Object类的所有非final方法(equals、hashCode、toString、clone、finalize)都要遵守通用约定(general contract),否则其它依赖于这些约定的类(HashMap,HashSet等)将不能正常工作。
8、覆盖equals时请遵守通用约定
无需覆盖equals的情形:
-
类的每个实例本质上是唯一的。类代表的是活动实体而不是值的概念。(例如,类
Thread) -
不关心类“逻辑相等”的功能,从
Object继承的equals实现已经足够。(例如,类Random) -
超类的
equals实现也适用于子类。(例如,List从AbstractList继承equals实现) -
类是private或包级私有(默认)的,可以确定它的
equals方法永远不会被调用。 -
“每个值最多有一个实例”的类,逻辑相同与对象相同一样。(例如,枚举类,Singleton类)
需要覆盖equals的情形:
- 类具有“逻辑相等”的概念,而且超类没有覆盖
equals方法。
覆盖equals时必须遵守的约定:
-
自反性,
x非空时,x.equals(x)返回true -
对称性,
x, y非空时,若x.equals(y)返回true,则y.equals(x)返回true -
传递性,
x, y, z非空时,若x.equals(y)返回true且y.equals(z)返回true,则x.equals(z)返回true -
一致性,
x, y非空时,多次调用x.equals(y)返回值一致 -
x非空时,x.equals(null)一定返回false
违反约定的例子:
在java类库中,java.sql.Timestamp继承自java.util.Date,并增加了nanoseconds域。但Timestamp的equals实现违反了对称性(date.equals(timestamp) != timestamp.equals(date)),如果Timestamp和Date对象被混合在一起使用,将引起不正确的行为。
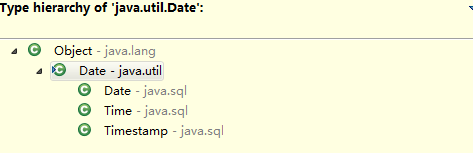
equals实现代码:
//Date中equals实现
public boolean equals(Object obj) {
return obj instanceof Date && getTime() == ((Date) obj).getTime();
}
//Timestamp中equals实现
/*
* Note: This method is not symmetric with respect to the
* equals(Object) method in the base class.
*/
public boolean equals(java.lang.Object ts) {
if (ts instanceof Timestamp) {
return this.equals((Timestamp)ts);
} else {
return false;
}
}
注:在equals实现中,对于obj instanceof Date语句,若obj为null,其将返回false。因此把null传个equals方法,无需进行单独的类型检查(判断obj是否为null)。
若将上面Timestamp的equals代码改为如下形式:
//Timestamp改进的equals实现
public boolean equals(java.lang.Object ts) {
if (ts instanceof Timestamp) {
return this.equals((Timestamp)ts);
} else if (ts instanceof Date){
return ((Date)ts).equals(this);
} else {
return false;
}
}
这样确实保证了对称性,但却牺牲了Timestamp类的特征。
Timestamp是Date 类的瘦包装器 (thin wrapper),它允许 JDBC API 将该类标识为 SQL TIMESTAMP 值。
它添加保存 SQL TIMESTAMP 毫微秒值和提供支持时间戳值的 JDBC 转义语法的格式化和解析操作的能力。
实现equals方法的诀窍:
-
使用 == 检查“参数是否为这个对象的引用”,特别是比较操作比较昂贵时。
-
使用instanceof操作符检查“参数是否为正确的类型”,若不是返回false
-
检查参数中的域是否与对象中的对应域相匹配
-
编写完equals方法后检查对称性、传递性、一致性
注意:
-
覆盖equals时总要覆盖hashCode
-
不要将equals中的Object替换为其他类型,使用
@Override public boolean equals(Object o),参数类型为Object,否则将重载equals方法
9、覆盖equals时总要覆盖hashCode
每个覆盖了equals方法的类中,必须覆盖hashCode方法,否则该类无法用于基于散列表的集合(HashMap,HashSet和HashTable)
对hashCode的约定:
-
对同一个对象调用多次(用于比较操作的信息未被修改),hashCode返回同一个整数
-
equals比较相等,则hashCode返回的值必须相同
-
equals比较不相等,hashCode返回的值可能相同,也可能不同
相等的对象必须具有相等的hashCode值;hashCode值不同,对象一定不相等,为不相等的对象产生不相等的散列码可以提高散列表的性能。散列函数应该把不相等的实例均匀分配到所有可能的散列值上。
一种计算散列码的方式:
