摘要: 在阿里巴巴在线在线技术峰会上的第三天,来自阿里云高级技术专家李金波为大家题为《企业大数据平台仓库架构建设思路》。本次分享中,李金波主要从总体思路、模型设计、数加架构、数据治理四个方面介绍了如何利用大数据平台的特性,构建更贴合大数据应用的数据仓库。
本文根据阿里云高级技术专家李金波在首届阿里巴巴在线峰会的《企业大数据平台仓库架构建设思路》的分享整理而成。随着互联网规模不断的扩大,数据也在爆炸式地增长,各种结构化、半结构化、非结构化数据的产生,越来越多的企业开始在大数据平台下进行数据处理。分享中,李金波主要从总体思路、模型设计、数加架构、数据治理四个方面介绍了如何利用大数据平台的特性,构建更贴合大数据应用的数据仓库。
直播视频:

(点击图片查看视频)
幻灯片下载:点此进入
以下为整理内容。
总体思路
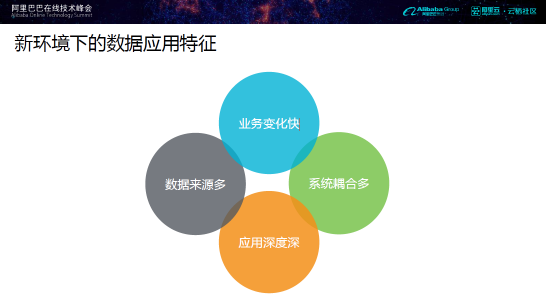
随着互联网规模不断的扩大,数据也在爆炸式地增长,各种结构化、半结构化、非结构化数据不断地产生。新环境下的数据应用呈现业务变化快、数据来源多、系统耦合多、应用深度深等特征。那么基于这些特征,该如何构建数据仓库呢?我认为应该从稳定、可信、丰富、透明四个关键词入手。其中,稳定要求数据的产出稳定、有保障;可信意味着数据的质量要足够高;丰富是指数据涵盖的业务面要足够丰富;透明要求数据构成流程体系是透明,让用户放心使用。

我们之所以选择基于大数据平台构建数据仓库,是由大数据平台丰富的特征决定的:
-
强大的计算和存储能力,使得更扁平化的数据流程设计成为可能,简化计算过程;
-
多样的编程接口和框架,丰富了数据加工的手段;
-
丰富的数据采集通道,能够实现非结构化数据和半结构化数据的采集;
-
各种安全和管理措施,保障了平台的可用性。

仓库架构设计原则包括四点:第一自下而上结合自上而下的方式,保障数据搜集的全面性;第二高容错性,随着系统耦合度的增加,任何一个系统出现问题都会对数仓服务产生影响,因此在数仓构建时,高容错性是必不可少的因素;第三数据质量监控需要贯穿整个数据流程,毫不夸张地说,数据质量监控消耗的资源可以等同于数据仓库构建的资源;第四无需担心数据冗余,充分利用存储换易用。
模型设计
构建数仓的首要步骤就是进行模型设计。
维度莫建模或实体关系建模

常见的模型设计思路包括维度建模和实体关系建模。维度建模实施简单,便于实时数据分析,适用于业务分析报表和BI;实体关系建模结构较复杂,但它便于主体数据打通,适合复杂数据内容的深度挖掘。
每个企业在构建自己数仓时,应该根据业务形态和需求场景选择合适的建模方式。对于应用复杂性企业,可以采用多种建模结合的方式,例如在基础层采用维度建模的方式,让维度更加清晰;中间层采用实体关系建模方式,使得中间层更容易被上层应用使用。
星型模型和雪花模型

除了建模方式之外,在星型模型和雪花模型的选择上也有可能让使用者左右为难。事实上,两种模型是并存的,星型是雪花模型的一种。理论上真实数据的模型都是雪花模型;实际数据仓库中两种模型是并存的。
由于星型模型相对结构简单,我们可以在数据中间层利用数据冗余将雪花模型转换成星型模型,从而有利于数据应用和减少计算资源消耗。
数据分层

在确定建模思路和模型类型之后,下一步的工作是数据分层。数据分层可以使得数据构建体系更加清晰,便于数据使用者快速对数据进行定位;同时数据分层也可以简化数据加工处理流程,降低计算复杂度。
我们常用的数据仓库的数据分层通常分为集市层、中间层、基础数据层上下三层结构。由传统的多层结构减少到上下三层结构的目的是为了压缩整体数据处理流程的长度,同时扁平化的数据处理流程有助于数据质量控制和数据运维。
在上下三层的结构的右侧,我们增加了流式数据,将其添加成数据体系的一部分。这是因为当前的数据应用方向会越来越关注数据的时效性,越实时的数据价值度越高。
但是,由于流式数据集的采集、加工和管理的成本较高,一般都会按照需求驱动的方式建设;此外,考虑到成本因素,流式数据体系的结构更加扁平化,通常不会设计中间层。
下面来具体看下每一层的具体作用。
数据基础层

