flink architecture

1.flink可以运行在本地,也可以类似spark一样on yarn或者standalone模式(与spark standalone也很相似)
2.Runtime部分是flink的核心数据处理引擎,他将我们通过api编程的程序生成任务图(JobGraph),任务图是一个并行的数据流,含有tasks来生产和消费数据。
3.dataStrem api是用于流式处理,dataset api是用于批量处理,而任务图也就是由这些api编写的代码生成的。dataset api 最后也会有优化器来生成优化后的执行计划。根据实际的部署模式,优化后的jobGraph将被
提交到excutors执行。
Flink 分布式程序执行
flink程序在执行时候的三个重要的部分:job client、job manager、task manager。详见官网
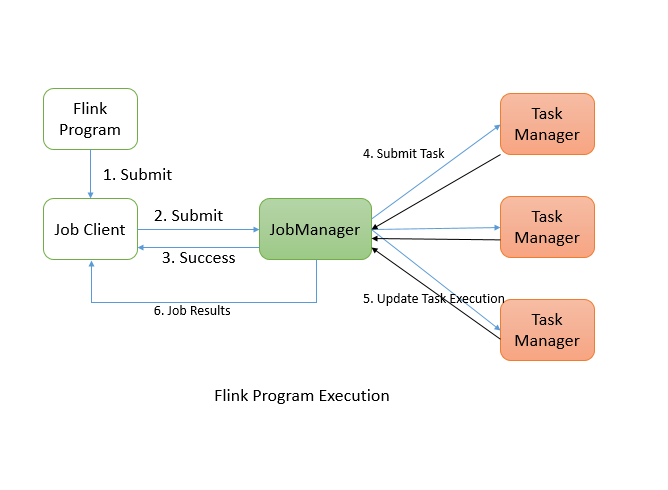
flink 程序提交之后,会首先提交给job client,然后job client提交任务给job manager,job manager负责资源分配,资源分配完成以后,将task提交给各自的task manager,task manager在接收到task之后,将初始化线程来执行task,并且task manager会持续跟进报告task执行状态给job manager,比如task 开始运行、正在处理、处理完成。
job manager协调和管理程序执行,其主要任务包括调度任务,断点(checkpoint)管理,故障恢复等等。job manager一样也可以启动多个做成HA的形式,其中active的为leader,其他为standby。
job manager几个重要的部分:actor system、scheduler、check pointing,flink内部使用的是akka actor system来负责job manager和task manager之间的通信。
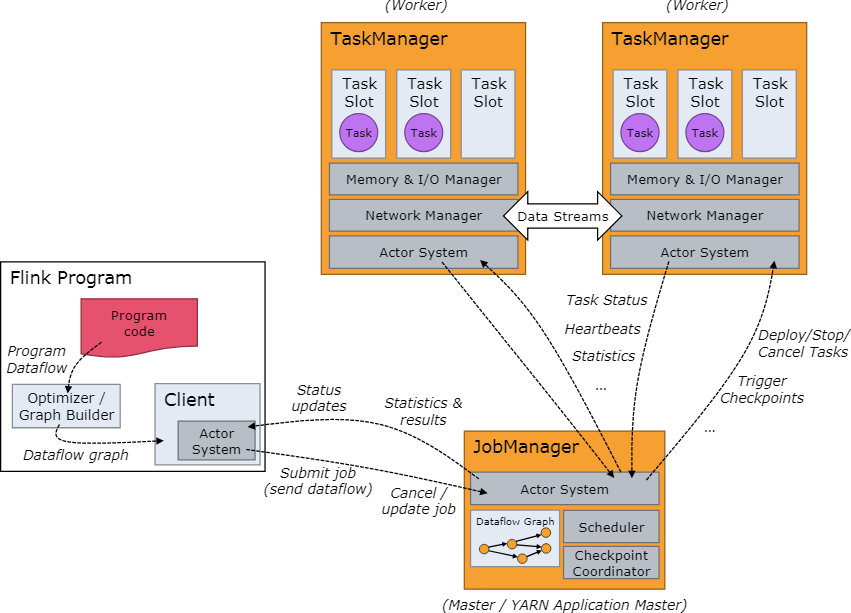
关于scheduler:
在flink中,executor被定义为task slots,每个task manager需要管理一个或多个task slots,flink通过slotShareGroup和coLocationGroup来分配哪些tasks共同使用一个task slot或者哪些task必须放置在特殊的slot中。
关于check pointing:
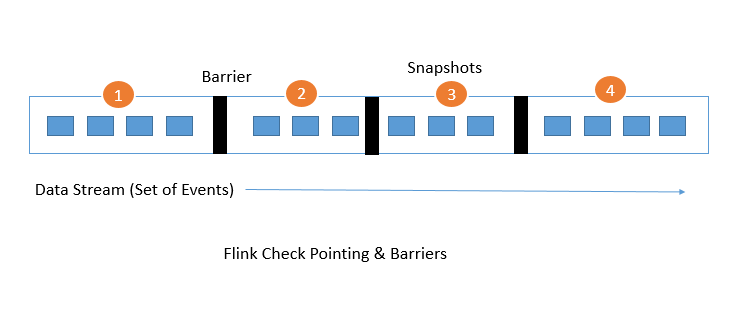
check pointing是flink用于容错的核心部分,check pointing容错机制是通过持续的对分布式数据流以及executor的状态做轻量级的快照来实现(这种方式是基于Chandy-Lamport算法做的,但是flink对其做了部分修改),快照可以配置存放到hdfs上,如果程序发生了故障,flink会重启executors,然后从最新可用的checkpoint开始执行。如下图:
task manager:
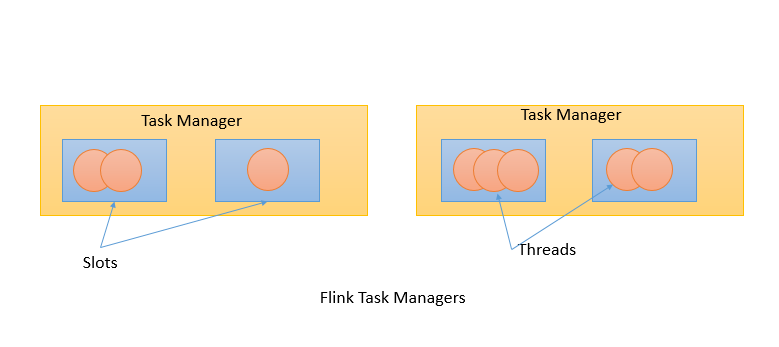
task manager是 work nodes,在jvm中通过一个或者多个线程来执行task,跟spark很相似。
一个 TaskManger 就是一个 JVM 进程,并且会用独立的线程来执行 task,为了控制一个 TaskManger 能接受多少个 task,Flink 提出了 Task Slot 的概念。
