本节内容:
1.前言
2.相关概念
3.python中默认编码
4。python2与python3中对字符串的支持
5.字符编码转换
6.unicode、utf-8、gbk综合
一、前言
python2 默认编码是ASCII码,不能识别中文,需显示指定字符编码,python3默认编码为unicdoe,可以识别中文
二、相关概念
1.字符与字节
一个字符不等于一个字节,字符是人类能够识别的符号,符号保存到计算机的存储中需要计算机能够识别的字节表示,一个字符有多种表示方法,不同的表示方法会使用不同的字节数,这里所说的表示方法是指字符编码。例字母A用ASCII码表示占一个字节,用UNICDE表示占两个字节,用UTF-8表示占用一个字节,字符编码的作用是将人类可是不的字符转换为机器可识别的字节码,以及反过程。
UNICODE才是真正的字符串,而用ASCII、UTF-8、GBK等字符编码表示的是字节串。
对字符串取长度,结果应该是所有字符串的个数,无论是中文还是英文
对字符串对应的字符串取长度,跟编码过程使用的字符编码有关(UTF-8编码一个中文需要3个字节表示,GBK编码需要2个字节表示
#Python2
#coding=utf-8
a = "hello,中国" #字节串,长度为字节个数:len('hello,')+len('中国') = 6 + 2*3 =12
b = u"hello,中国"#字符串,长度为字符串的个数:len('hello,')+len('中国') = 6 + 2=8
c = unicode(a,"utf-8") #字符串,长度为字符串的个数:len('hello,')+len('中国') = 6 + 2=8
print (type(a),len(a))
print (type(b),len(b))
print (type(c),len(c))
运行结果:
(<type 'str'>, 12)
(<type 'unicode'>, 8)
(<type 'unicode'>, 8)
注意:Windows的cmd终端字符编码默认为GBK,因此在cmd输入的中文字符需要用两个字节表示
2.编码与解码
UNICODE字符编码,是一张字符与数字的映射,数字为16进制的数字
编码(encode):将UNICODE字符串(中的代码点)转换成特定的字符编码对象的字节串的过程和规则
解码(decode):将特定字符编码的字节串转换成对应的UNICODE字符串的过程和规则
可见,无论是编码还是解码,都需要一个重要因素,就是特定的字符编码。因为一个字符用不同的字符编码进行编码后的字节值以及字节个数大部分情况下是不同的,反之亦然。
三、python中的默认编码
1.python源代码执行过程
磁盘上的文件以二进制格式存放,文本文件以某种特定编码的字节形式存放。程序源代码的文件字符编码有编辑器指定,比如我们使用Pycharm来编写Python程序时会指定工程编码和文件编码为UTF-8,那么Python代码被保存到磁盘时就会被转换为UTF-8编码对应的字节(encode过程)后写入磁盘,Python解释器在读取Python代码文件中的字节串之后,需要将其转换为UNICODE字符串(decode过程)之后才执行后续操作。
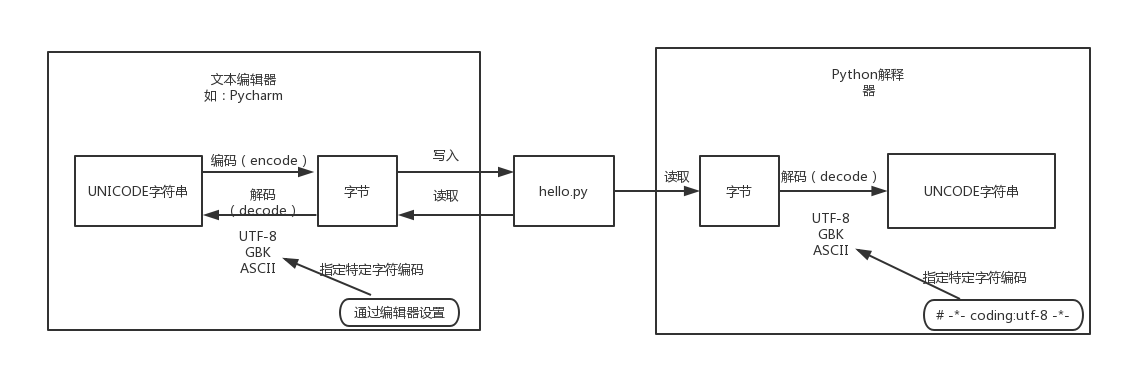
2.默认编码
python2,python解释器读取中文字符的字节码尝试解码操作时,会先查看当前文件头部指明当前文件中保存的字节码对应的字符编码,没有使用就使用默认字符编码“ASCII”进行解码
3.最佳实践
创建一个工程之后先确认该工程的字符编码是否已经设置为UTF-8
为了兼容Python2和Python3,在代码头部声明字符编码:#coding=utf-8
四、python2 与 python3对字符串的支持
python2
python2对字符串的支持由以下三个类:
class basesring(object)
class str(basestring)
class unicode(basestring)
执行help(str)和help(bytes)结果都是str类的定义,python2中str是字节串,unicode对象才是真正的字符串
python3
class str(object)
class str(basestring)
class unicode(basestring)
python3开始明确的区分字符串与字节。python3中的str已经是真正的字符串,而字节是用单独的bytes类来表示。也就是说,python3默认定义的就是字符串,实现了对UNICODE的内置支持,减轻了程序员对字符串处理的负担。
