snownlps是用Python写的个中文情感分析的包,自带了中文正负情感的训练集,主要是评论的语料库。使用的是朴素贝叶斯原理来训练和预测数据。主要看了一下这个包的几个主要的核心代码,看的过程作了一些注释,记录一下免得以后再忘了。
1. sentiment文件夹下的__init__.py,主要是集成了前面写的几个模块的功能,进行打包。
1 # -*- coding: utf-8 -*- 2 from __future__ import unicode_literals 3 4 import os 5 import codecs 6 7 from .. import normal 8 from .. import seg 9 from ..classification.bayes import Bayes 10 11 data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 12 'sentiment.marshal') 13 14 15 class Sentiment(object): 16 17 def __init__(self):# 实例化Bayes()类作为属性,下面的很多方法都是调用的Bayes()的方法完成的 18 self.classifier = Bayes() 19 20 def save(self, fname, iszip=True):# 保存最终的模型 21 self.classifier.save(fname, iszip) 22 23 def load(self, fname=data_path, iszip=True): 24 self.classifier.load(fname, iszip)# 加载贝叶斯模型 25 26 # 分词以及去停用词的操作 27 def handle(self, doc): 28 words = seg.seg(doc)# 分词 29 words = normal.filter_stop(words)# 去停用词 30 return words# 返回分词后的结果,是一个list列表 31 32 def train(self, neg_docs, pos_docs): 33 data = [] 34 for sent in neg_docs:# 读入负样本 35 data.append([self.handle(sent), 'neg']) 36 # 所以可以看出进入bayes()的训练的数据data格式是[[[第一行分词],类别], 37 # [[第二行分词], 类别], 38 # [[第n行分词],类别] 39 # ] 40 for sent in pos_docs: # 读入正样本 41 data.append([self.handle(sent), 'pos']) 42 self.classifier.train(data) # 调用的是Bayes模型的训练方法train() 43 44 def classify(self, sent): 45 ret, prob = self.classifier.classify(self.handle(sent))#得到分类结果和概率 46 if ret == 'pos':#默认返回的是pos('正面'),否则就是负面 47 return prob 48 return 1-prob 49 50 51 classifier = Sentiment()#实例化Sentiment()对象 52 classifier.load() 53 54 55 def train(neg_file, pos_file): 56 #读取正负语料库文本 57 neg_docs = codecs.open(neg_file, 'r', 'utf-8').readlines() 58 pos_docs = codecs.open(pos_file, 'r', 'utf-8').readlines() 59 global classifier#声明classifier为全局变量,下面重新赋值,虽然值仍然是Sentiment()函数 60 classifier = Sentiment() 61 classifier.train(neg_docs, pos_docs)#调用Sentment()模块里的train()方法 62 63 64 def save(fname, iszip=True): 65 classifier.save(fname, iszip) 66 67 68 def load(fname, iszip=True): 69 classifier.load(fname, iszip) 70 71 72 def classify(sent): 73 return classifier.classify(sent)
2.使用的朴素贝叶斯原理及公式变形
推荐一篇解释得很好的文章:情感分析——深入snownlp原理和实践

classification文件夹下的Bayes.py模块主要包含两个方法train(data)和classify(X),训练和预测方法
1 # 训练数据集 2 # 训练的数据data格式是[[['分词1','分词2','分词x'],类别], 3 # [[第二行分词], 类别], 4 # [[第n行分词],类别] 5 # ] 6 def train(self, data):#训练后得到的self.d={'neg':AddOneProb,'pos':AddOneProb},AddOneProb包含重要的分词信息,他里面也有一个self.d={'分词1':v1,'分词2':v2,'分词3':v3,...}包含分词和相应的分词个数。 7 8 # 遍历数据集 9 for d in data: 10 # d[1]标签-->分类类别 11 c = d[1] 12 # 判断数据字典中是否有当前的标签 13 if c not in self.d: 14 # 如果没有该标签,加入标签,值是一个AddOneProb对象。