我们可以简单的把 Task Slot 理解为 TaskManager 的计算资源子集。假如一个 TaskManager 拥有 5 个 slot,那么该 TaskManager 的计算资源会被平均分为 5 份,不同的 task 在不同的 slot 中执行,避免资源竞争。但是需要注意的是,slot 仅仅用来做内存的隔离,对 CPU 不起作用。那么运行在同一个 JVM 的 task 可以共享 TCP 连接,减少网络传输,在一定程度上提高了程序的运行效率,降低了资源消耗。
job client:
job client不属于flink程序执行内的一部分,但是他是程序开始执行的启动点,job client负责接收用户编程的代码,然后创建数据流(data flow)并提交data flow给job manager来进一步的执行,。一旦程序执行完成,job client将执行结果返回给用户
data flow代表执行计划,比如word count:
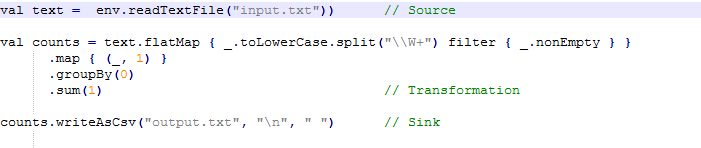
job client将其转成data flow,对于wordcount这个程序的data flow大概是下面这个样子:
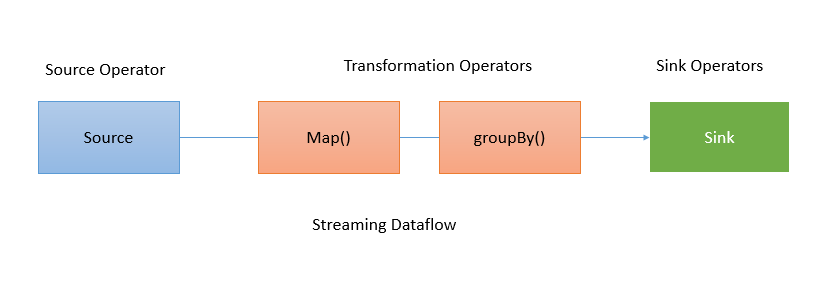
对于map这种算子,不存在shuffle,但是对于groupBy来说,需要shuffle数据,那么详细的图大概就是下面这个样子:

架构
Stom 的架构是经典的主从模式,并且强依赖 ZooKeeper;Spark Streaming 的架构是基于 Spark 的,它的本质是微批处理,每个 batch 都依赖 Driver,我们可以把 Spark Streaming 理解为时间维度上的 Spark DAG。
Flink 也采用了经典的主从模式,DataFlow Graph 与 Storm 形成的拓扑 Topology 结构类似,Flink 程序启动后,会根据用户的代码处理成 Stream Graph,然后优化成为 JobGraph,JobManager 会根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 才是 Flink 真正能执行的数据结构,当很多个 ExecutionGraph 分布在集群中,就会形成一张网状的拓扑结构。
容错
Storm 在容错方面只支持了 Record 级别的 ACK-FAIL,发送出去的每一条消息,都可以确定是被成功处理或失败处理,因此 Storm 支持至少处理一次语义。
针对以前的 Spark Streaming 任务,我们可以配置对应的 checkpoint,也就是保存点。当任务出现 failover 的时候,会从 checkpoint 重新加载,使得数据不丢失。但是这个过程会导致原来的数据重复处理,不能做到“只处理一次”语义。
Flink 基于两阶段提交实现了精确的一次处理语义。
反压是分布式处理系统中经常遇到的问题,当消费者速度低于生产者的速度时,则需要消费者将信息反馈给生产者使得生产者的速度能和消费者的速度进行匹配。
Stom 在处理背压问题上简单粗暴,当下游消费者速度跟不上生产者的速度时会直接通知生产者,生产者停止生产数据,这种方式的缺点是不能实现逐级反压,且调优困难。设置的消费速率过小会导致集群吞吐量低下,速率过大会导致消费者 OOM。
Spark Streaming 为了实现反压这个功能,在原来的架构基础上构造了一个“速率控制器”,这个“速率控制器”会根据几个属性,如任务的结束时间、处理时长、处理消息的条数等计算一个速率。在实现控制数据的接收速率中用到了一个经典的算法,即“PID 算法”。
