一、中断顶-底半部分
1.1 什么是中断顶-底半部分
linux操作系统是多个进程执行,宏观上达到并行运行的状态,外设中断则会打断内核中任务调度和运行,如果中断函数耗时过长则使得系统实时性和并发性降低。
为保证系统实时性,中断服务程序必须足够简短,但实际应用中某些时候发生中断时必须处理大量的事务,这时候如果都在中断服务程序中完成,则会严重降低中断的实时性,基于这个原因,linux系统提出了一个概念:把中断服务程序分为两部分:顶半部-底半部。
- 顶半部(top half):完成尽可能少的比较紧急的任务,它往往只是简单的读取寄存器中的中断状态并清除中断标志后就进行”登记中断“(也就是将底半部处理程序挂到设备的底半部执行队列中)的工作;
- 底半部(bottom half):中断处理的大部分工作都在底半部,它几乎做了中断处理程序的所有事情;
1.2 bottom half和top half区别
Linux中断顶-底半部分区别:
- 顶半部由外设中断触发,底半部由顶半部触发;
- 顶半部不会被其他中断打断,底半部是可以被打断的;
- 顶半部分处理任务要快,主要任务、耗时任务放在底半部;
一般来说,在中断顶半部执行完毕,底半部即在内核的调度下被执行,当然如果有其他更高优先级需处理的任务,会先处理该任务再调度处理底半部,或者在系统空闲时间进行处理。
我们在之前章节分析的关于硬件中断的执行流程部分(request_threaded_irq注册的primary handler、threaded interrupt handler),均是属于中断顶半部。
我们在这一节,将会介绍中断底半部分,linux中的底半部的实现有三种,也就是本文要讨论的软中断、tasklet和工作队列。
二、软中断
2.1 什么是软中断
软中断,英文叫做softirq,软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。
软中断一般是“可延迟函数”的总称,有时候也包括了tasklet,它的出现就是因为要满足上面所提出的顶半部和底半部的区别,使得对时间不敏感的任务延后执行,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
- 产生后并不是马上可以执行,必须要等待内核的调度才能执行,软中断不能被自己打断,即单个CPU上软中断不能嵌套执行,只能被硬件中断打断(顶半部);
- 可以并发运行在多个CPU上,即使同一类型的也可以,所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保其数据结构;
2.2 软中断编号
向硬件中断IRQ 编号一样,对于软中断,linux内核也是用一个softirq编号唯一标识一个softirq,在Linux中,softirq的限制是不能超过32个,内核目前只实现了10种类型的软件中断,定义在include/linux/interrupt.h文件中,它们是:
/* PLEASE, avoid to allocate new softirqs, if you need not _really_ high frequency threaded job scheduling. For almost all the purposes tasklets are more than enough. F.e. all serial device BHs et al. should be converted to tasklets, not to softirqs. */ enum { HI_SOFTIRQ=0, TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, BLOCK_SOFTIRQ, IRQ_POLL_SOFTIRQ, TASKLET_SOFTIRQ, SCHED_SOFTIRQ, HRTIMER_SOFTIRQ, /* Unused, but kept as tools rely on the numbering. Sigh! */ RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ NR_SOFTIRQS };
其中:
- HI_SOFTIRQ用于高优先级的tasklet,TASKLET_SOFTIRQ用于普通的tasklet;
- TIMER_SOFTIRQ是for software timer的(所谓software timer就是说该timer是基于系统tick的)。
- NET_TX_SOFTIRQ和NET_RX_SOFTIRQ是用于网卡数据收发的;
- BLOCK_SOFTIRQ和BLOCK_IOPOLL_SOFTIRQ是用于block device的
- SCHED_SOFTIRQ用于调度器,实现SMP系统上周期性的负载均衡;
- 在启用高分辨率定时器时,还需要一个HRTIMER_SOFTIRQ;
- RCU_SOFTIRQ是处理RCU的;
这些软中断的名称由以下数组表示:
const char * const softirq_to_name[NR_SOFTIRQS] = { "HI", "TIMER", "NET_TX", "NET_RX", "BLOCK", "BLOCK_IOPOLL", "TASKLET", "SCHED", "HRTIMER", "RCU" };
我们可以通过如下命令查看:
[root@Test ~]# cat /proc/softirqs CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 HI: 0 0 0 0 0 0 0 0 TIMER: 247669703 211785731 150551356 125734616 110698337 78356824 98387200 110881376 NET_TX: 1 3 5 3 14 1647534 3 4 NET_RX: 1524262 25284869 28642718 25840919 24374590 21304217 16286849 15722184 BLOCK: 258979 223129 173947 4182170 458080 96025 126855 158996 BLOCK_IOPOLL: 0 0 0 0 0 0 0 0 TASKLET: 22 10801 9380 1507 1370 1062906 4205 2579 SCHED: 81928982 67596224 48780904 45278621 38129908 27365571 32233378 41949728 HRTIMER: 0 0 0 0 0 0 0 0 RCU: 127403767 114224252 85461010 72271026 63809076 49277288 52600085 61792443
2.3 softirq描述符
softirq是静态定义的,也就是说系统中有一个定义softirq描述符的数组,该数组定义在kernel/softirq.c文件中,softirq编号就是这个数组的index:
