一.写在前面的话~
刚吃饭的时候同学问我,你为什么要用R做文本分析,你不是应该用R建模么,在我和她解释了一会儿后,她嘱咐我好好写这篇博文,嗯为了娟儿同学,细细说一会儿文本分析。
文本数据挖掘(Text Mining)是指从文本数据中抽取有价值的信息和知识的计算机处理技术。顾名思义,文本数据挖掘是从文本中进行数据挖掘(Data Mining)。从这个意义上讲,文本数据挖掘是数据挖掘的一个分支。
文本分析是指对文本的表示及其特征项的选取;文本分析是文本挖掘、信息检索的一个基本问题,它把从文本中抽取出的特征词进行量化来表示文本信息。
在拉勾网上搜索文本分析的相关工作,甚至还会发现专门招聘这方面人才的公司(并且大部分都是目前来说高不可攀的公司。。)。
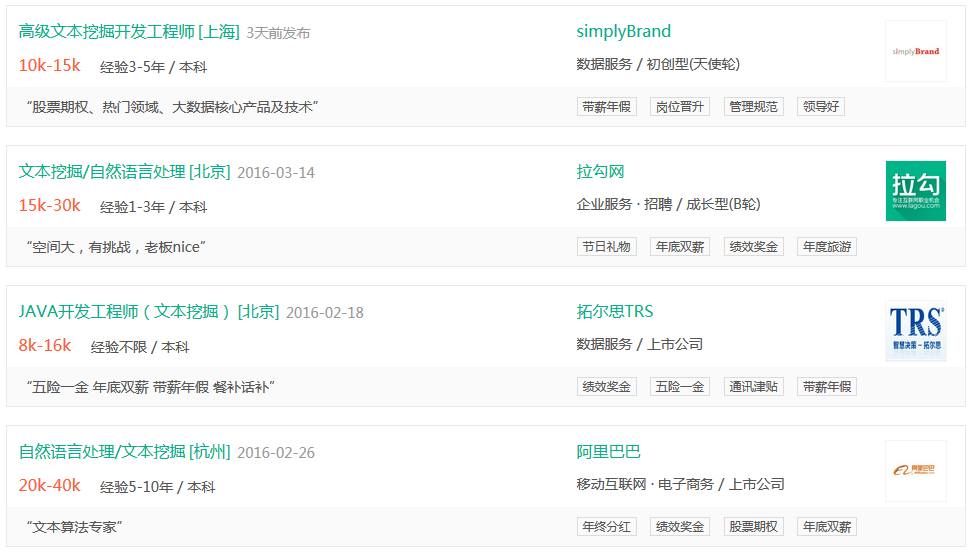
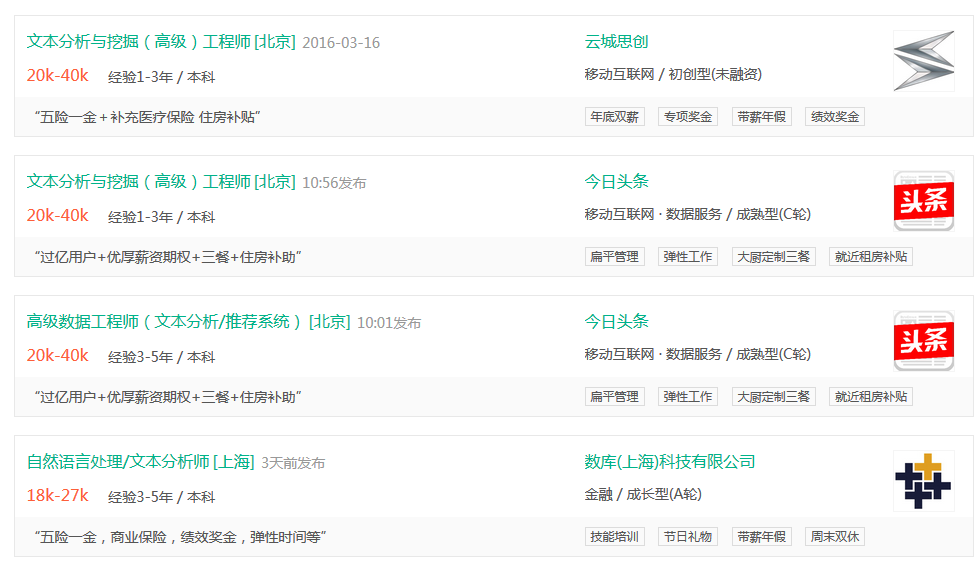
随便进入了一个职位,看其要求:

编程能力、文本挖掘项目经验、大规模数据处理或统计基础。。瞬间觉得自己弱爆了有木有!!
再找一下相关的文献,不要再说文本分析和统计学没有关系啦~
博主刚刚接触R语言和文本分析,所以只是试探了一下下皮毛,为了将二者结合,试着对《红楼梦》进行分析,首先对《红楼梦》进行分词处理,并统计词频,同时画出标签云。
闲话的最后,大家一起翻译这篇文章好不好233
http://jmlr.org/proceedings/papers/v37/kusnerb15.pdf
二.利用R对《红楼梦》进行分析
(一)需要加载的包
需要用到rJava,Rwordseg,wordcloud
安装步骤:
1.安装java:
http://www.java.com/zh_CN/download/windows_xpi.jsp
2.安装rJava:
在R的命令框输入
install.packages("rJava")
错误解决方案:
错误1.错误: ‘rJava’程辑包或名字空间载入失败,
解决方案:换路径
错误2.

