1.概述
1.1介绍
Node.js是一个内置有chrome V8引擎的JavaScript运行环境,他可以使原本在浏览器中运行的JavaScript有能力跑后端,从而操作我们数据库,进行文件读写等。
1.2下载和安装
下载地址:https://nodejs.org/zh-cn/download/。以往的版本:https://nodejs.org/zh-cn/download/releases/
选择合适的版本,然后直接安装即可。
安装好后,打开cmd,输入node,出现下面显示的信息,说明安装成功,执行两次ctrl+C退出node命令。

1.3运行js文件
新建index.js文件,内容如下:
console.log('hello world')
在cmd切换到index.js所在的目录,执行node index.js即可看到输出的信息。因此只需要通过node命令即可运行对应的js文件。
2.npm常用的命令
npm -v:查看npm版本。 npm init:初始化后会出现一个package.json配置文件。可以在后面加上-y,快速跳过问答式界面。 npm install:会根据项目中的package.json文件自动下载项目所需的全部依赖。 npm install包名 -D:安装的包只用于开发环境,不用于生产环境,会出现在package.json文件中的devDependencies属性中。 npm install 包名 -S:安装的包需要发布到生产环境的,会出现在package.ison文件中的dependencies属性中。 npm list:查看当前目录下已安装的node包。 npm list -g:查看全局已经安装过的node包。 npm --help:查看npm帮助命令。 npm update 包名:更新指定包。 npm uninstall 包名:卸载指定包。 npm config list:查看配置信息。 npm 指定命令 --help:查看指定命令的帮助。 npm info 指定包名:查看远程npm上指定包的所有版本信息。 npm config set registry https://registry.npm.taobao.org :修改包下载源,此例修改为了淘宝镜像。 npm root:查看当前包的安装路径。 npm root -g:查看全局的包的安装路径。 npm ls包名:查看本地安装的指定包及版本信息,没有显示empty。 npm ls包名 -g:查看全局安装的指定包及版本信息,没有显示empty。
2.1安装cnpm
由于npm比较慢,有时可以使用cnpm去安装依赖。下面是安装cnpm,并指定是淘宝镜像:
npm install -g cnpm -registry=https://registry.npm.taobao.org
3.文件系统fs
3.1文件的导入与导出
在js中不可能只使用一个js文件,可能会需要其他js文件的值,就可以进行导入和导出。
新建test1.js,内容如下
var a=10; var b=2;
新建test2.js,内容如下
var c=30; console.log(a+c)
此时在test2中使用了test1的变量值,按照上例是无法获取到的,需要导入与导出。
test1.js修改:
var a=10; var b=2; //把a导出 exports.a=a
test2.js修改
var c=30; //导出需要的对象,可省略后缀名,./代表当前目录下 var a = require('./test1') console.log(a) //{ a: 10 } console.log(a.a+c) //40
在没有任何内容导出去的情况下获取某个文件的内容,会得到一个空对象。
module.exports是模块导出,和exports的功能一样,原因是系统会把module.exports的值赋给exports,即exports=module.exports,但是他们还是有区别的,module.exports可以导出对象,而exports只能导出单个属性。
实例:调用其他js中的方法
test.js内容如下:
function test1(){ console.log(123) } function test2(){ console.log(456) } //导出两个方法 module.exports = {
test1:test1,
test2:test2
}
index.js内容如下:
//导入js var tests=require('./test') //调用方法 tests.test1() tests.test2()
3.2使用第三方文件
以jquery为例,首先要下载jquery的包,然后才能引入并使用。
1)在对应的目录执行下载命令
npm install jquery
2)在js中引入并使用
var $ = require('jquery') console.log($)
3.3require加载包规则
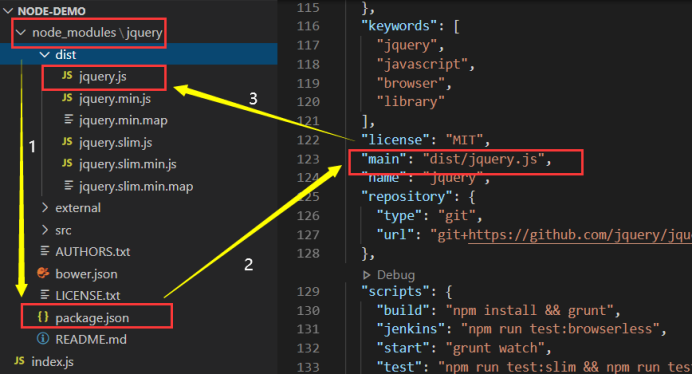
实际上在下载后,会在当前目录生成一个node_module的文件夹,里面就存放的是jquery相关的包。而在引入的时候,就会去node_module查找package.json文件,在这个文件里面找到main,main对应的值就是jquery.js的位置,流程如图
其他规则:
如果在要加载的第三方包中没有找到package.json文件或者是package.json文件中没有main属性,则默认加载第三方包中的index.js文件。
如果在加载第三方模块的文件的同级目录没有找到node_modules文件夹,或者以上所有情况都没有找到,则会向上一级父级目录下查找node_modules文件夹,查找规则如上一致。
如果一直找到该模块的磁盘根路径都没有找到,则会报错:can not find module xxx。