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
这里的NR_SOFTIRQS恰好是softirq编号的最大值。
内核用softirq_action结构管理软件中断的注册和激活等操作,它的定义如下:
struct softirq_action { void (*action)(struct softirq_action *); };
非常简单,只有一个用于回调的函数指针。
2.4 irq_cpustat_t
多个软中断可以同时在多个cpu运行,就算是同一种软中断,也有可能同时在多个cpu上运行。内核为每个cpu都管理着一个待决软中断变量(pending),它就是irq_cpustat_t,定义在arch/arm/include/asm/hardirq.h:::
typedef struct { unsigned int __softirq_pending; #ifdef CONFIG_SMP unsigned int ipi_irqs[NR_IPI]; #endif } ____cacheline_aligned irq_cpustat_t;
irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
__softirq_pending字段中的每一个bit,对应着某一个软中断,某个bit被置位,说明有相应的软中断等待处理。
2.5 ksoftirqd
在cpu的热插拔阶段,内核为每个cpu创建了一个用于执行软件中断的守护线程ksoftirqd,同时在kernel/softirq.c文件中定义了一个per_cpu变量用于保存每个守护线程的task_struct结构指针:
DEFINE_PER_CPU(struct task_struct *, ksoftirqd);
root@zhengyang:/work/linux-5.2.8-bak# ps -ef | grep ksoftirq root 7 2 0 04:36 ? 00:00:00 [ksoftirqd/0] root 16 2 0 04:36 ? 00:00:00 [ksoftirqd/1] root 22 2 0 04:36 ? 00:00:00 [ksoftirqd/2] root 28 2 0 04:36 ? 00:00:04 [ksoftirqd/3] root 119631 81636 0 23:06 pts/2 00:00:00 grep --color=auto ksoftirq
三、软件中断的安装
3.1 注册softirq
通过调用open_softirq接口函数可以注册softirq的action回调函数,该函数定义在kernel/softirq.c:
void open_softirq(int nr, void (*action)(struct softirq_action *)) { softirq_vec[nr].action = action; }
即注册对应类型的处理函数到全局数组softirq_vec中。例如网络发包对应类型为NET_TX_SOFTIRQ的处理函数net_tx_action。
3.2 HI_SOFTIRQ和TASKLET_SOFTIRQ注册
在softirq初始化函数中,完成了HI_SOFTIRQ和TASKLET_SOFTIRQ的执行函数的注册:
void __init softirq_init(void) { int cpu; for_each_possible_cpu(cpu) { per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head; per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head; } open_softirq(TASKLET_SOFTIRQ, tasklet_action); open_softirq(HI_SOFTIRQ, tasklet_hi_action); }
3.3 TIMER_SOFTIRQ注册
其他的一些softirq,则是在各自模块里初始化的,比如TIMER_SOFTIRQ的执行函数是在init_timers里实现注册的:
void __init init_timers(void) { init_timer_cpus(); open_softirq(TIMER_SOFTIRQ, run_timer_softirq); }
四、理解软中断需要的基础知识
4.1 preempt_count
为了更好的理解下面的内容,我们需要先看看一些基础知识:一个task的thread info数据结构定义如下(只保留和本场景相关的内容):
struct thread_info { …… int preempt_count; /* 0 => preemptable, <0 => bug */ …… };
preempt_count这个成员被用来判断当前进程是否可以被抢占:
- 如果preempt_count不等于0(可能是代码调用preempt_disable显式的禁止了抢占,也可能是处于中断上下文等),说明当前不能进行抢占;
- 如果preempt_count等于0,说明已经具备了抢占的条件(当然具体是否要抢占当前进程还是要看看thread info中的flag成员是否设定了_TIF_NEED_RESCHED这个标记,可能是当前的进程的时间片用完了,也可能是由于中断唤醒了优先级更高的进程);
具体preempt_count的数据格式可以参考下图:
| 保留 | 21 | [20] | [19:16] | [15:9] | [8] | [7:0] |
| Preempt active | NMI flag | hardirq count | softirq count | softirq context | preemption count |
- preemption count用来记录当前被显式的禁止抢占的次数,也就是说,每调用一次preempt_disable,preemption count就会加一,调用preempt_enable,该区域的数值会减去一。preempt_disable和preempt_enable必须成对出现,可以嵌套,最大嵌套的深度是255。
- hardirq count描述当前硬件中断handler嵌套的深度。hardirq count占用了4个bit,说明硬件中断handler最大可以嵌套15层。实际上在linux中一个中断并不会发生嵌套,不同的中断可能发生。
- sortirq count描述当前软件中断handler嵌套的深度:
- 由于softirq handler在一个CPU上是不会并发的,总是串行执行,因此,这个场景下只需要一个bit就够了,也就是上图中的bit 8。通过该bit可以知道当前task是否在sofirq context。
- 由于内核同步的需求,进程上下文需要禁止softirq。这时候,kernel提供了local_bh_enable和local_bh_disable这样的接口函数。这部分的概念是和preempt disable/enable类似的,占用了bit9~15,最大可以支持127次嵌套。
