linux内核分析学习笔记 ——第二章 操作系统是如何工作的
计算机的“三大法宝”
- 程序存储计算机 即冯诺依曼体系结构,基本上是所有计算机的基础性的逻辑框架
- 函数调用堆栈 高级语言可以运行的起点就是函数调用堆栈
- 中断机制
函数调用堆栈
-
堆栈的具体作用
- 记录函数调用的框架
- 传递函数参数
- 保存返回值地址
- 提供函数内部局部变量的存储空间
-
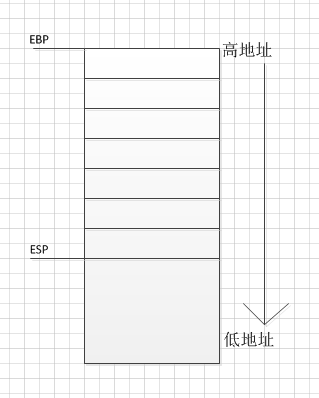
堆栈相关的寄存器
- ESP:堆栈指针,指向堆栈栈顶
- EBP:基址指针,指向堆栈栈底,在C语言中记录当前函数调用基址
-
堆栈操作
- push 栈顶地址减少4个字节,将操作数放入栈顶存储单元
- pop 将操作数从栈顶存储单元移出,栈顶地址增加4个字节
- 函数调用堆栈就是由多个逻辑上的栈堆叠起来的框架
-
其他关键寄存器
-
CS:EIP 总是指向下一条指令地址 CS是代码段寄存器 EIP是指向下一条指令的地址
- 顺序执行:总是指向地址连续的下一条指令
- 转跳/分支:CS:EIP会根据程序需要被修改
- call:将CS:EIP压入栈顶,随后指向被调用函数的入口地址
- ret:从栈顶弹出原来保存在这里的CS:EIP的值,放入CS:EIP中
-
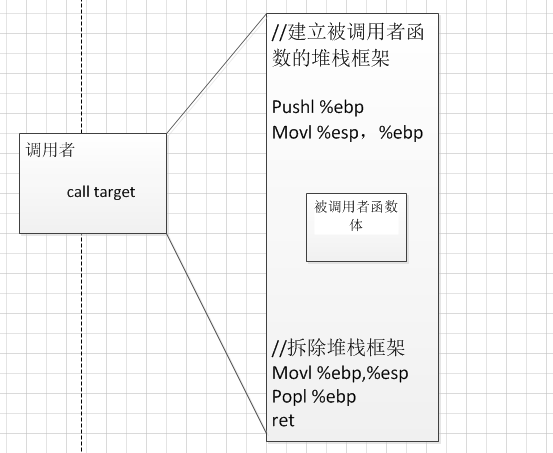
函数调用堆栈框架
-
-
堆栈是C语言程序运行时必须记录函数调用路径和参数存储的空间,pushl和popl指令用来进行出栈压栈,enter和leave指令对函数调用堆栈框架的建立和拆除进行封装,堆栈中最关键的就是函数调用堆栈框架
-
-
-
堆栈用来传递函数的参数
- 对32位的x86来说堆栈传递参数的方法是从左到右依次压栈
-
堆栈传递返回值
- 程序用EAX保存返回值。
- 如果有多个返回值,EAX返回一个内存地址,这个内存地址里面可以指向很多返回数据。
-
堆栈还提供局部变量的空间
- 编译器一般在函数开始执行时预留出足够的栈空间来保存函数体的所有局部变量
C语言中内嵌汇编语言的写法
内嵌汇编的语法如下:
_asm_ _volatile_ (
汇编语句模版;
输出部分;
输入部分;
破坏描述部分;
);
其中,_asm_ 是GCC的关键字asm的宏定义,是内嵌汇编的关键字。
_volatile_ 是GCC的关键字,告诉编译器不要优化代码,汇编指令保留原样。
同时,%作为转义字符,寄存器前面会多一个转义符号
%加一个数字代表输入、输入和破坏描述的编号。
汇编语言语法规则
#include <stdio.h>
int main()
{
unsigned int val1 = 1;
unsigned int val2 = 2;
unsigned int val3 = 0;
pritnf("val1:%d,val2:%d,val3:%d
",val1,val2,val3);
asm volatile(
"movl $0,%%eax
"
"addl %1,%%eax
"
"addl %2,%%eax
"
"movl %%eax,%0
"
:"=m"(val3)
:"c"(vall),"d"(val2)
);
pritnf("val1:%d,val2:%d,val3:%d
",val1,val2,val3);
return 0;
}
-
"movl $0,%%eax "将eax寄存器清零 -
"addl %1,%%eax "- %1 是指输入输出部分,从0开始编号,所以%1指的是val1,前面的c指的是寄存器ecx用来存储val1的值
- 这条语句的就是就是将ecx中存储的val1的值与eax寄存器中的值相加,结果为1
-
"addl %2,%%eax "- %2 是指val2存在edx寄存器中
- 这条语句就是将val2与寄存器eax中的值相加,结果为3
-
"movl %%eax,%0 "- “=m”代表内存变量,而不是使用寄存器
- 这条指令就是将val1+val2的值写入到内存变量val3中去
-