数据基础层主要完成的工作包括以下几点:
-
数据采集:把不同数据源的数据统一采集到一个平台上;
-
数据清洗,清洗不符合质量要求的数据,避免脏数据参与后续数据计算;
-
数据归类,建立数据目录,在基础层一般按照来源系统和业务域进行分类;
-
数据结构化,对于半结构化和非结构化的数据,进行结构化;
-
数据规范化,包括规范维度标识、统一计量单位等规范化操作。
数据中间层

数据中间层最为重要的目标就是把同一实体不同来源的数据打通起来,这是因为当前业务形态下,同一实体的数据可能分散在不同的系统和来源,且这些数据对同一实体的标识符可能不同。此外,数据中间层还可以从行为中抽象关系。从行为中抽象出来的基础关系,会是未来上层应用一个很重要的数据依赖。例如抽象出的兴趣、偏好、习惯等关系数据是推荐、个性化的基础生产资料。
在中间层,为了保证主题的完整性或提高数据的易用性,经常会进行适当的数据冗余。比如某一实事数据和两个主题相关但自身又没有成为独立主题,则会放在两个主题库中;为了提高单数据表的复用性和减少计算关联,通常会在事实表中冗余部分维度信息。
数据集市层

数据集市层是上下三层架构的最上层,通常是由需求场景驱动建设的,并且各集市间垂直构造。在数据集市层,我们可以深度挖掘数据价值。值得注意的是,数据集市层需要能够快速试错。
数据架构

数据架构包括数据整合、数据体系、数据服务三部分。其中,数据整合又可以分为结构化、半结构化、非结构化三类。
数据整合

结构化数据采集又可细分为全量采集、增量采集、实时采集三类。三种采集方式的各自特点和适应场合如上图所示,其中全量采集的方式最为简单;实时采集的采集质量最难控制。
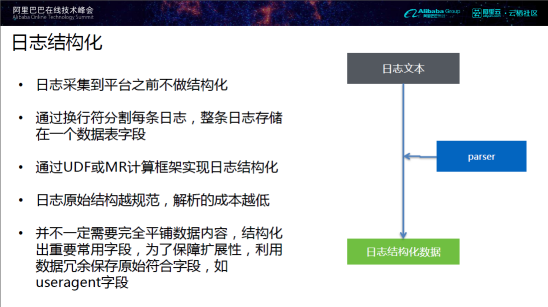
在传统的架构中,日志的结构化处理是放在数仓体系之外的。在大数据平台仓库架构中,日志在采集到平台之前不做结构化处理;在大数据平台上按行符分割每条日志,整条日志存储在一个数据表字段;后续,通过UDF或MR计算框架实现日志结构化。
在我们看来,日志结构越规范,解析成本越低。在日志结构化的过程中,并不一定需要完全平铺数据内容,只需结构化出重要常用字段;同时,为了保障扩展性,我们可以利用数据冗余保存原始符合字段(如useragent字段)。

非结构化的数据需要结构化才能使用。非结构化数据特征提取包括语音转文本、图片识别、自然语言处理、图片达标、视频识别等方式。尽管目前数仓架构体系中并不包含非结构化数据特征提取操作,但在未来,这将成为可能。
数据服务化

数据服务化包括统计服务、分析服务和标签服务:
-
统计服务主要是偏传统的报表服务,利用大数据平台将数据加工后的结果放入关系型数据库中,供前端的报表系统或业务系统查询;
-
分析服务用来提供明细的事实数据,利用大数据平台的实时计算能力,允许操作人员自主灵活的进行各种维度的交叉组合查询。分析服务的能力类似于传统cube提供的内容,但是在大数据平台下不需要预先建好cube,更灵活、更节省成本;
-
标签服务,大数据的应用场景下,经常会对主体进行特征刻画,比如客户的消费能力、兴趣习惯、物理特征等等,这些数据通过打标签转换成KV的数据服务,用于前端应用查询。
架构设计中一些实用的点

在架构设计中有一些实用的点,这里给大家分享一下:
第一,通过巧用虚拟节点实现多系统数据源同步,实现跨系统间的数据传输,实现多应用间数据交互。通过巧用虚拟节点减少运维人员在实际出现问题时的运维成本。
第二,采用强制分区,在所有的表都上都加上时间分区。通过分区,保证每个任务都能够独立重跑,而不产生数据质量问题,降低了数据修复成本;此外通过分区裁剪,还可以降低计算成本。