4.2 一个task各种上下文
看完了preempt_count之后,我们来介绍各种context:
#define preempt_count() (current_thread_info()->preempt_count) 利用preempt_count可以表示是否处于中断处理或者软件中断处理过程中,如下所示: # define hardirq_count() (preempt_count() & HARDIRQ_MASK) #define softirq_count() (preempt_count() & SOFTIRQ_MASK) #define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK)) #define in_irq() (hardirq_count()) #define in_softirq() (softirq_count()) #define in_interrupt() (irq_count())
这里有各种中断上下文:
- irq context其实就是hardirq context,也就是说明当前正在执行硬件中断处理程序(top half),只要preempt_count中的hardirq count大于0,那么就是irq context;
- softirq context并没有那么的直接,一般人会认为当sofirq handler正在执行的时候就是softirq context。这样说当然没有错,sofirq handler正在执行的时候,会增加softirq count,当然是softirq context。不过,在其他context的情况下,例如进程上下文中,有有可能因为同步的要求而调用local_bh_disable,这时候,通过local_bh_disable/enable保护起来的代码也是执行在softirq context中。当然,这时候其实并没有正在执行softirq handler。如果你确实想知道当前是否正在执行softirq handler,in_serving_softirq可以完成这个使命,这是通过操作preempt_count的bit 8来完成的;
- 所谓中断上下文,就是irq context + softirq context+NMI context ;
4.3 软中断的触发
软中断的触发时机:
- irq_exit:在硬中断退出时,会检查local_softirq_pending和in_interrupt,如果都符合条件,则执行软中断;
- local_bh_enable:使用此函数开启软中断时,会检查in_interrupt和local_softirq_pending,如果都符合条件,则执行软中断。调用链为local_bh_enable->__local_bh_enable->do_softirq;
- raise_softirq:设置当前CPU的__softirq_pending中对应的软中断pending,然后唤醒软中断守护线程,执行__do_softirq;
五、raise_softirq
5.1 raise_softirq
void raise_softirq(unsigned int nr) { unsigned long flags; local_irq_save(flags); // 关闭本地cpu中断 raise_softirq_irqoff(nr); local_irq_restore(flags); // 恢复cpu中断状态 }
raise_softirq 函数使用 local_irq_save 和 local_irq_store 函数在 raise_softirq_irqoff 函数执行期间进行中断同步:
- 先是通过local_irq_save函数将当前中断状态(开或者关)保存到flags,然后关闭本地cpu中断;
- 最后通过local_irq_restore函数将保存的flags状态值恢复,恢复之前的状态(开或关);调用 local_irq_restore后不一定会开启中断,只会恢复调用 local_irq_save之前的中断状态,如果调用 local_irq_save之前是开中断,那么就打开中断; 如果调用 local_irq_save之前是关中断,那么就关闭中断。
5.2 raise_softirq_irqoff
/* * This function must run with irqs disabled! */ inline void raise_softirq_irqoff(unsigned int nr) { __raise_softirq_irqoff(nr); /* * If we're in an interrupt or softirq, we're done * (this also catches softirq-disabled code). We will * actually run the softirq once we return from * the irq or softirq. * * Otherwise we wake up ksoftirqd to make sure we * schedule the softirq soon. */ if (!in_interrupt()) wakeup_softirqd(); }
将输入参数 nr 的左移值传递给 or_softirq_pending 函数:
void __raise_softirq_irqoff(unsigned int nr) { trace_softirq_raise(nr); or_softirq_pending(1UL << nr); }
之前我们介绍过irq_stat[NR_CPUS] __softirq_pending字段中的每一个bit,对应着某一个软中断。因此这里通过__raise_softirq_irqoff将当前CPU的__softirq_pending中对应的软中断pending位置1,即等价如下代码:
((irq_stat[(current_thread_info()->cpu)].__softirq_pending) |= (1UL << nr));
这也是同一类型软中断可以在多个CPU上并行运行的根本原因。
然后通过in_interrupt,如果不处于中断上下文中,则唤醒软中断的守护进程,在守护进程中执行软中断的回调函数;其中wakeup_softirqd会唤醒当前CPU的ksoftirqd守护进程:
static void wakeup_softirqd(void) { struct task_struct *tsk = __this_cpu_read(ksoftirqd); if (tsk && tsk->state != TASK_RUNNING) wake_up_process(tsk); }
5.3 ksoftirqd
当大量软中断出现的时候,内核会唤醒一组内核线程来处理。这些线程的优先级最低(nice值为19),这能避免它们跟其它重要的任务抢夺资源。
