一、Ceph简介
Red Hat Ceph是一个分布式的数据对象存储,系统设计旨在性能、可靠性和可扩展性上能够提供优秀的存储服务。Ceph分布式存储能够在一个统一的系统中同时提供了对象、块、和文件存储功能,在这方面独一无二的;同时在扩展性上又可支持数以千计的客户端可以访问PB级到EB级甚至更多的数据。它不但适应非结构化数据,并且客户端可以同时使用当前及传统的对象接口进行数据存取,被称为是存储的未来!
二、Ceph的特点
2.1 Ceph的优势
1. CRUSH算法
Ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。CRUSH在一致性哈希基础上很好的考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。Ceph会将CRUSH规则集分配给存储池。当Ceph客户端存储或检索存储池中的数据时,Ceph会自动识别CRUSH规则集、以及存储和检索数据这一规则中的顶级bucket。当Ceph处理CRUSH规则时,它会识别出包含某个PG的主OSD,这样就可以使客户端直接与主OSD进行连接进行数据的读写。
2. 高可用
Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以分隔故障域, 可以忍受多种故障场景并自动尝试并行修复。同时支持强一致副本,而副本又能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自管理、自动修复。无单点故障,有很强的容错性。
3. 高扩展性
Ceph不同于swift,客户端所有的读写操作都要经过代理节点。一旦集群并发量增大时,代理节点很容易成为单点瓶颈。Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,它的性能会随着磁盘数量的增加而线性增长。
4. 特性丰富
Ceph支持三种调用接口:对象存储,块存储,文件系统挂载。三种方式可以一同使用。Ceph统一存储,虽然Ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口
2.2 Ceph的缺点
虽然Ceph有很多优点,也被OpenStack所推崇,但Ceph并非是尽善尽美,Ceph在性能、易用和节能方面还有很大的提升空间。Ceph来自于社区,Ceph社区的繁荣是毋庸置疑的,但从另外一方面讲,社区是比较松散的结构,因此社区版的Ceph在产品的功能性,企业级特性方面都会有所欠缺。
三、架构与组件
3.1 Ceph架构
文档连接:http://docs.ceph.com/docs/master/architecture/
架构示意图
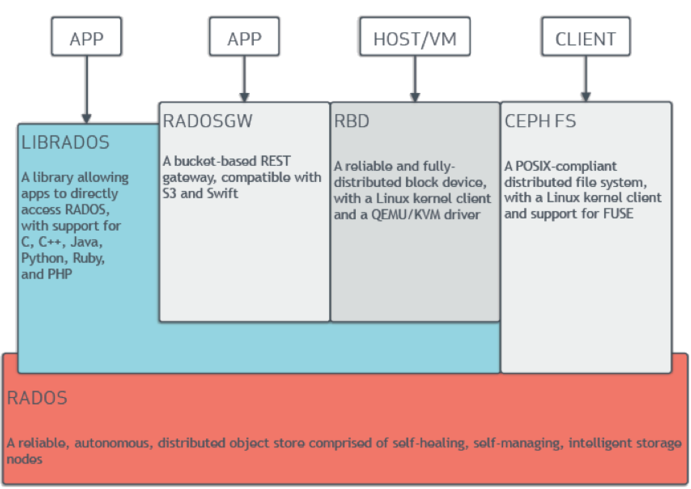
- Ceph的底层是RADOS,RADOS本身也是分布式存储系统,CEPH所有的存储功能都是基于RADOS实现。RADOS采用C++开发,所提供的原生Librados API包括C和C++两种。Ceph的上层应用调用本机上的librados API,再由后者通过socket与RADOS集群中的其他节点通信并完成各种操作。
- RADOS向外界暴露了调用接口,即LibRADOS,应用程序只需要调用LibRADOS的接口,就可以操纵Ceph了。这其中,RADOS GW用于对象存储,RBD用于块存储,它们都属于LibRADOS;CephFS是内核态程序,向外界提供了POSIX接口,用户可以通过客户端直接挂载使用。
- RADOS GateWay、RBD其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。这两种方式目前在云计算中应用的比较多。
- CEPHFS则提供了POSIX接口,用户可直接通过客户端挂载使用。它是内核态的程序,所以无需调用用户空间的librados库。它通过内核中的net模块来与Rados进行交互。
- RBD块设备。对外提供块存储。可以像磁盘一样被映射、格式化已经挂载到服务器上。支持snapshot。
3.2 ceph基本进程及作用
