字类型,又可以分为int、long、float、double这几大类(可以细分),创建数据表的时候,会根据预期的数据量来选择数据类型。
对于数字类型这种主键,在插入新纪录的时候,有两种选择:1、id自增,插入数据时,忽略id字段(或者设为null,会自动使用自增id);2、插入数据时,手动指定id的值。两种方式都有各自的优缺点。
二. 主键id自增的优缺点
优缺点可以参考网上的博文:https://www.jianshu.com/p/f5d87ceac754
抛开上面的博文中所提到的缺点不谈(因为迄今为止我也没遇到过这样的问题),我平时遇到更多的问题,是下面这样的:
1、有一个数据,会多个系统共享。
2、当数据产生后的时候,所有相关的系统,都能根据一个标识(id)来找出这条数据记录。
你可能会想,数据产生后,我先入库,因为数据入库后就有一个主键id(自增),然后我将该包含主键id的数据查出来,再发给其他系统,这样所有系统都能知道这条数据的id了。
但是,这里存在一个问题,入库后,你怎么找出之前入库的是哪条数据?很多时候,标志数据唯一性的就只有主键,这个时候怎么办?特别是插入频率特别高的时候,如何准确找到那一条数据?几乎是不可能的!除非,在插入数据的时候,就指定了id。
三. 手动指定主键id的优缺点
手动指定主键id的优点(不用id自增),可以解决上面那个问题;
缺点很明显,就是容易出现主键id冲突,当插入频率达到一定程度时,就会出现大量这种问题,一旦出现这种问题,入库就会失败,造成数据丢失(应用层可以做异常处理来避免数据丢失)。
其实,我们只需要解决主键id重复的问题就ok了,对吧。
那么怎么生成主不重复的主键id呢?特别是当前的分布式架构盛行,大量的数据从不同的节点产生,如何保证每一条数据都能分配到一个唯一的id,这是个问题。
目前已经有很多种算法,比如UUID、SnowFlake算法,还有一些中间件,redis和zk也有自己的唯一id生成算法。
可以参考:
四. UUID算法
关于uuid的算法介绍,可以参考百度百科:https://baike.baidu.com/item/UUID
在Java中UUID工具类(java.util.UUID),可以生成128bit(32字节)的十六进制字符串,由4个“-”将十六进制字符串分隔为5段,规则为8-4-4-4-12,一共是36位,每一段都有特殊的含义,比如:4ab1416b-cafc-4932-b052-cd963aff22eb。
下面是使用示例:
import java.util.UUID;
public class UuidDemo {
public static void main(String[] args) {
final UUID uuid = UUID.randomUUID();
System.out.println(uuid);
// 4ab1416b-cafc-4932-b052-cd963aff22eb
// 一共128bit(32字节),加上4个-分隔符,一共36位,规则是8-4-4-4-12
}
}
五. snowflake算法
snowflake是twitter开源的一种算法,可以生成全局唯一的id。
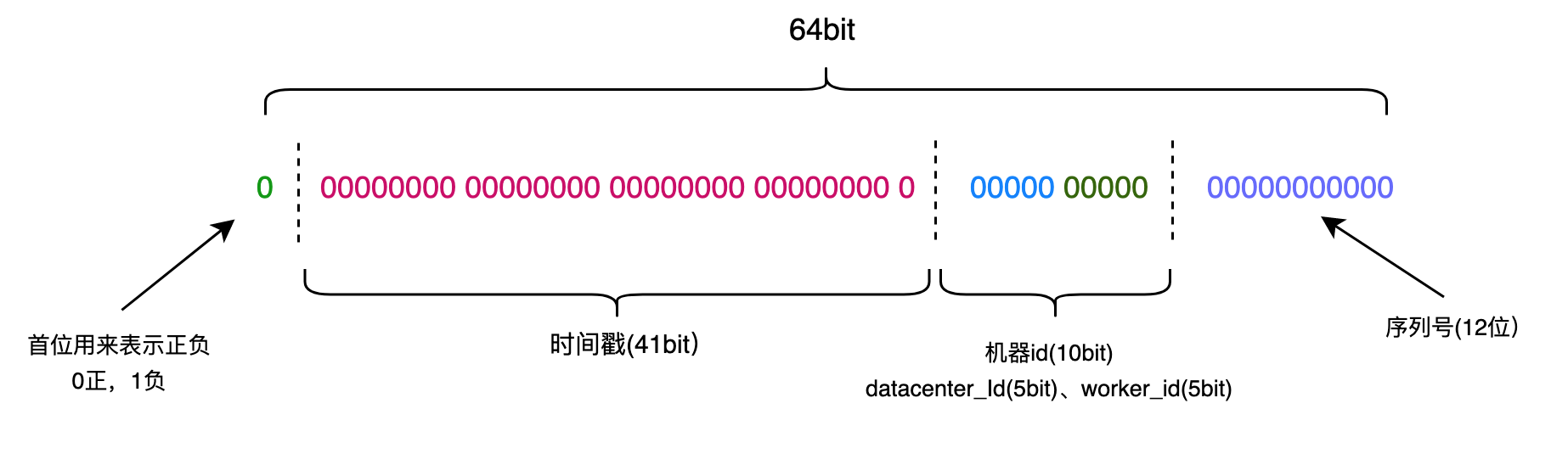
生成的id是一个64bit的数字,这64bit可以分为4部分,如下图所示,每一部分都有特殊的含义:
snowflake算法的实现代码如下:
package cn.ganlixin.ssm.util.common;
public class SnowFlakeIdGenerator {
//初始时间截 (2017-01-01)
private static final long INITIAL_TIME_STAMP = 1483200000000L;
//机器id所占的位数
private static final long WORKER_ID_BITS = 5L;
//数据标识id所占的位数
private static final long DATACENTER_ID_BITS = 5L;
//支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
//支持的最大数据标识id,结果是31
private static final long MAX_DATACENTER_ID = ~(-1L << DATACENTER_ID_BITS);
//序列在id中占的位数