但它们最终肯定会被执行,所以这个折中的方案能够保证在软中断很多时用户程序不会因为得不到处理时间而处于饥饿状态,同时也保证过量的软中断最终会得到处理。
每个处理器都有一个这样的线程,名字为ksoftirqd/n,n为处理器的编号:
static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", };
static void run_ksoftirqd(unsigned int cpu) { local_irq_disable(); // 关闭本地CPU中断,防止硬件中断抢占 if (local_softirq_pending()) { // 如果有要处理的软中断 /* * We can safely run softirq on inline stack, as we are not deep * in the task stack here. */ __do_softirq(); // 处理软中断 local_irq_enable(); // 开启本地CPU中断 cond_resched(); return; } local_irq_enable(); // 开启本地CPU中断 }
六、irq_enter和irq_exit
我们在分析发生硬件中断,执行中断处理程序的源码时,我们介绍了__handle_domain_irq函数,其中irq_enter和irq_exit函数分别用于标记generic handler的进入和退出。
/** * __handle_domain_irq - Invoke the handler for a HW irq belonging to a domain * @domain: The domain where to perform the lookup * @hwirq: The HW irq number to convert to a logical one * @lookup: Whether to perform the domain lookup or not * @regs: Register file coming from the low-level handling code * * Returns: 0 on success, or -EINVAL if conversion has failed */ int __handle_domain_irq(struct irq_domain *domain, unsigned int hwirq, bool lookup, struct pt_regs *regs) { struct pt_regs *old_regs = set_irq_regs(regs); unsigned int irq = hwirq; int ret = 0; irq_enter(); // 更新一些系统统计信息,禁止内核抢占 #ifdef CONFIG_IRQ_DOMAIN if (lookup) irq = irq_find_mapping(domain, hwirq); // 根据中断域和硬件中断号获取IRQ编号 #endif /* * Some hardware gives randomly wrong interrupts. Rather * than crashing, do something sensible. */ if (unlikely(!irq || irq >= nr_irqs)) { // 中断号超出范围 ack_bad_irq(irq); ret = -EINVAL; } else { generic_handle_irq(irq); // 重点时这里 } irq_exit(); // 退出的时候会检查是否由软中断,如果有。则调用软中断 set_irq_regs(old_regs); return ret; }
那irq_enter和irq_exit究竟做了什么事情呢?
6.1 irq_enter
我们先来看看irq_enter,其定义在kernel/softirq.c:
/* * Enter an interrupt context. */ void irq_enter(void) { rcu_irq_enter(); if (is_idle_task(current) && !in_interrupt()) { /* * Prevent raise_softirq from needlessly waking up ksoftirqd * here, as softirq will be serviced on return from interrupt. */ local_bh_disable(); tick_irq_enter(); // 空函数 _local_bh_enable(); } __irq_enter(); }
如果当前任务空闲,并且不处于中断上下文中,则执行如下操作:
- 关闭当前CPU底半部中断,在local_bh_disable中将current thread info上的preempt_count成员中的softirq count的加SOFTIRQ_DISABLE_OFFSET。
- 开启当前CPU底半部中断,在local_bh_disable中将current thread info上的preempt_count成员中的softirq count的减SOFTIRQ_DISABLE_OFFSET。
在__irq_enter()中会调用preempt_count_add(HARDIRQ_OFFSET),为hardirq count的bit field增加1,标记我们当前处于硬件中断上下文,即开始top half处理:
/* * It is safe to do non-atomic ops on ->hardirq_context, * because NMI handlers may not preempt and the ops are * always balanced, so the interrupted value of ->hardirq_context * will always be restored. */ #define __irq_enter() \ do { \ account_irq_enter_time(current); \ preempt_count_add(HARDIRQ_OFFSET); \ // hadrdirq count +1 trace_hardirq_enter(); \ } while (0)
6.2 irq_exit
然后我们再来看看irq_exit:
/* * Exit an interrupt context. Process softirqs if needed and possible: */ void irq_exit(void) { #ifndef __ARCH_IRQ_EXIT_IRQS_DISABLED local_irq_disable(); #else lockdep_assert_irqs_disabled(); #endif account_irq_exit_time(current); preempt_count_sub(HARDIRQ_OFFSET); // hardirq count - 1 if (!in_interrupt() && local_softirq_pending()) invoke_softirq(); tick_irq_exit(); rcu_irq_exit(); trace_hardirq_exit(); /* must be last! */ }