1、保存一个非零的常数值,result = 17
2、为对象中每个域f(equals方法中涉及的域)计算int型的散列码c
-
域为boolean类型,
c = f ? 1 : 0 -
域为byte,char,short或int类型,
c = (int) f -
域为long类型,
c = (int)(f^(f >>> 32)) -
域为float类型,
c = Float.floatToIntBits(f) -
域为double类型,
f = Double.doubleToLongBits(f); c = (int)(f^(f >>> 32)) -
域为一个对象的引用,
c = f.hashCode() -
域为数组,利用此方法递归计算数组的hashCode值
3、将所有的散列码合并到result,递归调用result = result * 31 + c
例如:
@Override
public int hashCode() {
int result = 17;
result = 31 * result + fa;
result = 31 * result + fb;
result = 31 * result + fc;
return result;
}
使用31的原因:
31是一个奇素数并且31可以使用移位和减法来代替乘法以提高性能,如:31 * i == (i << 5) - i。现代的JVM能够自动完成这种优化
对于不可变类,若每次计算hashCode的开销比较大,可将散列码缓存在对象内部,而不是每次请求时都重新计算散列码。如:
private volatile int hashCode = 0; //volatile
@Override
public int hashCode() {
if (hashCode != 0) {
return hashCode;
}
int result = 17;
result = 31 * result + fa;
result = 31 * result + fb;
result = 31 * result + fc;
hashCode = result;
return result;
}
10、始终要覆盖toString
toString的约定,建议所有的类都实现toString方法。toString实现可以使类用起来更加舒服,有利于调试时信息的诊断。
如果对象太大或信息难以用字符串描述,应该返回一个摘要信息。在文档中标明toString的返回格式。
11、谨慎的覆盖clone
一个类实现了Cloneable接口,表名这个类允许被克隆。Cloneable接口是个空接口,仅仅用来标识这个类可以被复制,具体实现将由JVM调用Object中的原生方法clone()完成。所以一个类要能够复制必须实现Cloneable接口并重写clone()方法。
关于clone方法的实现参见博客java中clone方法的实现
java中仅有的创建对象的两种方式:①.使用new操作符创建对象;②.使用clone方法复制对象。由于clone方法将最终将调用JVM中的原生方法完成复制,所以一般使用clone方法复制对象要比新建一个对象然后逐一进行元素复制效率要高。
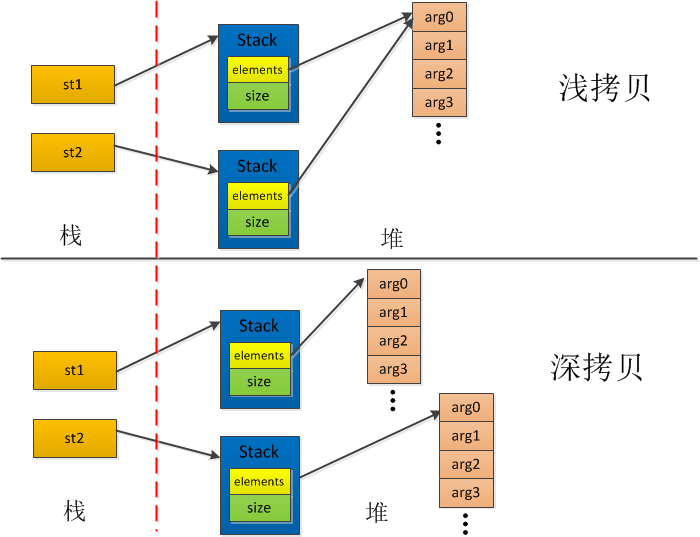
在java中基本数据类型是按值传递的,而对象是按引用传递的。所以调用对象的clone方法将涉及深拷贝和浅拷贝的概念。
浅拷贝是指拷贝对象时仅仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象。深拷贝不仅拷贝对象本身,而且拷贝对象包含的引用指向的所有对象。通过clone方法复制对象时,若不对clone()方法进行改写,则调用此方法得到的对象为浅拷贝。
例如:浅拷贝
public class Stack implements Cloneable {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object o) {
ensureCapacity();
elements[size++] = o;
}
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // 【避免内存泄漏】
return result;
}
private void ensureCapacity() {
if (elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
// 实现clone方法,浅拷贝
@Override
protected Stack clone() throws CloneNotSupportedException {
return (Stack) super.clone();
}
}
深拷贝:
//深拷贝
@Override
protected Stack clone() throws CloneNotSupportedException {
Stack result = (Stack) super.clone();
result.elements = elements.clone(); //对elements元素进行拷贝(引用或基本数据类型)
return result;
}
其原理图:
注意:
-
由于java5.0后引入了协变返回类型(covariant return type)实现(基于泛型),即覆盖方法的返回类型可以是被覆盖方法的返回类型的子类型,所以clone方法可以直接返回Stack类型,而不用返回Object类型,然后客户端再强转。
-
在数组上调用clone返回的数组,其编译时类型与被克隆数组的类型相同。
-