第三,应用计算框架完成日志结构化、同类数据计算过程等操作,减轻了开发人员的负担,同时更容易维护。
第四,优化关键路径。优化关键路径中耗时最长的任务是最有效的保障数据产出时间的手段。
数据治理
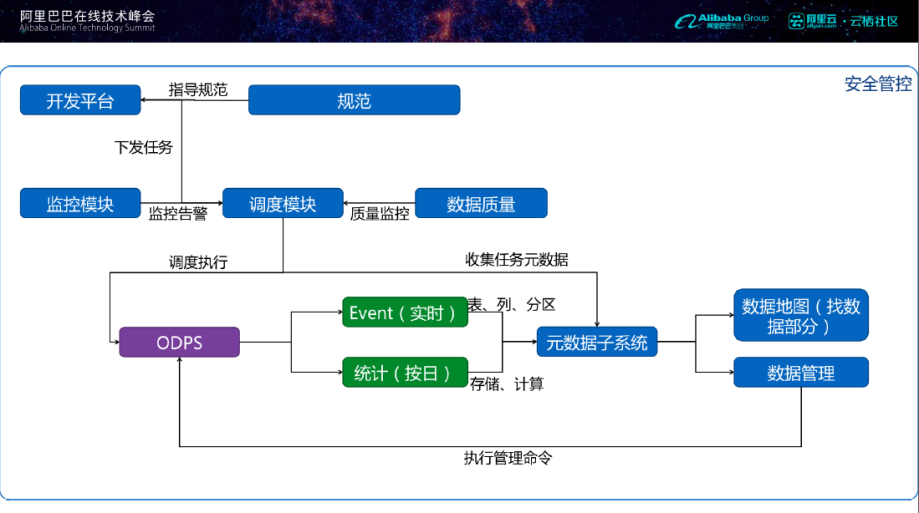
数据治理不是独立于系统之外的保障,它应该贯穿在数仓架构内部和数据处理的流程之中。
数据质量
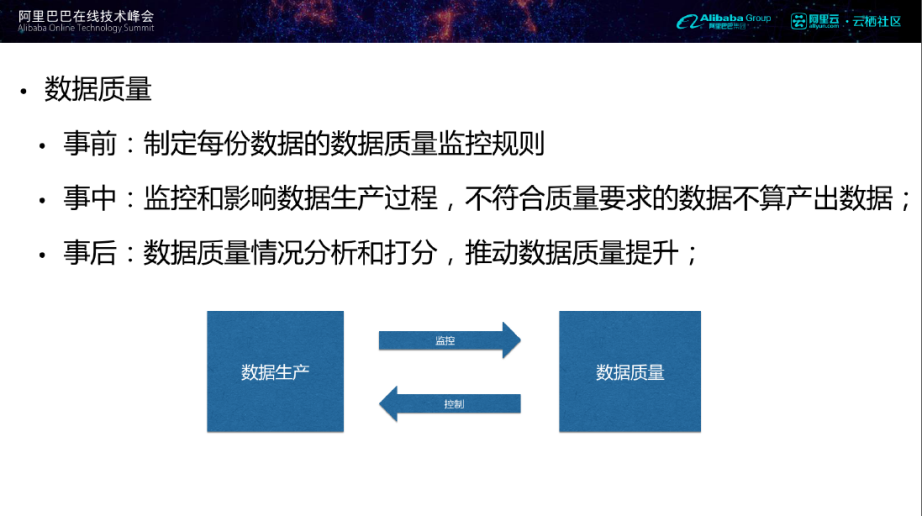
保障数据质量,可以从事前、事中、事后入手。事前,我们可以通过制定每份数据的数据质量监控规则,越重要的数据对应的监控规则应该越多;事中,通过监控和影响数据生产过程,对不符合质量要求的数据进行干预,使其不影响下流数据的质量;事后,通过对数据质量情况进行分析和打分,将一些不足和改进反馈数据监控体系,推动整体的数据质量提升。
数据生命周期管理

出于成本等因素的考虑,在大数据平台上我们依然需要对数据生命周期进行管理。根据使用频率将数据分为冰、冷、温、热四类。一个合理的数据生命周期管理要保证温热数据占整个数据体系大部分;同时为了保障数据资产的完整性,对于重要的基础数据会长久保留。
对于数据中间计算过程数据,在保障满足绝大部分应用访问历史数据需要的前提下,缩短数据保留周期,有助于降低存储成本;最后一点值得注意的是,冷备已经成为历史,在大数据平台下不需要单独的冷备设备。
关于分享嘉宾:
李金波,阿里云高级技术专家,8年以上互联网数据仓库经历,对系统架构、数据架构拥有丰富的实战经验,曾经数据魔方、淘宝指数的数据架构设计专家。现任阿里云大数据数仓解决方案总架构师。