内嵌汇编当作一个函数来看的话,第二部分和第三部分输入相当于函数的参数和返回值,第一部分则相当于函数内部具体的代码。
虚拟一个x86的CPU硬件平台
- 中断
- 在没有中断机制之前,计算机只能一个一个程序执行,也就是批处理。
- 中断机制的CPU会把当前正在执行的程序的CS:EIP寄存器和ESP寄存器压入内核堆栈,将CS:EIP指向中断程序的入口,保存现场的工作,等重新回来再恢复现场,恢复CS:EIP寄存器和ESP寄存器。
在mykernel基础上构造一个简单的操作系统内核
- 步骤
- 在实验楼系统中搭建平台
- 在mykernel中查看mymain.c 和 myinterupt.c 代码
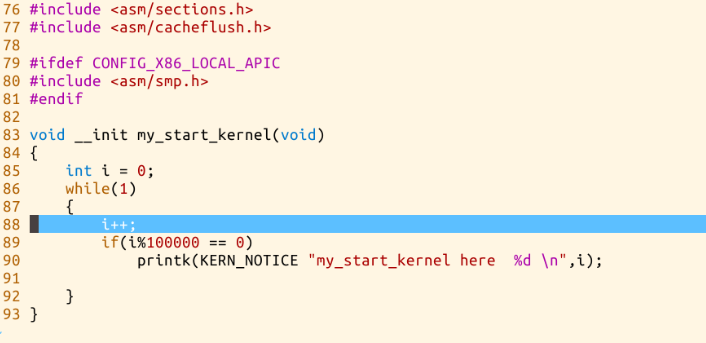

- 运行结果展示

- 将mykernel操作系统的代码进行扩展
- 添加 mypcb.h 的头文件,用来定义进程控制块
- 修改 mymain.c 作为内核代码的入口,负责初始化内核的各个组成部分
- 修改 myinterrupt.c 增加进程切换代码
代码如下:
mypcb.h:
#define MAX_TASK_NUM 4
#define KERNEL_STACK_SIZE 1024*8
struct Thread {
unsigned long ip;
unsigned long sp;
};
typedef struct PCB{
int pid; //进程的编号
volatile long state; //进程的状态
char stack[KERNEL_STACK_SIZE]; //进程的栈
struct Thread thread; //Thread 结构体
unsigned long task_entry; //进程的起始入口地址
struct PCB *next; //单链表链接每个进程
}tPCB;
void my_schedule(void); //调度器
- 头文件一开始的定义,表示的是进程的数目、进程堆栈的大小。
- 头文件中结构体PCB表示一个进程结构体,其中包括进程编号、进程运行状态、进程堆栈的大小、进程的两个指针、进程入口以及指向一下个进程的指针next。
mymain.c
#include <linux/types.h>#include <linux/types.h>
#include <linux/string.h>
#include <linux/ctype.h>
#include <linux/tty.h>
#include <linux/vmalloc.h>
#include "mypcb.h"
tPCB task[MAX_TASK_NUM];//定义4个进程
tPCB * my_current_task = NULL;
volatile int my_need_sched = 0;
void my_process(void); //每10000000 来进行进程调度,调用my_schedule
void __init my_start_kernel(void)
{
int pid = 0;
int i;
task[pid].pid = pid; //0号进程pid设为0
task[pid].state = 0; //0号进程state设为可运行
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;//0号进程的ip和入口地址设为my_process();
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid]; //next指针指向自己
for(i=1;i<MAX_TASK_NUM;i++) //1,2,3号进程复制0号进程
{
memcpy(&task[i],&task[0],sizeof(tPCB));
task[i].pid = i;
task[i].state = -1;
task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1];