在irq_exit函数中,首先调用preempt_count_sub(HARDIRQ_OFFSET),为hardirq count的bit field减去1,即标记当前不是硬件中断上下文,即top half处理完成。
然后检查两个条件后,决定是否执行softirq服务:
- 一是检查当前执行的代码是否在中断上下文中;
- 二是检查是否有softirq服务请求;
if (!in_interrupt() && local_softirq_pending())宏展开后,等价于:
if (!((preempt_count() & (((1UL << (4))-1) << ((0 + 8) + 8)) | (((1UL << (8))-1) < < (0 + 8)) | (((1UL << (1))-1) << (((0 + 8) + 8) + 4))))) &&
(irq_stat[(current_thread_info()-> cpu)].__softirq_pending))
这里调用in_interrupt是为了确保当前不在中断上下文中,也就是说当前线程没在执行硬件中断处理、或者执行软中断处理。
如果条件满足,就调用invoke_softirq来触发softirq的处理流程。
6.3 invoke_softirq
在kernel/softirq.c中:
static inline void invoke_softirq(void) { if (ksoftirqd_running(local_softirq_pending())) return; if (!force_irqthreads) { #ifdef CONFIG_HAVE_IRQ_EXIT_ON_IRQ_STACK // 没定义 /* * We can safely execute softirq on the current stack if * it is the irq stack, because it should be near empty * at this stage. */ __do_softirq(); #else /* * Otherwise, irq_exit() is called on the task stack that can * be potentially deep already. So call softirq in its own stack * to prevent from any overrun. */ do_softirq_own_stack(); #endif } else { wakeup_softirqd(); } }
如果将 force_irqthreads 变量设置为 1,则调用 wakeup_softirqd 函数来唤醒 ksofrrqd 线程。该变量是通过在引导 linux 内核之前将 threadirqs 传递到引导加载程序中的命令行来设置的,默认设置为0,命令行的作用类似于在引导 linux 内核时传递给引导加载程序的参数。当 linux 内核启动时,会读取该命令行来配置内核系统。
do_softirq_own_stack 函数直接调用 __do_softirq 函数:
void __softirq_entry __do_softirq(void) { struct softirq_action *h = softirq_vec; int softirq_bit; __u32 pending = local_softirq_pending(); // 获取irq_stat[cpu].__softirq_pending __local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET); /* Reset the pending bitmask before enabling irqs */ set_softirq_pending(0); local_irq_enable(); // 开启当前CPU中断,以下代码运行时可能被硬件中断抢占,但这个硬件中断执行完成后,如果它注册有软中断,那这个软中断无法立即执行 ... while ((softirq_bit = ffs(pending))) { h += softirq_bit - 1; h->action(h); h++; // 下一个软中断 pending >>= softirq_bit; // 下一个软中断状态标志位 ... } if (__this_cpu_read(ksoftirqd) == current) rcu_softirq_qs(); local_irq_disable(); // 关闭当前CPU中断 restart: pending = local_softirq_pending(); // 软中断执行期间,有新的软中断产生 if (pending) { if (time_before(jiffies, end) && !need_resched() && // 防止陷入死循环,加入软中断处理时间和处理次数限制 --max_restart) goto restart; wakeup_softirqd(); // 交给守护线程处理 } __local_bh_enable(SOFTIRQ_OFFSET); }
当前pending位图中可能有多个待处理的softirq,__do_softirq会按照它们在位图中的顺序,也就是用ffs找到位图中从右(LSB)到左(MSB)第一个非0的bit,依次执行该bit对应的处理函数。

softirq在pending位图中的顺序同时也是它们在softirq_vec[]数组中编号的顺序,这里编号形成的优先级并不影响不同softirq的执行频率,只是定义了它们同时pending时的执行次序。
__do_softirq是紧接着"hardirq"执行的,它也是运行在中断上下文,如果非要和"hardirq上下文"有所区分的话,可以认为这是"softirq上下文",在softirq上下文中,也是不能睡眠的。
6.4 sotirq的抢占
在__do_softirq函数的开始和结尾,分别执行了以下操作:
- 关闭软中断,开启当前CPU硬件中断;
- 遍历执行软中断处理函数;
- 关闭当前CPU硬件中断,开启软中断;
也就是在执行软中断的过程中,不会被其它的sotfirq抢占,但是在softirq执行期间,硬件中断是打开的,也就是说softirq可能被hardirq抢占(在hardirq执行期间,一般硬件中断是被屏蔽的)。如果不考虑内核的实时特性和中断线程化,那么softirq也不会被更高优先级的线程所抢占。