解决方案:
在R中输入
Sys.setenv(JAVA_HOME='C:/Program Files/Java/jre1.8.0_73') #注意:要根据你的java路径更改

3.安装Rwordseg:
下载地址:
https://r-forge.r-project.org/R/?group_id=1054
 点这儿下载Rwordseg
点这儿下载Rwordseg
解压后将文件放入R下library文件夹下
4.安装wordcloud
在R的命令框输入
install.packages("wordcloud")
利用Rwordseg分词包进行分词
(二)分析过程
1.基础导入
library(rJava)
library(Rwordseg)
library(RColorBrewer)
library(wordcloud)
2.读入数据
将需要分析的文本放入记事本中,保存到相应路径,并在R中打开。这儿我导入的是《红楼梦》的文本。
lecture<-read.csv("E:/Rtagcloud/hongloumeng.txt", stringsAsFactors=FALSE,header=FALSE)
3.优化词库
对于文言文和人物名字分词结果不是很理想的问题,有一个很好的解决方案,就是导入搜狗细胞词库(http://pinyin.sogou.com/dict/),以本例作为例子,分别导入了文言文常用词库、红楼梦常用词库、红楼梦成员名字词库,这三个词库,让分词效果更为理想。
installDict("C:\Users\Administrator\Desktop\红楼梦词汇大全.scel","hongloumeng1") installDict("C:\Users\Administrator\Desktop\红楼梦群成员名字词库.scel","hongloumeng2") installDict("C:\Users\Administrator\Desktop\红楼梦词汇.scel","hongloumeng3")
为了让大家更直观的理解优化词库,举如下例子:
先导入rJava和Rwordseg两个包
library(rJava)
library(Rwordseg)
利用Rwordseg对“朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不尽,轻舟已过万重山。”进行分词,结果如下
接着到http://pinyin.sogou.com/dict/detail/index/22394 下载李白诗集的细胞词库,并把它放到E盘,在R中输入以下代码安装词典:
installDict("e:/李白诗集.scel","libai")
安装好后,输入同样的代码,结果如下
可见利用细胞词库可以得到更好的分词结果。
4.分词+统计词频
words=unlist(lapply(X=res, FUN=segmentCN)) #unlist将list类型的数据,转化为vector #lapply()返回一个长度与X一致的列表,每个元素为FUN计算出的结果,且分别对应到X中的每个元素。 word=lapply(X=words, FUN=strsplit, " ") v=table(unlist(word)) #table统计数据的频数
结果v的部分截图如下,可以看出此时已经统计好词频了:
5.对词频进行排序
# 降序排序 v=rev(sort(v))
6.创建数据框
d=data.frame(词汇=names(v), 词频=v)
7.过滤掉1个字的结果和词频小于100的结果
筛选标准大家可以根据自己的需求进行修改
d=subset(d, nchar(as.character(d$词汇))>1 & d$词频>=100)
8.词频结果输出
根据自己的具体需求改变路径和文件名称
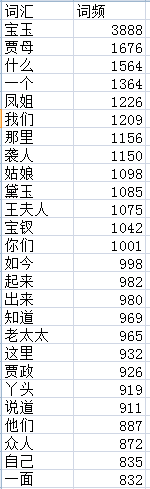
write.csv(d, file="E:/Rtagcloud/hongloumengfcresult.csv", row.names=FALSE)
词频统计结果(节选)如下:
9.画出标签云
(1)读入词频统计数据
路径和文件名称根据自己的需求更改
mydata<-read.csv("E:/Rtagcloud/hongloumengfcresult.csv",head=TRUE)
(2)设置字体类型和字体颜色
mycolors <- brewer.pal(12,"Paired") windowsFonts(myFont=windowsFont("锐字巅峰粗黑简1.0"))
字体下载地址:
http://www.zhaozi.cn/
大家可以根据自己的喜好选择喜欢的字体
brewer.pal配色如下,大家可以根据喜好选择:

(3)画出标签云
wordcloud(mydata$词汇,mydata$词频,random.order=FALSE,random.color=TRUE,colors=mycolors,family="myFont")


所有代码:
library(rJava) library(Rwordseg) library(RColorBrewer) library(wordcloud) #读入数据 lecture<-read.csv("E:/Rtagcloud/hongloumeng.txt", stringsAsFactors=FALSE,header=FALSE) #文本预处理 res=lecture[] #分词+频数统计 installDict("E:\红楼梦词汇大全.scel","hongloumeng1") installDict("E:\红楼梦群成员名字词库.scel","hongloumeng2") installDict("E:\红楼梦词汇.scel","hongloumeng3") words=unlist(lapply(X=res, FUN=segmentCN)) #unlist将list类型的数据,转化为vector #lapply()返回一个长度与X一致的列表,每个元素为FUN计算出的结果,且分别对应到X中的每个元素。 word=lapply(X=words, FUN=strsplit, " ") v=table(unlist(word)) #table统计数据的频数 # 降序排序 v=rev(sort(v)) d=data.frame(词汇=names(v), 词频=v) #创建数据框 #过滤掉1个字和词频小于200的记录 d=subset(d, nchar(as.character(d$词汇))>1 & d$词频>=100) #输出结果 write.csv(d, file="E:/Rtagcloud/hongloumengfcresult.csv", row.names=FALSE) #画出标签云 mydata<-read.csv("E:/Rtagcloud/hongloumengfcresult.csv",head=TRUE) mycolors <- brewer.pal(12,"Paired") windowsFonts(myFont=windowsFont("锐字巅峰粗黑简1.0")) wordcloud(mydata$词汇,mydata$词频,random.order=FALSE,random.color=TRUE,colors=mycolors,family="myFont")
以下是博主画的其它标签云(对啦对啦就是上瘾啦233):
《时间简史》


这只是很简单很简单的文本分析入门,继续努力~