3.4文件的读取
1)导入文件模块
//导入fs模块 var fs = require('fs')
2)同步读取文件,同步读取会降低效率,后面只介绍异步的
//同步读取文件 var cont = fs.readFileSync('hello.txt', { flag: 'r',//只读 encoding: 'utf-8',//指定读取的编码 }) console.log(cont)
3)异步方式读取
//异步的读取 fs.readFile('hello.txt', { flag: 'r',//只读 encoding: 'utf-8',//指定读取的编码 }, (err, data) => { if (err) { //发生错误 console.log(err) } else { console.log(data) } })
4)对异步的方式进行封装
//对异步的方式进行封装 function fsRead(path) { return new Promise((resolve, reject) => { fs.readFile(path, { flag: 'r',//只读 encoding: 'utf-8',//指定读取的编码 }, (err, data) => { if (err) { reject(err) } else { resolve(data) } }) }) }
5)使用封装的方法
//调用封装的读取文件的方法 fsRead('hello.txt').then(res=>{ console.log("内容是:"+res) },err=>{ console.log(err) })
6)文件的写入
var context='你好啊,七夕节快乐,年轻人' //异步写入,指定的文件不存在时会自动创建 fs.writeFile('hello.txt',context,{ flag: 'w',//写,w会覆盖原内容,a在后面追加 encoding: 'utf-8',//指定读取的编码 },err =>{ if(err){ console.log('发生错误') }else{ console.log('写入成功') } })
7)对写入进行封装
//对异步的方式进行封装 function fsWrite(path,context) { return new Promise((resolve, reject) => { fs.writeFile(path,context, { flag: 'a',//写,w会覆盖原内容,a在后面追加 encoding: 'utf-8',//指定读取的编码 }, err => { if (err) { reject(err) } else { resolve() } }) }) } //调用
8)调用封装的方法
//调用封装的读取文件的方法 fsWrite('hello1.txt',context).then(res=>{ console.log("成功") },err=>{ console.log(err) })
3.5目录的读取
3.5.1读取目录
//读取目录下的文件 fs.readdir('hello',(err,files)=>{ if(err){ console.log(err) }else{ files.forEach(file=>{ console.log(file) }) } })
3.5.2删除目录
//删除目录 fs.rmdir('hello',{ recursive:true,//递归删除目录,如果不指定则只能删除空目录 },err =>{ if(err){ console.log(err) }else{ console.log('删除目录成功') } })
3.6数据输入
有时候,需要从终端输入相关的信息,可以使用下面的例子
//数据输入 var readline=require('readline') //指定从终端读取和输入内容 var rl=readline.createInterface({ input:process.stdin, output:process.stdout }) //发送请求 rl.question('今晚吃的啥?',answer=>{ console.log(answer) //输入完成后就关闭 rl.close() }) //关闭时结束进程 rl.on('close',()=>{ process.exit(0) })
4.流Stream
4.1介绍
它是一个抽象接口,Node 中有很多对象实现了这个接口。对于大文件,使用普通的写入和读取是不科学的,可以使用流方式进行。
表-流类型
|
全称 |
简写 |
说明 |
|
Readable |
r |
可读操作 |
|
Writable |
w |
可写操作 |
|
Duplex |
d |
可读可写操作 |
|
Transform |
t |
操作被写入数据,然后读出结果 |
Stream常用事件
data 当有数据可读时触发。 end 没有更多的数据可读时触发。 error 在接收和写入过程中发生错误时触发。 finish 所有数据已被写入到底层系统时触发。
4.2输入流
通过流的方式把数据写到文件中
var fs = require('fs') //创建写入流 var ws = fs.createWriteStream('hello.txt') //监听文件打开事件 ws.on('open', () => { console.log('文件已打开') }) //监听数据写入完成事件 ws.on('finish', () => { console.log('数据写入完成') }) //监听文件关闭事件 ws.on('close', () => { console.log('文件已关闭') }) //写入数据 ws.write('你好啊,情人节', err => { if (err) { console.log(err) } }) //关闭流 ws.end()