Flink 没有使用任何复杂的机制来解决反压问题,Flink 在数据传输过程中使用了分布式阻塞队列。我们知道在一个阻塞队列中,当队列满了以后发送者会被天然阻塞住,这种阻塞功能相当于给这个阻塞队列提供了反压的能力。
安装Flink standalone集群
1.下载flink https://flink.apache.org/downloads.html
2.官网参考 https://ci.apache.org/projects/flink/flink-docs-release-1.8/ops/deployment/cluster_setup.html
另外,如果已有hadoop平台,并且想使用flink读写hadoop上的数据,那要下载相对应的兼容hadoop的jar包

2.安装JDK8、配置ssh免密

3. 选择节点作为master(job manager)和slave(task manage)
比如这里有三个节点,其中10.0.0.1为master,其他两个为slaves,右边为相关配置应设置的内容

4.修改配置文件 flink-1.8.2/conf/flink-conf.yaml
相关的配置,端口号,内存根据实际配置调整,此外还可以在此文件中export JAVA_HOME=/path/to/you
jobmanager.rpc.address: master01.hadoop.xxx.cn # The RPC port where the JobManager is reachable. jobmanager.rpc.port: 6123 # The heap size for the JobManager JVM jobmanager.heap.size: 1024m # The heap size for the TaskManager JVM taskmanager.heap.size: 1024m # The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.每台机器可用的cpu数量,如果只是计算集群,16核的服务器可以配置14个,留2个给系统 taskmanager.numberOfTaskSlots: 1 # The parallelism used for programs that did not specify and other parallelism.默认情况下task的并行度 parallelism.default: 1
比较重要的配置参数(完整配置参数详解可参加官网链接):
the amount of available memory per JobManager (jobmanager.heap.mb), the amount of available memory per TaskManager (taskmanager.heap.mb), the number of available CPUs per machine (taskmanager.numberOfTaskSlots), the total number of CPUs in the cluster (parallelism.default) and the temporary directories (io.tmp.dirs)
5.修改配置文件 flink-1.8.2/conf/masters和slaves
masters文件:指定master所在节点以及端口号
master01.hadoop.xxx.cn:8081
slavers文件:指定slavers所在节点
worker01.hadoop.xxx.cn
worker02.hadoop.xxx.cn
6. 分发flink包到各个节点
scp .....