task[i].next = task[i-1].next;
task[i-1].next = &task[i]; //所有进程成为一个循环链表
}
pid = 0;
my_current_task = &task[pid]; //当前运行的进程设为0号进程
asm volatile(
"movl %1,%%esp
" //esp指向stack数组的末尾
"pushl %1
" //将task[0].thread.sp压栈
"pushl %0
" //将task[0].thread.ip压栈
"ret
" //eip指向0进程起始地址,启动0号进程
"popl %%ebp
"//释放栈空间
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp)
);
}
void my_process(void)
{
int i = 0;
while(1)
{
i++;
if(i%10000000 == 0)
{
printk(KERN_NOTICE "this is process %d -
",my_current_task->pid);
if(my_need_sched == 1)
{
my_need_sched = 0;
my_shcedule();
}
printk(KERN_NOTICE"this is process %d +
",my_current_task->pid);
}
}
}
- mymain.c
void _init my_start_kernel(void)函数用于初始化0号进程task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];这一句可以看出来,进程的sp指针,代表的是堆栈的栈底,因为堆栈从高地址向低地址转变,所以数组的最高位代表的就是堆栈的栈底。for(i=1;i<MAX_TASK_NUM;i++)for循环用于生成其他的三个进程,并将它们连成单链表- 下面对内嵌汇编代码详细分析
movl %1,%%esp表示将task[pid].thread.sp指针的指向存放在esp中,即esp指向0进程的堆栈栈底pushl %1表示将当前堆栈栈底地址入栈pushl %0表示当前进程的EIP入栈ret将进程的入口放入EIP寄存器中

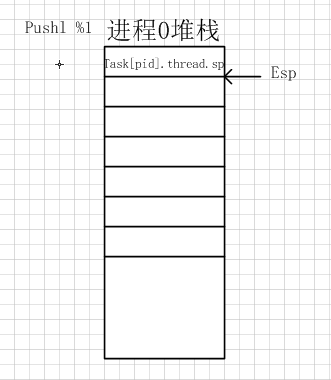

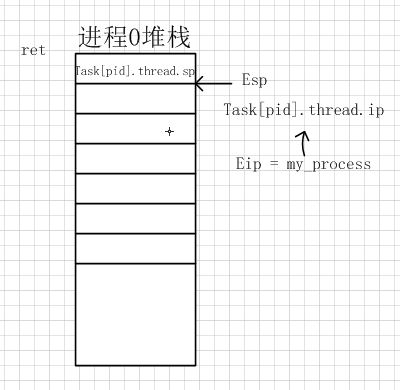
接下来进程0启动,开始执行my_process(void)函数代码。
myinterrupt.c
#include <linux/string.h>
#include <linux/ctype.h>
#include <linux/tty.h>
#include <linux/vmalloc.h>
#include "mypcb.h"
extern tPCB task[MAX_TASK_NUM];
extern *tPCB my_current_task;
extern volatile int my_need_sched;
volatile int time_count = 0;
void my_timer_handler(void)
{
#if 1
if(time_count%1000 == 0 && my_need_sched != 1)
{
printk(KERN_NOTICE ">>>my_timer_handler here<<<
");
my_need_sched = 1;
}
time_count ++ ;
#endif
return;
}
void my_schedule(void)
{
tPCB * next;
tPCB * prev;
if(next->state == 0) //下一个进程可运行,执行进程切换
{
/* switch to next process */