后期对于流操作时,文件的关闭和打开事件可不监听。
4.3输出流
把文件的内容通过流的方法读出来
var fs = require('fs') var data = '' //创建可读流 var rs = fs.createReadStream('hello.txt') //监听文件打开事件 rs.on('open', () => { console.log('文件已打开') }) //监听处理流事件 rs.on('data', chunk => { data += chunk }) //监听流入结束事件 rs.on('end', chunk => { console.log(data) }) //监听文件关闭事件 rs.on('close', () => { console.log('文件已关闭') })
4.4管道
提供了一个输出流到输入流的机制,即把读取的流放到输入流,写入文件,用起来非常方便。
//管道流 // 创建一个可读流 var readerStream = fs.createReadStream('hello.txt'); // 创建一个可写流 var writerStream = fs.createWriteStream('output.txt'); // 管道读写操作:读取 input.txt 文件内容,并将内容写入到 output.txt 文件中 readerStream.pipe(writerStream); console.log("复制完毕");
5.事件event
Node.js 是单进程单线程应用程序,基本上所有的事件机制都是用设计模式中观察者模式实现
// 引入 events 模块 var events = require('events'); //创建 eventEmitter 对象 var eventEmitter = new events.EventEmitter() function connection(f) { console.log('我是connection方法,我被执行了' + f) } //绑定函数,指定事件的名称 eventEmitter.on('conn', connection) //在某一时刻触发事件 setTimeout(function () { //触发事件并传递参数 eventEmitter.emit('conn', 123) }, 2000);
注册好的事件,等待某一时刻触发,就会执行注册的方法。
6.路径模块path
路径模块,主要的对文件的路径进行操作。下面的实例中,包含文件的扩展名、目录全路径、文件全路径以及路径解析等。
xar path = require('path') var filePath="E://files/项目记录.txt" //获取文件的扩展名 var extname = path.extname(filePath) console.log(extname)//.txt //获取当前目录的完整路径 var dirName=__dirname console.log(dirName)//E:projectdemo ode-demo //获取当前执行文件的完整路径 var fileName=__filename console.log(fileName)//E:projectdemo ode-demopath.js //路径拼接 var p1=path.join('C:','files','text','t1.html')//C:files ext 1.html console.log(p1) //获取路径的所在目录路径 console.log(path.dirname(filePath)) //解析路径,返回的是一个对象,包含文件的基本信息 console.log(path.parse(filePath))
7.系统模块os
系统模块主要用来获取操作系统相关的参数
var os=require('os') //获取操作系统的cpu信息 console.log(os.cpus()) //内存 console.log(os.totalmem()) //系统架构 console.log(os.arch()) //剩余内存 console.log(os.freemem()) //主机名 console.log(os.hostname()) //操作系统类型 console.log(os.platform())
8.网址url
网址模块主要用来解析url的相关信息
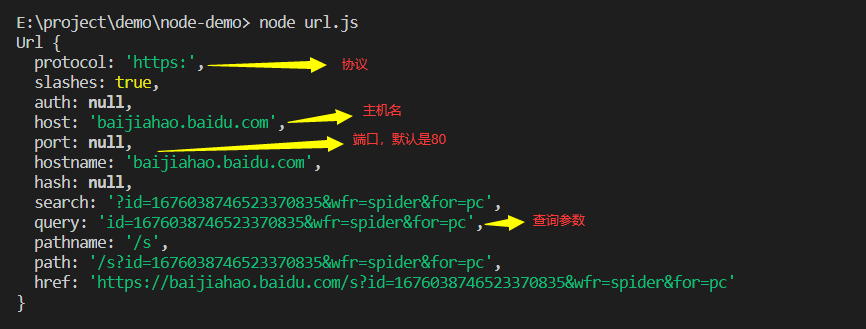
var url=require('url') const { hostname } = require('os') var httpUrl='https://baijiahao.baidu.com/s?id=1676038746523370835&wfr=spider&for=pc' //把url进行格式化 var parseObj=url.parse(httpUrl) console.log(parseObj)
格式化参数解析:
9.cheerio
cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现。适合各种Web爬虫程序。
它不是nodejs自动的库,需要进行安装,命令是
npm i cheerio
9.1爬取网站的表情包