Ceph主要有三个基本进程,如下图:
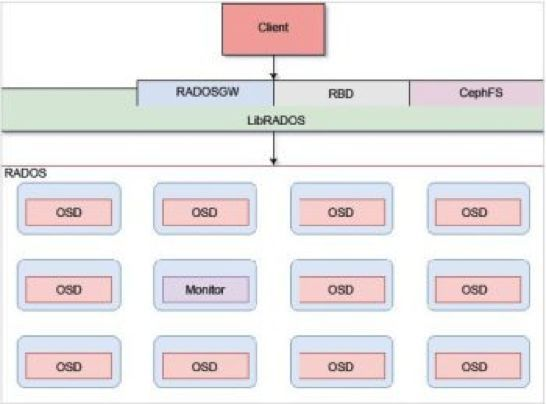
OSD
- Ceph OSD 以对象的形式存储所有客户端数据,并在客户端发起数据请求时提供相同的数据。Ceph 集群包含多个OSD ,对于任何读或写操作,客户端首先向monitor 请求集群的map ,然后,它们就可以无须monitor 的干预直接与OSD 进行I/O操作也正是因为产生数据的客户端能够直接写入存储数据的OSD 而没有任何额外的数据处理层,才使得数据事务处理速度如此之快。与其他存储解决方案相比,这种类型的数据存储和取回机制是Ceph 所独有的。
MON(monitor)
负责监视整个集群的运行状况,信息由维护集群成员的守护程序来提供,各节点之间的状态、集群配置信息。Cephmonitormap主要包括OSDmap、PGmap、MDSmap和CRUSH等,这些map被统称为集群Map。cephmonitor不存储任何数据。下面分别开始介绍这些map的功能:
- Monitormap:包括有关monitor节点端到端的信息,其中包括Ceph集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过"cephmondump"查看monitormap。
- OSDmap:包括一些常用的信息,如集群ID、创建OSDmap的版本信息和最后修改信息,以及pool相关信息,主要包括pool名字、pool的ID、类型,副本数目以及PGP等,还包括数量、状态、权重、最新的清洁间隔和OSD主机信息。通过命令"cephosddump"查看。
- PGmap:包括当前PG版本、时间戳、最新的OSDMap的版本信息、空间使用比例,以及接近占满比例信息,同事,也包括每个PGID、对象数目、状态、OSD的状态以及深度清理的详细信息。通过命令"cephpgdump"可以查看相关状态。
- CRUSHmap:CRUSHmap包括集群存储设备信息,故障域层次结构和存储数据时定义失败域规则信息。通过命令"cephosdcrushmap"查看。
- MDSmap:MDSMap包括存储当前MDSmap的版本信息、创建当前的Map的信息、修改时间、数据和元数据POOLID、集群MDS数目和MDS状态,可通过"cephmdsdump"查看
MDS
- Ceph元数据服务器,跟踪文件层次结构并存储只供CephFS使用的元数据。Ceph块设备和RADOS网关不需要元数据。MDS不直接给client提供数据服务。只有在使用cephfs的时候才需要它,而目在云计算中用的更广泛的是另外两种存储方式。
3.3 Ceph数据的存储过程
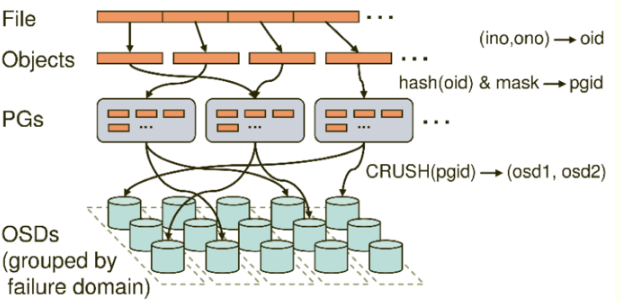
- 无论使用哪种存储方式(对象、块、挂载),存储的数据都会被切分成对象(Objects)。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成,虽然这些名词看上去很复杂,其实相当简单。ino即是文件的File ID,用于在全局唯一标示每一个文件,而ono则是分片的编号。比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。Oid的好处是可以唯一标示每个不同的对象,并且存储了对象与文件的从属关系。由于ceph的所有数据都虚拟成了整齐划一的对象,所以在读写时效率都会比较高。 但是对象并不会直接存储进OSD中,因为对象的size很小,在一个大规模的集群中可能有几百到几千万个对象。这么多对象光是遍历寻址,速度都是很缓慢的;并且如果将对象直接通过某种固定映射的哈希算法映射到osd上,当这个osd损坏时,对象无法自动迁移至其他osd上面(因为映射函数不允许)。为了解决这些问题,ceph引入了归置组的概念,即PG。