若elements域是final的,深拷贝不能正常工作。因为clone架构与引用可变对象的final域的正常用法是不兼容的。
-
若elements数组中的元素是引用类型,则此方法仅仅是对引用的拷贝,元素指向的还是原来的对象
还应该注意,数组的clone,仅仅复制的是数组中的元素,即若数组中元素为引用类型,仅仅复制引用。若clone的对象中含有链表,则应单独对链表进行循环复制。例如,一个内部包含一个散列桶数组的散列表,其数组中每个元素都指向一个独立的链表。此时仅仅使用上面的方法就是不完全拷贝。
代码:
public class HashTable implements Cloneable {
private static final int CAPACITY = 10;
//散列桶数组,数组中元素指向由Entry对象组成的链表(指向链表第一个Entry)
private Entry[] buckerts = new Entry[CAPACITY];
public void put(Object key, Object value) {
int index = key.hashCode() % CAPACITY;
Entry e = buckerts[index];
buckerts[index] = new Entry(key,value,e);
}
@Override
public HashTable clone() throws CloneNotSupportedException {
HashTable result = (HashTable)super.clone();
result.buckerts = buckerts.clone(); //仅仅复制了对链表的引用。
return result;
}
//轻量级单链表
private static class Entry {
final Object key;
Object value;
Entry next;
Entry(Object key, Object value, Entry next) {
this.key = key;
this.value = value;
this.next = next;
}
}
}
原理图:
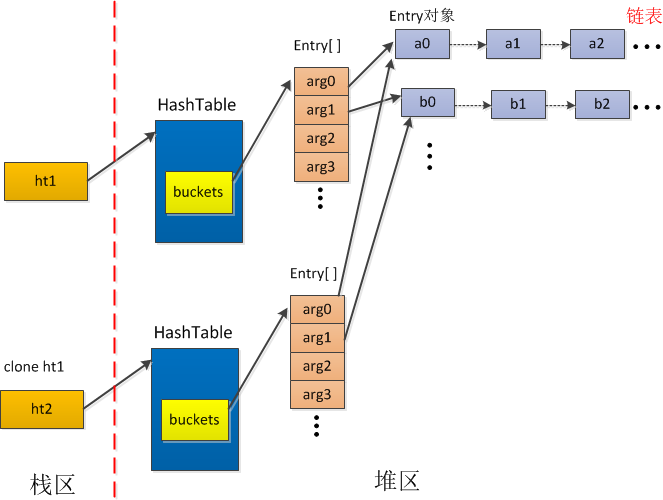
虽然被克隆对象有自己的散列桶数组,但数组引用的链表与原对象是一样的。数组的clone方法,仅仅拷贝了对链表的引用,而没有复制链表中的元素。
改进代码:
@Override
public HashTable clone() throws CloneNotSupportedException {
HashTable result = (HashTable)super.clone();
result.buckerts = buckerts.clone();
for(int i=0; i<buckerts.length; i++) {
result.buckerts[i] = buckerts[i].deepCopy();
}
return result;
}
//轻量级单链表
private static class Entry {
final Object key;
Object value;
Entry next;
Entry(Object key, Object value, Entry next) {
this.key = key;
this.value = value;
this.next = next;
}
//递归实现链表复制
Entry deepCopy() {
return new Entry(key,value,next == null ? null : next.deepCopy());
}
}
在内部类Entry中的深度拷贝方法递归的调用自身,以完成链表的拷贝。虽然这种方法比较简洁,但如果链表很长,有可能会导致栈溢出。可以使用迭代代替递归实现链表的复制。代码如下:
//迭代实现链表复制
Entry deepCopy() {
Entry result = new Entry(key, value, next);
for(Entry e = result; e.next != null; e = e.next) {
e.next = new Entry(e.next.key, e.next.value, e.next.next);
}
return result;
}
实现clone方法的步骤:
-
首先调用父类的super.clone方法(父类必须实现clone方法),这个方法将最终调用Object的中native型的clone方法完成浅拷贝
-
对类中的引用类型进行单独拷贝
-
检查clone中是否有不完全拷贝(例如,链表),进行额外的复制
12、考虑实现Comparable接口
实现了Comparable接口的类,表明它的实例具有内在的排序关系,可以使用Arrays.sort(comp)方法对其数组进行排序。一旦类实现了Comparable接口,它就可以与许多泛型算法及依赖于该接口的集合实现进行协作。若编写的类是有非常明显的内在排序关系,那么就应该实现Comparable接口。实现Comparable接口必须重写compareTo方法。
依赖于比较关系(compareTo方法)的类包括有序集合类TreeSet和TreeMap,以及工具类Collection和Arrays,它们内部包含有搜索和排序算法。
compareTo方法的约定:
-
该对象小于、等于、大于指定对象时,分别返回负整数、零、正整数。若两对象不同,则抛出
ClassCastException异常 -
x.compareTo(y) == 0与x.equals(y)建议保持一致。
参考
-
Effective java教材