private final long SEQUENCE_BITS = 12L;
//机器ID的偏移量(12)
private final long WORKERID_OFFSET = SEQUENCE_BITS;
//数据中心ID的偏移量(12+5)
private final long DATACENTERID_OFFSET = SEQUENCE_BITS + WORKER_ID_BITS;
//时间截的偏移量(5+5+12)
private final long TIMESTAMP_OFFSET = DATACENTER_ID_BITS + WORKER_ID_BITS + SEQUENCE_BITS;
//生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
private final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);
//数据中心ID(0~31)
private long datacenterId;
//工作节点ID(0~31)
private long workerId;
//毫秒内序列(0~4095)
private long sequence = 0L;
//上次生成ID的时间截
private long lastTimestamp = -1L;
/**
* 构造函数
*
* @param datacenterId 数据中心ID (0~31)
* @param workerId 工作ID (0~31)
*/
public SnowFlakeIdGenerator(long datacenterId, long workerId) {
if (workerId > MAX_WORKER_ID || workerId < 0) {
throw new IllegalArgumentException(String.format("WorkerID 不能大于 %d 或小于 0", MAX_WORKER_ID));
}
if (datacenterId > MAX_DATACENTER_ID || datacenterId < 0) {
throw new IllegalArgumentException(String.format("DataCenterID 不能大于 %d 或小于 0", MAX_DATACENTER_ID));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获得下一个ID (用同步锁保证线程安全)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
// 毫秒时间戳(13位)
long timestamp = System.currentTimeMillis();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException("当前时间小于上一次记录的时间戳!");
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
//sequence等于0说明毫秒内序列已经增长到最大值
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//时间戳改变,毫秒内序列重置
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - INITIAL_TIME_STAMP) << TIMESTAMP_OFFSET)
| (datacenterId << DATACENTERID_OFFSET)
| (workerId << WORKERID_OFFSET)
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
}
测试使用:
package cn.ganlixin.ssm.util;
import org.junit.Test;
public class SnowFlakeGeneratorTest {
@Test
public void testGen() {
SnowFlakeIdGenerator idGenerator = new SnowFlakeIdGenerator(1, 1);
System.out.println(idGenerator.nextId()); // 429048574572105728
}
}