变量让程序活起来,不再千人一面。
【realpython.cn 正在翻译《RealPython 基础教程》,敬请关注!】
我们在之前的文章《Python 基本数据类型介绍》中了解了如何创建各种基本类型的数据,但是我们的例子中使用的都是“字面量”或者“常量”。
5.3
这显然不适于复杂的实用程序中,我们需要定义能够在程序执行过程中可以变化的数据。
通过本文,你将了解到:
1,Python 中的所有数据元素都可通过抽象的对象(object)来描述
2,你将学会如何通过符号名称(变量)来操作这些对象。
【变量的赋值】
我们可将变量视作附着在一个特定对象上的名称。
在 Python 中,变量不必提前声明或定义。这和其他一些编程语言不同,在那些编程语言里,变量必须先声明才可以使用。
创建变量很简单,只需要为这个名称赋一个值就行了,然后你就可以使用它了。
Python 使用等号(=)为变量赋值:
这个赋值语句的意思是:n 被赋值为 300.
赋值完成后,n 就可以被用作语句或者表达式中了。其值也会被更新。
300
我们也可以不使用 print() 函数,直接在 Python 解释器命令提示符窗口中输入 n 来打印其值。
300
可以给 n 重新赋值。
1000
Python 允许链式赋值,这让我们可以同时为多个变量赋相同的值。
300300300
【Python 变量的类型】
数据类型是对数据上可执行操作的约定。
在很多编程语言中,变量是静态类型。其含义是,变量在初始化时需要声明为一个特定的类型,在后续的使用中也只能将相同类型的值赋给这个变量。静态类型的变量,意味着在其上只能执行类型专有的操作。
而 Python 中的变量不受此限制。变量可以被赋予一个类型的值,之后再被赋予另一个类型的值。
23.5<class 'float'>>>> var = "now i'm a string""now i'm a string"<class 'str'>
在实际应用中,动态改变变量的类型可能并非一个好的行为,这会引起理解和运行上的混乱。
【对象引用】
当我们创建一个变量时,Python 解释器到底执行了什么操作?
了解这个问题的答案很重要,因为这和你在其他语言中理解的原来稍微有点不一样。
Python 是一个高度面向对象的语言。Python 程序中的每个数据元素都是一个特定类(class)的实例对象(object)。
考虑下边这段简单的代码:
300
当执行 print(300) 这条语句时,Python 解释器会做以下 3 个工作:
-
创建一个整数对象
-
为这个整数对象赋值 300
-
将这个整数对象输出到控制台
使用 type() 函数就能看出为这个常量 300 创建了一个整数对象:
<class 'int'>
Python 变量其实只是一个名称而已,它是指向某个对象的引用或者指针,是“贴在这个对象上的一个标签”。
一旦变量被赋值,你就可以通过变量名来引用它指向的对象,变量拥有的数据实际上是被保存在这个对象中。
仍以这个简单代码为例:
这个赋值语句创建了一个值为 300 的整数对象,并将变量 n 指向这个对象。


你可以这样理解:喏,整数为 300 的对象,给你贴个标签,你现在叫 n 了。
以下代码就可看出 n 指向了一个值为 300 的 int 类型的对象:
300<class 'int'>
再看下边这条语句:
那么,执行这条语句时又发生了什么?
