学习代码时,遇到了cudaMalloc 和 cudaMallocHosts 同时出现的情景,所以学习一下二者的区别。
参考资料1:cudaMallocHost函数详解
参考资料2:How to Optimize Data Transfers in CUDA C/C++ 中文翻译:中文翻译
host内存:分为pageable memory 和 pinned memory
pageable memory: 通过操作系统API(malloc(),new())分配的存储器空间;
pinned memory :始终存在于物理内存中,不会被分配到低速的虚拟内存中,能够通过DMA加速与设备端进行通信;cudaHostAlloc(), cudaFreeHost()来分配和释放pinned memory;
使用Malloc分配的内存都是Pageable(交换页)的,而另一个模式就是Pinned(Page-locked),实质是强制让系统在物理内存中完成内存申请和释放的工作,不参与页交换,从而提高系统效率,需要使用cudaHostAlloc和cudaFreeHost(cudaMallocHost的内存也这样释放)来分配和释放。
Pageable(交换页)与Pinned(Page-locked)都是“Write-back”,现在X86/X64CPU,会直接在内部使用一个特别的缓冲区,将写入合并,等没满64B(一个cache line),集中直接写入一次,越过所有的缓存,而读取的时候会直接从内存读取,同样无视各级缓存。
这种最大的用途可以用来在CUDA上准备输入数据,因为它在跨PCI-E传输的时候,可能会更快一些(因为不需要询问CPU的cache数据是否在里面)。
使用pinned memory优点:主机端-设备端的数据传输带宽高;某些设备上可以通过zero-copy功能映射到设备地址空间,从GPU直接访问,省掉主存与显存间进行数据拷贝的工作;
使用pinned memory缺点:pinned memory 不可以分配过多:导致操作系统用于分页的物理内存变少, 导致系统整体性能下降;通常由哪个cpu线程分配,就只有这个线程才有访问权限;
*************************************************************************************************************************************************
主机(CPU)数据分配的内存默认是可分页的。GPU不能直接访问可分页的主机内存,所以当从可分页内存到设备内存的进行数据传输时,CUDA驱动必须首先分配一个临时的不可分页的或者固定的主机数组,然后将主机数据拷贝到固定数组里,最后再将数据从固定数组转移到设备内存,如下图所示: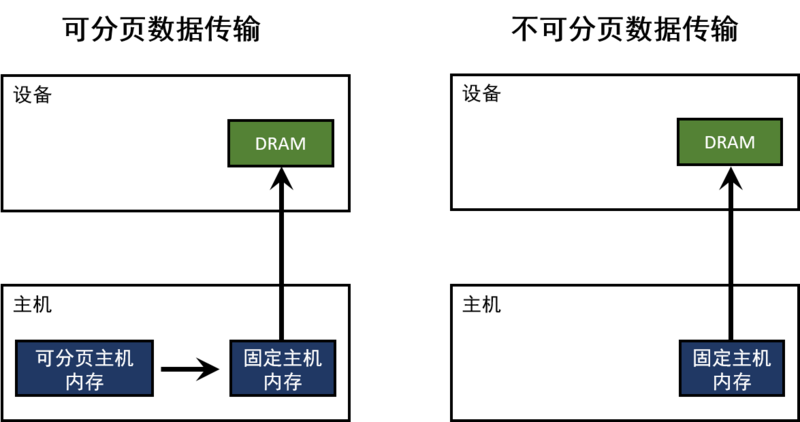
正如你在图中所看到的那样,固定内存被用作数据传输的暂存区。我们可以通过直接分配固定内存的主机数组来避免这一开销。在CUDA C/C++中,我们可以使用cudaMallocHost()或者cudaHostAlloc()来分配固定内存,使用 cudaFreeHost()来释放内存。
固定内存的分配有可能会失败,所以你应该总是检查错误。下面的代码片段演示了如何分配固定内存并进行错误检查。
cudaError_t status = cudaMallocHost((void**)&h_aPinned, bytes); if (status != cudaSuccess) printf("Error allocating pinned host memoryn");
固定内存的数据传输和可分页内存一样,使用相同的cudaMemcpy()语法。我们可以使用下面的“bandwidthtest”(带宽测试)程序(同样可以在Github上找到)来对比可分页内存和固定内存的传输速度。
#include <stdio.h> #include <assert.h> // Convenience function for checking CUDA runtime API results // can be wrapped around any runtime API call. No-op in release builds. inline cudaError_t checkCuda(cudaError_t result) { #if defined(DEBUG) || defined(_DEBUG) if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %sn", cudaGetErrorString(result)); assert(result == cudaSuccess); } #endif return result; } void profileCopies(float *h_a, float *h_b, float *d, unsigned int n, char *desc) { printf("n%s transfersn", desc);
(24条消息) CUDA:cudaMalloc vs cudaMallocHost_微风❤水墨的博客-CSDN博客_cuda_malloc