asm volatile(
"pushl %%ebp
" //保存当前进程的ebp
"movl %%esp,%0
" //将当前进程的esp储存到当前进程的thread.sp
"movl %2,%%esp
" //esp指向下一个进程
"movl $1f,%1
" //将1f存储到thread.sp.$1f是“1: ”处,再次调度到该进程时就会从1:开始执行
"pushl %3
" //将下一个进程的thread.ip压栈
"ret
" //eip指向下一个进程的起始地址
"1: "
"popl %%ebp
"//待下一个进程执行完后释放栈空间,恢复现场
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<
",prev->pid,next->pid);
else
{
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<
",prev->pid,next->pid);
/* switch to new process */
asm volatile(
"pushl %%ebp
" /* save ebp */
"movl %%esp,%0
" /* save esp */
"movl %2,%%esp
" /* restore esp */
"movl %2,%%ebp
" /* restore ebp */
"movl $1f,%1
" /* save eip */
"pushl %3
"
"ret
" /* restore eip */
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}
return;
}
- 中断函数计数达到1000产生一个中断,将
my_need_sched置1,此时my_process()将会执行my_shcedule()实现进程调度。 - 在
my_shcedule()有两种情况,一种是next->state == 0表示下一个要切换的进程正在运行。- 下面是对应堆栈变化的图解
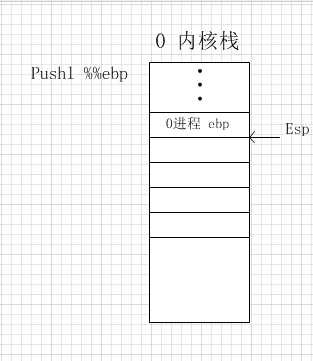

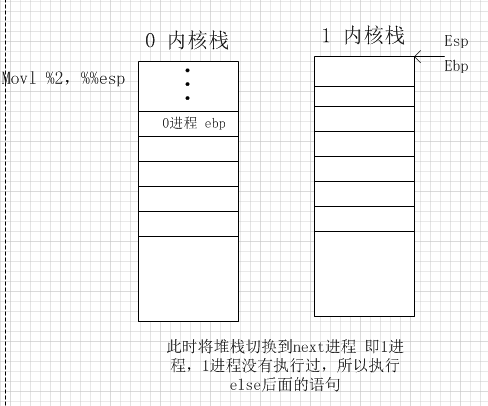


问题
在画进程切换堆栈时,我很疑惑的是这些堆栈是谁的堆栈,是进程自己的堆栈还是内核堆栈呢?查阅相关资料,以下是一些概念。
-
进程的堆栈
- 内核在创建进程时,会为进程创建堆栈,每个进程都有两个堆栈,一个是用户栈,一个是内核栈,分别存在于用户空间和内核空间。
- 当进程因为中断或者系统调用而陷入内核态之时,进程所使用的堆栈也要从用户栈转到内核栈。
- 当一个任务(进程)执行系统调用而陷入内核代码中执行时,称进程处于内核运行态(内核态)。
- 当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。
- 参考http://www.cnblogs.com/Anker/p/3269106.html
https://blog.csdn.net/lqygame/article/details/72898069
-
处理器的运行状态
- 内核态 运行在进程上下文
- 内核态 运行于终端上下文
- 用户态 运行于用户空间
-
我的理解
- 我在上面画出的堆栈都是在内核栈中的各个进程的内核堆栈,进程的用户栈一般是存储进程要处理的相关操作的内容。两个堆栈的切换也是内核堆栈的切换。
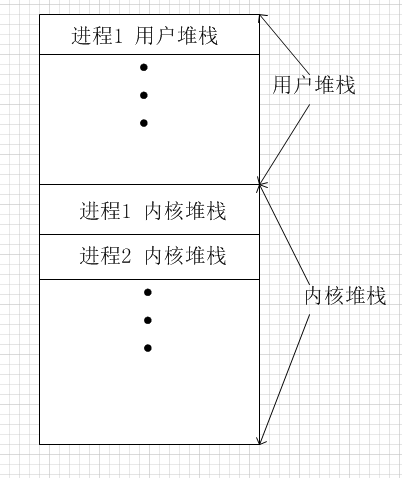
不知道我的理解是不是正确,因为提到进程调度会涉及到用户栈到内核栈的切换,刚开始画图一直在思考,这里的代码到底是对用户栈的操作还是对内核栈的操作,后来发现这个代码主要是以进程的调度为重点,所以调度代码都是在内核栈的操作。
- 我在上面画出的堆栈都是在内核栈中的各个进程的内核堆栈,进程的用户栈一般是存储进程要处理的相关操作的内容。两个堆栈的切换也是内核堆栈的切换。