自从Linux 2.6.32之后,中断处理函数不再使用被其打断的线程的栈,而是使用独立的per-cpu的栈,并且softirq和hardirq会有不同的栈,这意味着每个CPU都对应一个softirq的栈和一个hardirq的栈。
DEFINE_PER_CPU(struct irq_stack *, hardirq_stack); DEFINE_PER_CPU(struct irq_stack *, softirq_stack);
一个softirq在被硬件中断打断后,softirq_stack会记录当前softirq的上下文(入栈),然后CPU转去执行hardirq里的程序,同时指向softirq_stack的栈指针也会转而指向hardirq_stack。

以上图为例:
- task A在执行的过程,触发了interrupt 1,此时会执行hardirq 1,hardirq 1在执行过程中,在执行完毕后,会触发软中断的执行,这里以softirq 1为例:
- 由于softirq 1会被硬件中断抢占,当触发了interrupt 2,此时会执行hardirq 2,当hardirq 2执行完毕,此时会去执行irq_exit,由于软中断的触发条件没有满足;
- 然后CPU会跳回之前被打断的那个softirq 1继续执行,softirq_stack保存的上下文也将被恢复(出栈),直到这个被打断的softirq执行完毕;
- 然后根据softirq的pending位图重新选择待处理的softirq来执行,如果hardirq 2在执行期间设置softirq的pedning位,那么新的softirq将会被执行;
- 如果软中断连续出现多次或者执行超时后就不再继续在bottom half执行软中断,而是将其放到ksoftirqd内核线程中继续执行;
在多核系统中,同一种softirq的处理函数可以在不同的CPU上运行,这样可以利用多核的并行特性,带来更好的性能,但是如果sofirq的处理函数中含有全局变量,就可能涉及到spinlock等多核同步机制,增加复杂性。
6.5 总结
在中断的top half处理完后,就会通过raise_softirq设置softirq的pending位图,这个pending位图由一个名为"__softirq_pending"的per-CPU形式的变量表示。
而后在irq_exit中通过local_softirq_pending查看pending位图中是否有待处理的softirq,如果有,就调用invoke_softirq()来触发softirq的处理流程。

七 local_bh_enable/disable
在linux kernel中,可以使用local_irq_disable和local_irq_enable来disable和enable本CPU中断(指的是硬件中断)。
和硬件中断一样,软中断也可以disable,接口函数是local_bh_disable和local_bh_enable。虽然和想像的local_softirq_enable/disable有些出入,不过bh这个名字更准确反应了该接口函数的意涵,因为local_bh_disable/enable函数就是用来disable/enable bottom half的,这里就包括softirq和tasklet。
7.1 同步机制
线程被硬件中断打断后,如果希望执行完hardirq后就直接返回原来的线程,而不去执行pending的softirq,那么可以选择屏蔽softirq,用local_bh_disable函数来屏蔽softirq。

在local_bh_disable期间,线程虽然屏蔽了softirq,但可能没有屏蔽硬件中断,而如果发生了硬件中断,又将会产生pending且不能执行的softirq,所以在调用local_bh_enable打开softirq时,会检查in_interrupt和local_softirq_pending,如果满足条件将会执行do_softirq。
执行被local_bh_disable和local_bh_enable包围的代码区域时,由于softirq是被屏蔽的,因而在这段时间里也是不能睡眠的,也是处在“softirq上下文”。
虽然都是在softirq上下文,但还是有办法将这种情况和softirq正在运行的情况区分开来,靠的也是preempt_count。
local_bh_disable(); /* critical section */ local_bh_enable();
实际上local_bh_disable和local_bh_enable也是一种内核的同步机制:
- 在硬件中断的handler(top half)中,不应该调用disable/enable bottom half函数来保护共享数据,因为softirq其实是不可能抢占top half的;
- local_bh_enable/disable是给线程/进程上下文使用的,用于防止softirq抢占local_bh_enable/disable之间的临界区的;
7.2 屏蔽softirq
在include/linux/bottom_half.h中有local_bh_disable定义:
static inline void local_bh_disable(void) { __local_bh_disable_ip(_THIS_IP_, SOFTIRQ_DISABLE_OFFSET); } static __always_inline void __local_bh_disable_ip(unsigned long ip, unsigned int cnt) { preempt_count_add(cnt); barrier(); }
看起来disable bottom half比较简单,就是将current thread info上的preempt_count成员中的softirq count的加1。
7.3 开启softirq
local_bh_enable函数比较复杂,如下:
static inline void local_bh_enable(void) { __local_bh_enable_ip(_THIS_IP_, SOFTIRQ_DISABLE_OFFSET); } void __local_bh_enable_ip(unsigned long ip, unsigned int cnt) { WARN_ON_ONCE(in_irq() || irqs_disabled()); preempt_count_sub(cnt - 1); if (unlikely(!in_interrupt() && local_softirq_pending())) { do_softirq(); } preempt_count_dec(); preempt_check_resched(); }
7.4 总结
线程既可能被softirq抢占,也可能被硬件中断抢占,而softirq通常只会被硬件中断抢占,如果在线程或者softirq执行期间不希望被硬件中断抢占,那么可以使用local_irq_disable/local_irq_save函数。
八、tasklet
在上面我们介绍了软中断机制,linux内核为什么还要引入tasklet机制呢?