#!/usr/bin/env python # -*- coding:utf-8 -*- a = '你好' b = u'你好' c = '你好'.encode('gbk') print(type(a), len(a)) print(type(b), len(b)) print(type(c), len(c))
输出结果:
<class 'str'> 2
<class 'str'> 2
<class 'bytes'> 4
五、字符编码转换
UNICODE字符串可以喝任意字符编码进行互相转换
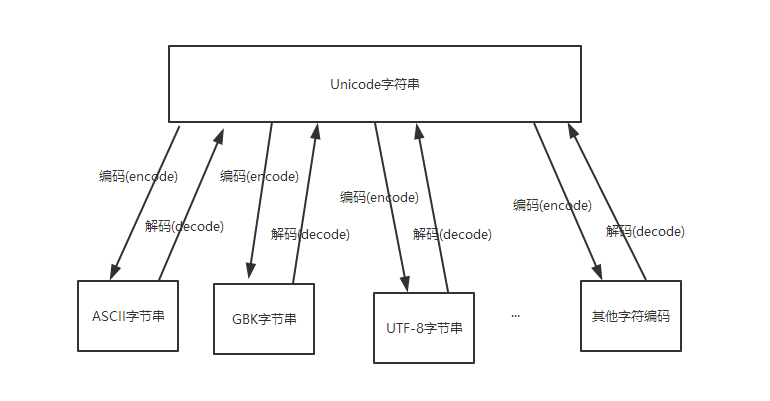
python2中的字符串进行编码转换过程是:
字符串-》decode("原来的字符编码")--》UNICODE字符串-》encode(“新的字符编码”)-》字符串
#coding=utf-8
utf_8_a = "hello,中国"
gbk_a = utf_8_a.decode("utf-8").encode("gbk")
print gbk_a
print gbk_a.decode("gbk")
python3中订单的字符串默认就是UNICODE,不需要解码,可以直接编码成新的字符编码:
字符串-->encode('新的字符编码')-->字节串
utf_8_a = '我爱中国'
gbk_a = utf_8_a.encode('gbk')
print(gbk_a.decode('gbk'))
六、unicode、utf-8、gbk综合
#coding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
file_content = "中国"
unicode_content = file_content.decode("utf-8")
utf_content = unicode_content.encode("utf-8")
gbk_content = unicode_content.encode("gbk")
print "file_content:{file_content},type(file_content):{file_content_type},len(file_content)):{file_content_len}".format(file_content = file_content,file_content_type = type(file_content), file_content_len = len(file_content))
print "unicode_content:{unicode_content},type(unicode_content):{unicode_content_type},len(unicode_content)):{unicode_content_len}".format(unicode_content = unicode_content,unicode_content_type = type(unicode_content), unicode_content_len = len(unicode_content))
print "utf_content:{utf_content},type(utf_content):{utf_content_type},len(utf_content)):{utf_content_len}".format(utf_content = utf_content,utf_content_type = type(utf_content), utf_content_len = len(utf_content))
print "gbk_content:{gbk_content},type(gbk_content):{gbk_content_type},len(gbk_content)):{gbk_content_len}".format(gbk_content = gbk_content,gbk_content_type = type(gbk_content), gbk_content_len = len(gbk_content))
运行结果:
file_content:中国,type(file_content):<type 'str'>,len(file_content)):6
unicode_content:中国,type(unicode_content):<type 'unicode'>,len(unicode_content)):2
utf_content:中国,type(utf_content):<type 'str'>,len(utf_content)):6
gbk_content:�й�,type(gbk_content):<type 'str'>,len(gbk_content)):4