7. 启动standalone集群
bin/start-cluster.sh
查看状态:
在master节点jps
50963 StandaloneSessionClusterEntrypoint
在work节点jps
3509 TaskManagerRunner
查看ui界面
http://master01.hadoop.xxx.cn:8081
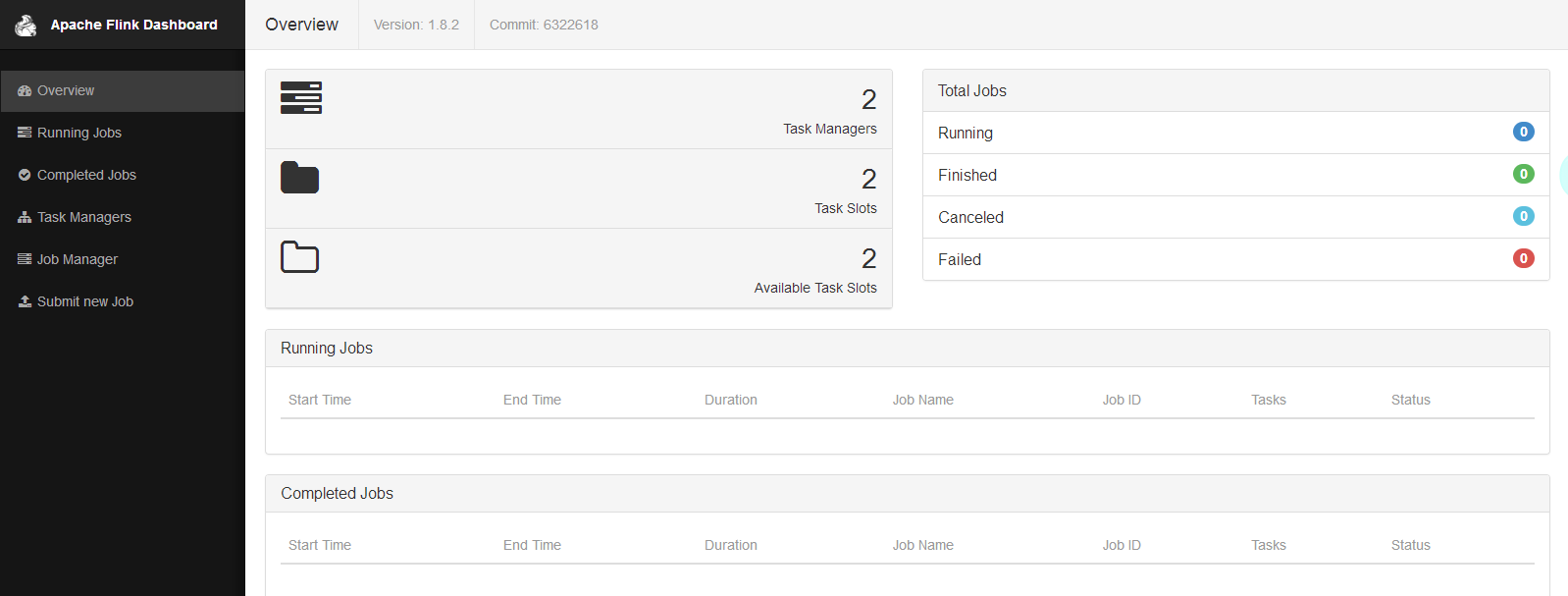