Python 并没有为 m 创建一个新的对象,而只是建立了一个新的名字 m,并将这个名字指向了 n 指向的对象。

现在,值为 300 的整数对象身上贴了两个标签:n 和 m。
我们接着执行以下操作:
这时,Python 才又创建了一个新的值为 400 的整数对象,并将名字 m 指向这个对象。
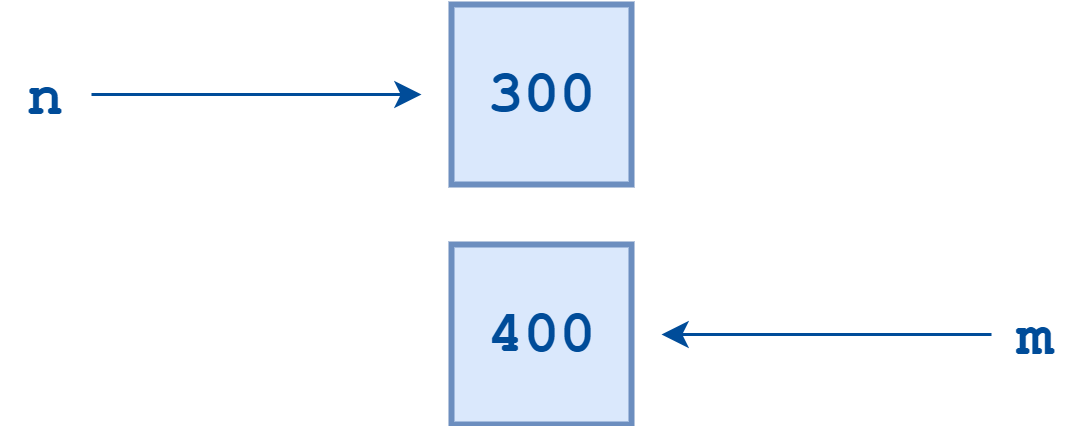
300 和 400 两个整数对象各有一个标签。
最后,我们再执行一条语句:
这会导致 Python 创建一个新的字符串对象,其值为 foo,并将名字 n 指向这个字符串对象。
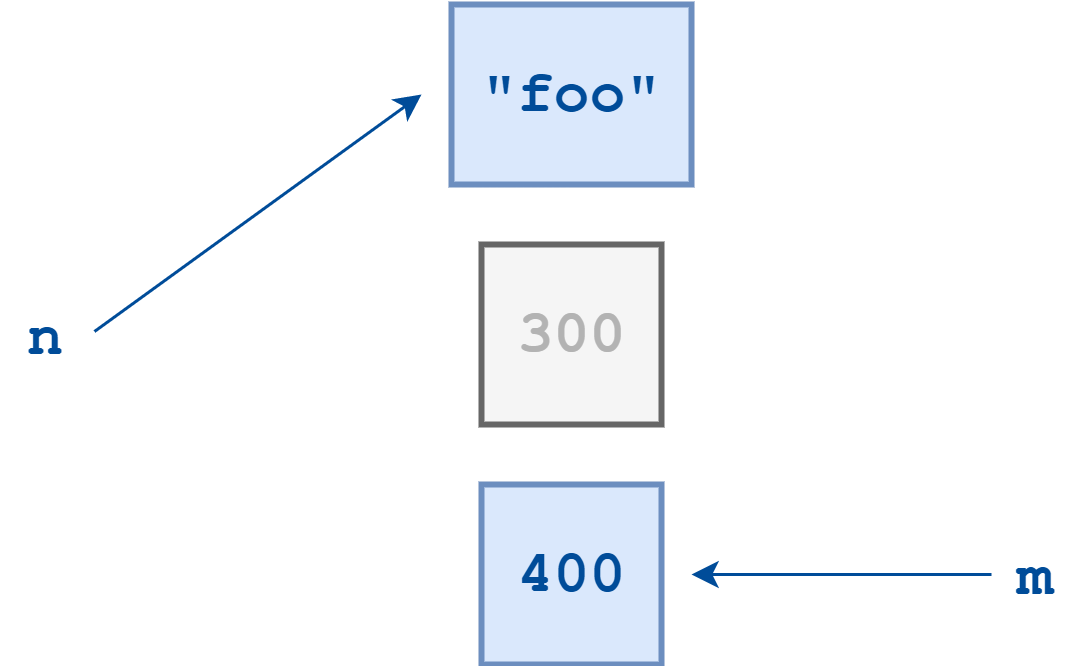
因为变量是一个名字、一个标签,它可以被轻易地从一个对象贴往另一个对象,不管这些对象是否属于同一类型。
你也能够看到,n 指向字符串对象后,不再有任何名字指向整数 300 这个对象,我们无法再对其进行访问,它变成一个“孤儿”了!