主要因为是软中断的__softirq_pending标志位最多也就32位,因此softirq的限制是不能超过32个,一般情况下是不随意增加软中断处理的。而且内核也没有提供通用的增加软中断的接口。
由于软中断必须设计为可重入的函数(即同一类型的软中断,允许多个CPU同时操作),因此需要使用自旋锁来保其数据结构;这样就会导致设计上的复杂度变高,为了解决这种问题,内核提供了tasklet这样的一种通用的机制。它具有以下特性:
- 一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行;
- 多个不同类型的tasklet可以并行在多个CPU上;
- 软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
8.1 taskle数据结构
8.1.1 struct tasklet_struct结构体
对于tasklet,linux内核使用struct tasklet_struct来描述,定义在include/linux/interrupt.h文件中:
/* Tasklets --- multithreaded analogue of BHs. Main feature differing them of generic softirqs: tasklet is running only on one CPU simultaneously. Main feature differing them of BHs: different tasklets may be run simultaneously on different CPUs. Properties: * If tasklet_schedule() is called, then tasklet is guaranteed to be executed on some cpu at least once after this. * If the tasklet is already scheduled, but its execution is still not started, it will be executed only once. * If this tasklet is already running on another CPU (or schedule is called from tasklet itself), it is rescheduled for later. * Tasklet is strictly serialized wrt itself, but not wrt another tasklets. If client needs some intertask synchronization, he makes it with spinlocks. */ struct tasklet_struct { struct tasklet_struct *next; // 将多个tasklet链接成单向循环链表 unsigned long state; // 状态标志位 atomic_t count; //0:激活tasklet 其他:禁用 tasklet void (*func)(unsigned long); // 用户自定义函数 unsigned long data; // 函数入参 };
同时在kernel/softirq.c定义了per-cpu变量tasklet_vec和tasklet_hi_vec:
/* * Tasklets */ struct tasklet_head { struct tasklet_struct *head; struct tasklet_struct **tail; }; static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec); static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
8.1.2 定义tasklet
//定义名字为name的激活tasklet #define DECLARE_TASKLET(name, func, data) \ struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data } //定义名字为name的非激活tasklet #define DECLARE_TASKLET_DISABLED(name, func, data) \ struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data } //动态初始化tasklet void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
8.1.3 tasklet操作
static inline void tasklet_disable(struct tasklet_struct *t) static inline void tasklet_enable(struct tasklet_struct *t) static inline void tasklet_schedule(struct tasklet_struct *t) void tasklet_kill(struct tasklet_struct *t) static inline void tasklet_hi_schedule(struct tasklet_struct *t)
8.2 tasklet调度
使用tasklet比较简单,只需要初始化一个tasklet_struct结构体,然后调用tasklet_schedule/tasklet_hi_schedule,就能利用tasklet机制执行初始化的func函数。
tasklet_schedule/tasklet_hi_schedule定义在include/linux/interrupt.h:
static inline void tasklet_schedule(struct tasklet_struct *t) { if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) __tasklet_schedule(t); }
static inline void tasklet_hi_schedule(struct tasklet_struct *t) { if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) __tasklet_hi_schedule(t); }
程序在多个上下文中可以多次调度同一个tasklet执行,也有可能来自多个cpu核,然后实际上只会有挂到首次调度的那个cpu的tasklet链表,也就是说,即使是多次调用tasklet_schedule,实际上只会调度一次执行,这也是用过TASKLET_STATE_SCHED这个标志位来实现的。
tasklet_schedule中第一行代码使用原子锁来实现进程/线程的同步,test_and_set_bit首先将t->state的第TASKLET_STATE_SCHED位设置成1,并返回原来这一位的值,也就是原来处于被调度状态TASKLET_STATE_SCHED,则直接返回了。
enum { TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */ TASKLET_STATE_RUN /* Tasklet is running (SMP only) */ };
__tasklet_schedule就是把tasklet_struct结构体挂到tasklet_vec链表上,并调度软中断 TASKLET_SOFTIRQ 。
__tasklet_schedule定义在kernel/softirq.c:
static void __tasklet_schedule_common(struct tasklet_struct *t, struct tasklet_head __percpu *headp, unsigned int softirq_nr) { struct tasklet_head *head; unsigned long flags; local_irq_save(flags); // 关闭本地cpu中断 head = this_cpu_ptr(headp); t->next = NULL; *head->tail = t; head->tail = &(t->next); raise_softirq_irqoff(softirq_nr); // 唤起软中断 local_irq_restore(flags); // 恢复cpu中断 } void __tasklet_schedule(struct tasklet_struct *t) { __tasklet_schedule_common(t, &tasklet_vec, TASKLET_SOFTIRQ); }