其实就是为每个分词建一个AddOnePro对象来计数 15 self.d[c] = AddOneProb() 16 # d[0]是评论的分词list,遍历分词list 17 for word in d[0]: 18 # 调用AddOneProb中的add方法,添加单词 19 self.d[c].add(word, 1)#self.d[c]是AddOneProb对象,调用AddOneProb的add()函数来对词word计数,重点看frequency.py中的几个类 20 # 计算总词数 21 self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys()))#self.d[x].getsum()是调用AddOneProb对象的getsum()函数计算词 22 23 #对句子x分类,而x是被分过词的列表,(将句子分词的步骤会在Sentiment类中的分类函数classify()执行,这里不要管,只要知道x是分词后的的列表) 24 def classify(self, x): 25 tmp = {} 26 # 遍历每个分类标签,本案例中只有两个类别 27 for k in self.d: 28 tmp[k] = log(self.d[k].getsum()) - log(self.total)#计算先验概率,即p(neg)和p(pos)两个类别的概率 29 for word in x: 30 tmp[k] += log(self.d[k].freq(word))#计算后验概率,即每个类别条件下某个分词的概率p('词A'|neg)和p('词A'|pos),# 词频,词word不在字典里的话就为0 31 ret, prob = 0, 0 32 for k in self.d:#遍历两个类 33 now = 0#预测值赋初值为0 34 try: 35 for otherk in self.d:#当类相同时now=1,类不同时now累加exp(tmp[otherk]-tmp[k]),最终计算now为变形后的朴素贝叶斯预测值的分母 36 now += exp(tmp[otherk]-tmp[k])#朴素贝叶斯变形式可见博客 37 now = 1/now#求倒数为得到的这个类的预测值 38 except OverflowError: 39 now = 0 40 if now > prob:#比较两个类别的概率谁大,大的就是这个文本的类别。注意:初始prob等于0,经过遍历后悔更新prob并且prob等于相应类别的朴素贝叶斯概率 41 ret, prob = k, now 42 return (ret, prob) 43 #这里用朴素贝叶斯方法计算
注意:classify()方法中的朴素贝叶斯变形方法的编写,下面两个for循环,先是遍历两个类,比例第一个类,now表示对这个类计算的贝叶斯预测值,赋初值为0,第二个循环遍历第一个类(otherk=k),
exp(tmp[otherk]-tmp[k])=exp(0)=1,则now=1,再遍历第二个类得到上面变形公式中的第二部分值,这两个相加得到的new就是
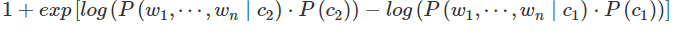
最后再倒数就得到了
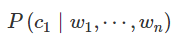
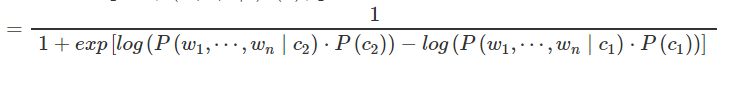
再附加一个上面的AddOneProb()方法的源代码解析,他就是一个对输入的分词计数的函数,将语料库的词进行分类计数,为了训练做得到先后验概率准备:
1 '''对词计算频数''' 2 class BaseProb(object): 3 4 def __init__(self): 5 self.d = {}#用来存储分词和分词的个数,键是分词,值是分词的个数 6 self.total = 0.0#计数总共的词个数 7 self.none = 0 8 9 def exists(self, key):#判断字典self.d中是否存在这个词key 10 return key in self.d 11 12 def getsum(self):#返回语self.d中存储的词的总数 13 return self.total 14 15 def get(self, key):#判断字典中是否存在这个词key,并且返回这分词的词个数 16 if not self.exists(key): 17 return False, self.none 18 return True, self.d[key] 19 20 def freq(self, key):#计算词key的频率 21 return float(self.get(key)[1])/self.total 22 23 def samples(self):#返回字典的键,其实就是返回所有的分词,以列表形式 24 return self.d.keys() 25 26 27 class NormalProb(BaseProb): 28 29 def add(self, key, value): 30 if not self.exists(key): 31 self.d[key] = 0 32 self.d[key] += value 33 self.total += value 34 35 36 '''对词计数''' 37 class AddOneProb(BaseProb):#继承BaseProb类,所以BaseProb类中的属性和函数都能用。 38 39 def __init__(self): 40 self.d = {} 41 self.total = 0.0 42 self.none = 1 43 44 def add(self, key, value): 45 self.total += value#计算总词数 46 if not self.exists(key):#如果这个词key不在self.d中的话,那么在字典中加上这个词,即键为此,并且给这个词计数1,同时总的词数量total加1. 47 self.d[key] = 1 48 self.total += 1#感觉不应该再加1了,上面都已经计算过总数了????说是后面预测要用到,可能是要平滑 49 self.d[key] += value#如果字典已经有这个词了的话,那么给这个词数量加1
对于局进行分词的方法Handle()感觉也很重要,也需要看一看。