在Spark1.6版本中,试图为RDD,DataFrame提供一个新的实验性接口Dataset api接口,所以从范围来说,下面这张图能表明:
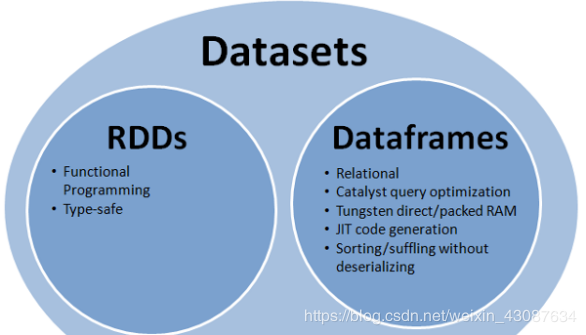
Dataframe是Dataset的row类型。
RDD
是弹性的分布式数据集。
1.懒执行且不可变,支持lambda表达式的并行数据集合
2.面向对象的编程风格,使用对象点的方式操作数据
缺点:
3.集群间的通信,IO操作都需要对对象的结构和数据进行序列化和反序列化。
2.RDD的劣势是性能限制,它是一个JVM驻内存对象,所以存在GC的限制,频繁的创建和销毁对象增加GC。
DataFrame
和RDD类似,Dataframe也是一个分布式数据容器,它是表格型数据结构。它像传统数据库的二维表格,它同样记录数据的结构信息,即schema。同时,DataFrame也是Hive相似,支持嵌套数据类型(struct,array和map)。DataFrame是分布式的Row对象的集合。
1.懒执行,DataFrame为数据提供了Schema(架构)的视图,可以把它当做数据库的一张表来对待。
2.优势:1)定制化内存管理,数据以二进制的方式存在非堆内存,节省了大量空间,并摆脱了GC(垃圾回收)的限制。
2)优化的执行计划,查询计划通过Spark catalyst(催化剂)optimiser(优化)进行优化。
3)RDD的每一行的数据和结构都是一样的存储在schema中,spark通过schema能读懂数据。
Dataset
Dataset相比于RDD和Dataframe少了序列化的步骤,Dataset结合了RDD和DataFrame的优点,带来一个新的概念Encoder。
1.是Dataframe api的一个扩展,是Spark最新的数据抽象
2.具有Dataframe的查询优化特性
3.可以使用样例类在Dataset定义数据的结构信息,样例类的每个属性的名称直接映射到Dataset中的字段名称
4.DataFrame是Dataset的特例,Dataframe是Dataset是Row类型,所以可以通过as方法将Dataframe转换为Dataset。
所有表结构信息都用Row来表示。
5.Dataset是强类型的,如有Dataset[Car],Dataset[Person]。
联系:三者之间的转换
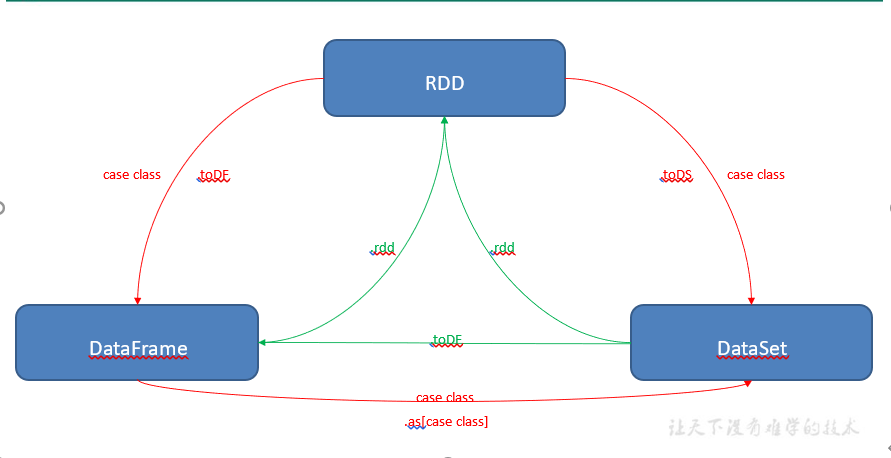
区别:
1.Dataset内部序列化机制和RDD不同,可以不用反序列化整个对象调用对象的方法。
2.Dataset是强类型的,默认有列名“value”,操作上的方法比RDD的要多,RDD上有的算子,Dataset也都有
在Spark1.6中有读取json格式的RDD,在Spark2.0+中只有读取json格式的Dataset