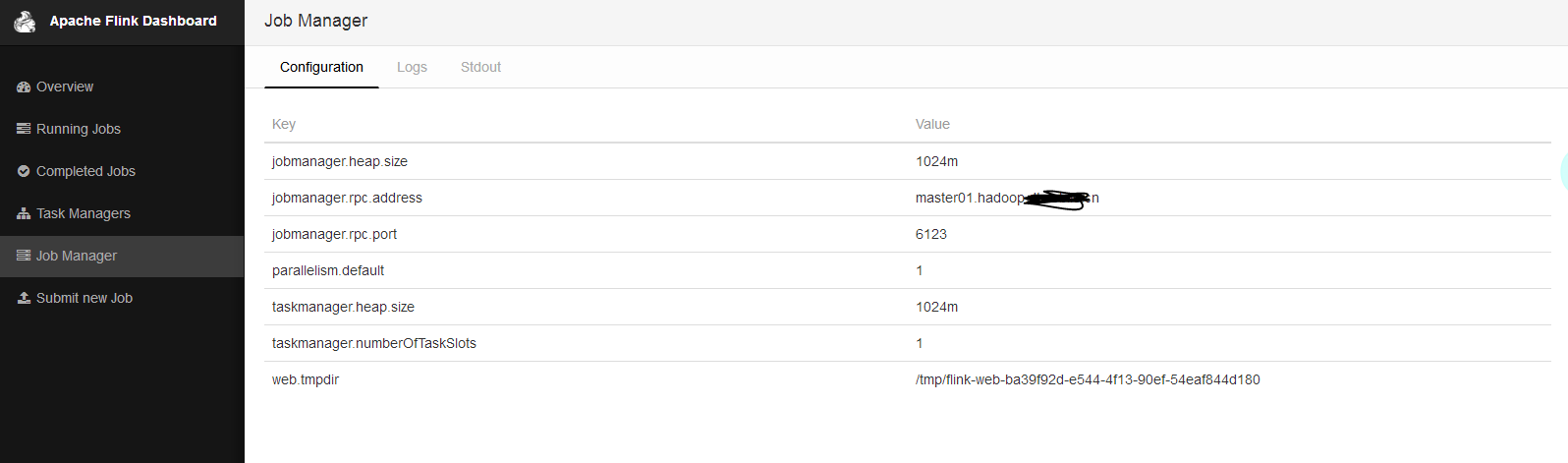
运行flink自带的wordcount例子
nc -l 9999
bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname 172.xx.xx.xxx --port 9999
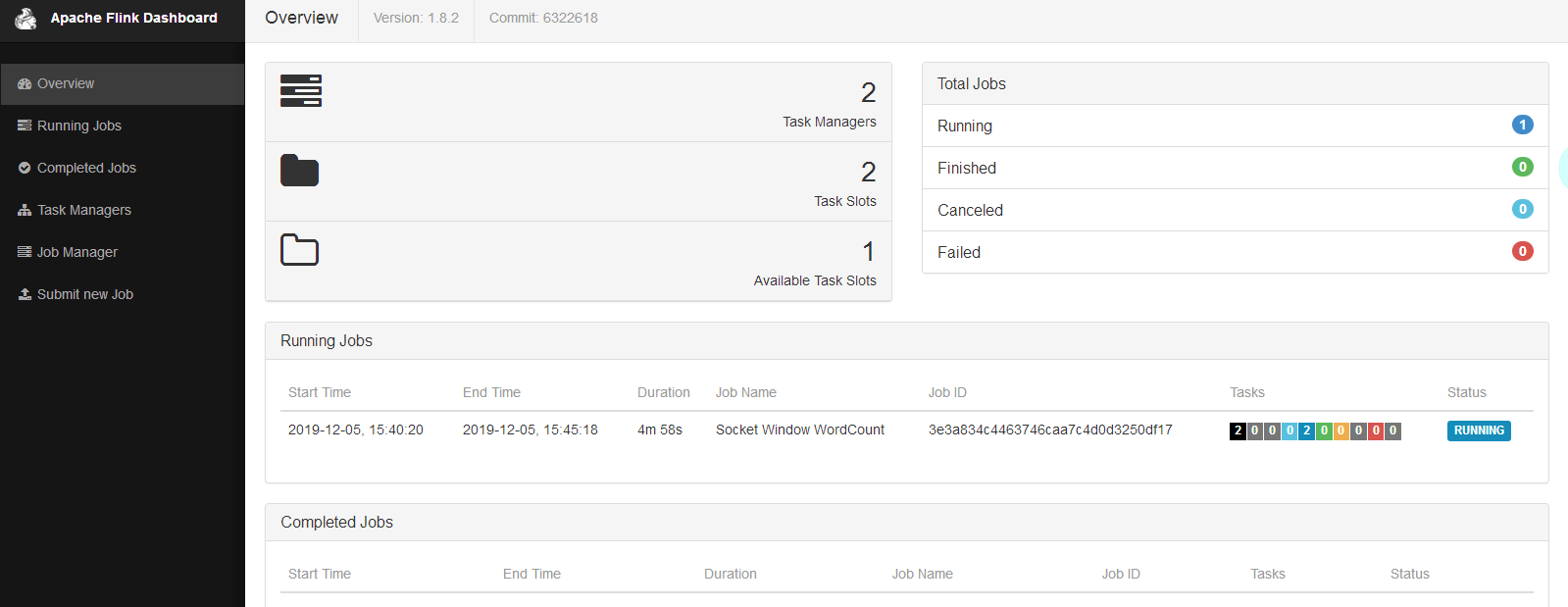