这里简单介绍一下 Python 对象的生命周期。
一个对象的生命周期始于它被初始创建时,那时至少有一个引用指向它。在后续的过程中,会有其他引用指向或不再指向它,也就是说,指向一个对象的引用数目是动态变化的。但只要还有一个引用指向它,这个对象就保持存活状态。
当对象的引用数减少到 0 时,这个对象就变为不可访问状态了。这也意味着其生命周期即将结束。Python 解释器会留意到这个对象不可访问,将其占用的内存重新标记为可用。
这个过程在计算机领域称为:垃圾回收。
【对象身份(id)】
Python 为每一个创建的对象分配一个数字,这个数字可唯一地标识这个对象。Python 解释器确保不会有任何两个对象在其生命周期内拥有相同的标识。一旦对象的引用计数减至 0,伴随着对象被回收,它的标识数字也会被回收,并可重用。
Python 内置的 id() 函数可返回一个对象的标识。我们可用这个函数来判断两个变量是否指向了同一个对象。
14559468140641455946814064>>> m=4001455946814256
这也验证了我们上边对“变量是对象的引用”的分析。
有了这些概念后,下边这段代码执行结果很容易理解:
14559430432481455946814256
m 和 n 指向了不同的整数对象。
但是,下边这段代码执行结果该如何解释?
140723401618608140723401618608
m 和 n 的值都是30,它们的 id 竟然也是相同的!
原来,出于优化目的,Python 解释器在启动时自动创建了一批数值介于 [-5, 256] 之间的“小整数”对象,这些对象会在程序运行过程中被重用。此称为“小整数缓存”。
所以,当你给变量赋值 [-5, 256] 之间的整数时,具有相同值的变量实际上会指向同一个对象。
【变量命名】
在我们使用过的例子里,我们用到的变量名都是诸如 m、n 这样简短的名字。而变量的名字其实是可以很长并且具有明确意义的。合理的命名变量会让人一眼就明白其含义,有助于代码的理解和维护。
Python 支持任意长度的变量名,并且变量名可以包含大小写字母(A-Z、a-z)、数字(0-9)和下划线(_)。一个限制是:变量名首字符不得是数字。
以下是一些合法的变量名:
Bob 54 True
而以数字开头的变量名则会引起语法错误:
File "<stdin>", line 11099_filed = False^SyntaxError: invalid token
另外,变量名也是大小写敏感的,大写和小写被视作不同的字符。
以下几个变量应视为不同的变量:
如果你在同一程序中同时使用了这几个形式不同的 age 给变量命名,这是不被提倡的。这会引起混淆,在不同地方遇到 age 时需要绞尽脑汁来思考它的确切含义,也会给代码维护者带来很大麻烦。
变量名称应是自描述的,能清晰地表明变量是用来做什么的。
假如你有一个表示毕业生数目的变量,那么你可以使用下边这几个变量名:
这些名称明显好于 m、n,你可以从中读出它们表示的是什么。
这些“好”的变量名可读性也不完全相同,尤其是前两个,比较难识别其中的单词。
采用何种命名方式因人而异,不同组织也有自己的规则。
最常见的 3 种多单词变量命名方式为:
-
驼峰命名法
首字母小写,其余单词首字母大写:numberOfCollegeGraduates
-
Pascal 命名法
所有单词首字母大写:NumberOfCollegeGraduates
-
蛇形命名法
字母小写,单词间以下划线(_)分隔:number_of_college_graduates
除了变量,Python 中的其他标识符(函数名、类名、模块名等)也需要采用合理和一致的命名方式。
Python 官方代码风格(PEP 8)建议的命名风格为:
-
使用蛇形命名法为变量和函数命名
-
使用 Pascal 命名法为类命名
【关键字】
对标识符(变量、函数、类、模块等的名称)命名还有一个约束:不得使用 Python 关键字来命名。
Python 关键字是 Python 语言保留的一些实现语言层面功能的词语。用户使用这些词语给自定义标识符命名会导致语法错误。
>>> for = 3File "<stdin>", line 1for = 3^SyntaxError: invalid syntax
这些关键字包括:
False、None、True、and、as、assert、break、class、continue、def、del、elif、else、except、finally、for、from、global、if、import、in、is、lambda、nonlocal、not、or、pass、raise、return、try、while、with、yield
【结语】
本文全面介绍了 Python 变量的基础知识,包括对象引用和标识、标识符命名等。
现在我们已对 Python 数据类型有了很好的理解,并且能够通过变量来创建这些不同类型的数据对象了。
接下来,我们会学习如何在表达式中使用这些对象,并了解各种操作符的用法。
realpython.cn 正在翻译《RealPython 基础教程》,敬请关注!