- PG是一个逻辑概念,我们linux系统中可以直接看到对象,但是无法直接看到PG。它在数据寻址时类似于数据库中的索引:每个对象都会固定映射进一个PG中,所以当我们要寻找一个对象时,只需要先找到对象所属的PG,然后遍历这个PG就可以了,无需遍历所有对象。而且在数据迁移时,也是以PG作为基本单位进行迁移,ceph不会直接操作对象。 对象时如何映射进PG的?还记得OID么?首先使用静态hash函数对OID做hash取出特征码,用特征码与PG的数量去模,得到的序号则是PGID。由于这种设计方式,PG的数量多寡直接决定了数据分布的均匀性,所以合理设置的PG数量可以很好的提升CEPH集群的性能并使数据均匀分布。
- 最后PG会根据管理员设置的副本数量进行复制,然后通过crush算法存储到不同的OSD节点上(其实是把PG中的所有对象存储到节点上),第一个osd节点即为主节点,其余均为从节点。
四、存储类型及应用
4.1 块存储
典型设备: 磁盘阵列,硬盘,主要是将裸磁盘空间映射给主机使用的。
优点:通过Raid与LVM等手段,对数据提供了保护。多块廉价的硬盘组合起来,提高容量。多块磁盘组合出来的逻辑盘,提升读写效率。
缺点:采用SAN架构组网时,光纤交换机,造价成本高。主机之间无法共享数据。
使用场景:docker容器、虚拟机磁盘存储分配。日志存储。文件存储。
4.2 文件存储
典型设备: FTP、NFS服务器,为了克服块存储文件无法共享的问题,所以有了文件存储;在服务器上架设FTP与NFS服务,就是文件存储。
优点:造价低,随便一台机器就可以了,方便文件共享。
缺点:读写速率低,传输速率慢。
使用场景:日志存储,有目录结构的文件存储。
4.3 对象存储
典型设备: 内置大容量硬盘的分布式服务器(swift, s3),多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能。
优点:具备块存储的读写高速,具备文件存储的共享等特性。
使用场景: (适合更新变动较少的数据)图片存储,视频存储。
五、Ceph存储的使用及访问
5.1 Ceph原生API(librados)
- Ceph原生接口,可以通过该接口让应用直接与RADOS协作来访问Ceph集群存储的对象
- Ceph RBD、Ceph RGW以及CephFS都构建于其上
- 如果需要最高性能,建议在应用中直接使用librados。如果想简化对Ceph存储的访问,可改用Ceph提供的更高级访问方式,如RGW、RBD、CephFS
5.2 Ceph Object Gateway
- 利用librados构建的对象存储接口
- 通过REST API为应用提供网关
- 支持S3和swift接口
5.3Ceph Block Device
- 提供块存储
- 由分散在集群中的不同的OSD中的个体对象组成
- Linux内核挂载支持
- QEMU、KVM和Openstack Cinder的启动支持
5.4 Ceph File System
- 并行文件系统,元数据由MDS管理
六、结语
目前在Ceph的开源社区还是比较热门的,但是更多的是应用于云计算的后端存储。对于Ceph,本人认为这是一个很大的体系,本篇文章也是查阅了大量的网络资料,以及参考很多大牛的文章,抽取其中一部分填充到本篇文章,但也只能提到一点点,同时也因为自身水平和见识限制,无法展现Ceph全貌,后面自己也会继续学习总结,争取能够对Ceph有一个基本的认识和了解,最好能够入门一窥Ceph风采,同时也会更新到博客中。最后特别感谢木二的博客以及其他博友博客,给了我很大的参考,同时也是让我对Ceph架构有了深一步的理解,对于参考的博客,我会尽量列出,如有博友发现出处未列明,请发邮件ningrui0407@gmail.com联系,我会加上原文链接,谢谢!!!
官方文档:http://docs.ceph.org.cn
参考:
https://www.cnblogs.com/itzgr/p/10265103.html
https://www.jianshu.com/p/25163032f57f
https://www.cnblogs.com/kevingrace/p/8387999.html
https://blog.csdn.net/sunhf_csdn/article/details/79797186
http://www.51niux.com/?id=161