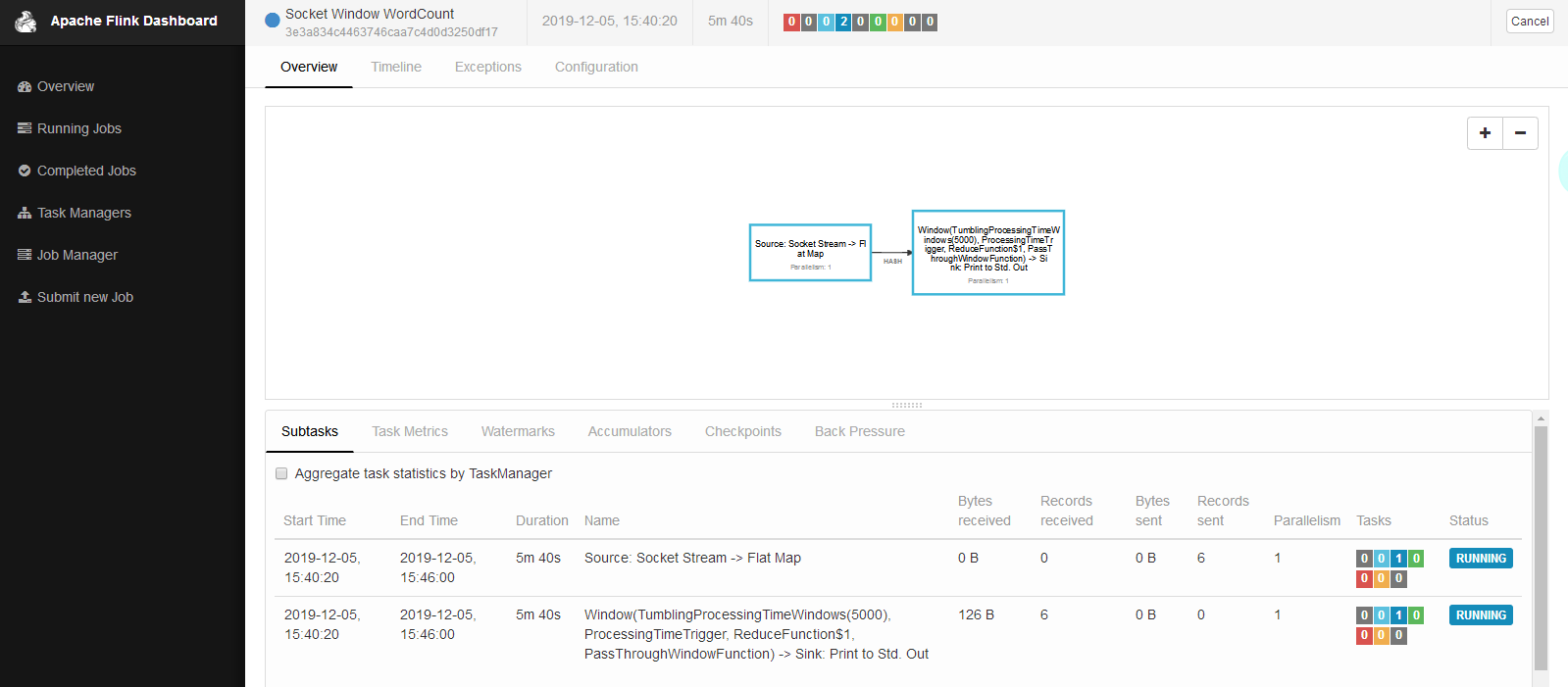
界面:
flink standalone集群中job的容错
1.jobmanager挂掉的话,正在执行的任务会失败,所以jobmanager应该做HA。
2.taskmanager挂掉的话,如果有多余的taskmanager节点,flink会自动把任务调度到其他节点上执行。