//需要安装,npm i cheerio var cheerio =require('cheerio') //需要安装,npm i axios var axios = require('axios') var fs = require('fs') var path = require('path') var httpUrl="https://www.doutula.com/photo/list/?page=2" axios.get(httpUrl).then(res=>{ //解析html文件 var $ =cheerio.load(res.data) //获取图片的链接 $("#pic-detail .list-group-item .page-content a").each((i,elem)=>{ parseUrl($(elem).attr("href")) }) }) async function parseUrl(url) { //通过点击a标签去查询图片地址 var res = await axios.get(url) var $ = cheerio.load(res.data) $(".pic-content .swiper-slide img").each((i, elem) => { var src=$(elem).attr("src") var title=$(elem).attr("alt") var extname=path.extname(src) var ws = fs.createWriteStream(`img/${title}${extname}`) axios.get(src,{responseType:'stream'}).then(res=>{ res.data.pipe(ws) }) }) }
在爬取的时候,通过流的方式保存文件,因此这请求时要指定响应类型为stream。
10.Puppeteer
10.1介绍
谷歌官方出品的一个通过DevTools协议控制headless Chrome的Node库。可以通过Puppeteer的提供的api直接控制Chrome模拟大部分用户操作来进行UI Test或者作为爬虫访问页面来收集数据。
作用:生成页面 PDF。抓取 SPA(单页应用)并生成预渲染内容。自动提交表单,进行 UI 测试,键盘输入等
中文文档:https://zhaoqize.github.io/puppeteer-api-zh_CN/#/
需要安装使用:
npm i puppeteer
10.2基本使用
下面的实例可以保存网页的部分截图,也能把网页信息保存为pdf
var puppeteer = require('puppeteer') async function test() { var option={ //headless为false是关闭headless模式,配置为有界面调试 // headless: false , //设置视窗的大小 defaultViewport:{ 1920, height:1096 } } //创建browser的实例 const browser = await puppeteer.launch(option) //打开新页面 const page = await browser.newPage() //访问页面 await page.goto('https://www.cnblogs.com/zys2019/p/13323889.html') //把当前的页面截图保存 await page.screenshot({ path: 'example.png' }) //把当前页面保存为pdf,只能在headless为true时调用 await page.pdf({path: 'example.pdf', format: 'A4'}) //关闭浏览器实例 await browser.close() } test()
11.http
开启一个本地服务器需要Node.js中http核心模块
var http = require('http') //创建服务器对象 let server = http.createServer() //监听服务的请求 server.on('request', (req, res) => { //req是请求的信息,res是响应信息 var url = req.url//请求的url var header = req.headers//请求头信息 //设置响应编码 res.setHeader('Content-Type', 'text/plain; charset=UTF-8') //设置响应的信息 res.end('hello world,你好') }) //监听端口号,在启动服务时就触发 server.listen(3000, () => { console.log('服务器已启动') })
启动后,使用本机ip+3000即可访问
12.node连接mysql数据库
需要安装后使用:
npm i mysql
连接数据库并操作
//引入模块 let mysql = require('mysql') //配置连接参数 let options = { host: "localhost", user: "root", password: "zys123456", database: "db2020" } //创建连接 let conn = mysql.createConnection(options) //连接到数据库 conn.connect(err => { if (err) { console.log('连接失败,错误:' + err) } else { console.log('连接成功') } }) //执行sql语句,所有的操作都是使用query方法,里面传入sql即可 let sql = 'select * from user' //查询数据,err是报错信息,results是查询结果,fields是数据库信息。 conn.query(sql, (err, results, fields) => { if (err) { console.log('查询失败,错误:' + err) } else { console.log(results) } })
.