__tasklet_hi_schedule就是把tasklet_struct结构体挂到tasklet_hi_vec链表上,并调度软中断 HI_SOFTIRQ 。
void __tasklet_hi_schedule(struct tasklet_struct *t) { __tasklet_schedule_common(t, &tasklet_hi_vec, HI_SOFTIRQ); }
8.3 tasklet执行过程
TASKLET_SOFTIRQ对应执行函数为tasklet_action,HI_SOFTIRQ为tasklet_hi_action,以tasklet_action为例说明:
static void tasklet_action_common(struct softirq_action *a, struct tasklet_head *tl_head, unsigned int softirq_nr) { struct tasklet_struct *list; local_irq_disable(); // 关闭本地cpu硬件中断 list = tl_head->head; tl_head->head = NULL; tl_head->tail = &tl_head->head; local_irq_enable(); // 开启本地cpu硬件中断 while (list) { struct tasklet_struct *t = list; list = list->next; if (tasklet_trylock(t)) { //如果返回false,表示当前tasklet已经在其他CPU上运行,这一轮将会跳过此tasklet。确保同一个tasklet只能在一个CPU上运行。 if (!atomic_read(&t->count)) { // 读取到的为0,激活状态 if (!test_and_clear_bit(TASKLET_STATE_SCHED,&t->state)) ///清TASKLET_STATE_SCHED位;如果原来没有被置位,则返回0,触发BUG() BUG(); t->func(t->data); //执行当前tasklet处理函数 tasklet_unlock(t); continue; //跳到while继续遍历余下的tasklet } tasklet_unlock(t); } local_irq_disable(); t->next = NULL; *tl_head->tail = t; tl_head->tail = &t->next; __raise_softirq_irqoff(softirq_nr); local_irq_enable(); } } static __latent_entropy void tasklet_action(struct softirq_action *a) { tasklet_action_common(a, this_cpu_ptr(&tasklet_vec), TASKLET_SOFTIRQ); }
tasklet_action在软中断TASKLET_SOFTIRQ被调度到后会被执行:
- 它从tasklet_vec链表中把tasklet_struct结构体都取下来,然后逐个执行;
- 如果t->count的值不等于0,说明这个tasklet可能在某次调度之后,被disable掉了,所以会将tasklet结构体重新放回到tasklet_vec链表,并重新调度TASKLET_SOFTIRQ软中断,在之后enable这个tasklet之后重新再执行它;
九、工作队列
在介绍工作队列之前,我们先来回顾tasklet和softirq:
| softirq | tasklet | |
|---|---|---|
| 分配 | softirq是静态定义的 | tasklet既可以静态定义,也可以通过tasklet_init()动态创建 |
| 并发性 | softirq是可重入的,同一类型的软中断可以在多个CPU上并发执行。 | tasklet是不可重入的,tasklet必须串行执行,同一个tasklet不可能同时在两个CPU上运行。tasklet通过TASKLET_STATE_SCHED和TASKLET_STATE_RUN保证串行 |
| 运行 |
softirq运行在开中断环境下; 软中断回调函数不能睡眠,因为软中断可能处于中断上下文中,睡眠导致Linux无法调度; 软中断的执行时机可能在:
|
taskelt执行时机在softirq中 |
我们知道softirq运行在开中断环境中,因此软中断回调函数不能睡眠/堵塞,而tasklet使用软中断实现,当然也不能睡眠/堵塞,但如果某延迟处理函数需要睡眠或者阻塞呢?
工作队列实际上即使解决这个问题的。
9.1 工作队列介绍
在介绍之前我们先来梳理几个概念:
- 工作队列中把推后执行的任务叫做工作(work),描述它的数据结构为work_struct ;
- 这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct ;
- 而工作线程(worker)就是负责执行工作队列中的工作;
在老版本的linux系统中,一个CPU上只可以运行一个工作线程,这就导致如果存在多个work,所有work执行完的效率较低,尤其是每个work都存在睡眠的情况下。
因此在后来的版本之后引入了CMWQ,即一个CPU上允许运行多个工作线程。此外还引入了如下概念:
- worker_pool:可以理解为工作线程的池子、worker_pool和工作线程是一对多的关系;
- pwq(pool_workqueue):中间人/中介,负责建立起 workqueue 和 worker_pool 之间的关系。workqueue 和 pwq 是一对多的关系,pwq 和 worker_pool 是一对一的关系。
通常,在工作队列和软中断/tasklet中作出选择非常容易。可使用以下规则:
- 如果推后执行的任务需要睡眠,那么只能选择工作队列;
- 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时(内核定时器实现);
- 如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程,同时不可睡眠;
- 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务;
实际上,工作队列的本质就是将工作交给内核线程处理,由于内核线程的创建和销毁对编程者的要求较高,因此工作队列实现了内核线程的封装。
9.2 work
对于工作,linux内核使用struct work_struct 来描述,定义在include/linux/workqueue.h文件中:
struct work_struct { atomic_long_t data; struct list_head entry; // 链表结构,链接同一工作队列上的工作 work_func_t func; // 工作函数 #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map; #endif };
参数data比较特殊,
- bit[3:0]:flags,最后4位作为标志位使用;
- bit[7:4]:color,用于flush功能的,flush的功能是在销毁workqueue队列之前,等待workqueue队列上的任务都处理完成。
剩下的位在不同的场景下有不同的含义:
- 它可以指向work所在的workqueue队列的地址,由于低8位被挪作他用,因此要求workqueu队列的地址是按照256字节对齐的;
- 它还可以表示处理work的worker线程所在的pool的id。

9.3 worker_pool
当workqueue队列上有work待处理时,就会从worker pool中挑选一个空闲的worker线程来处理这个work。
对于工作线程池,linux内核使用struct worker_pool来描述,定义在kernel/workqueue.c文件中:
/* * Structure fields follow one of the following exclusion rules. * * I: Modifiable by initialization/destruction paths and read-only for * everyone else. * * P: Preemption protected. Disabling preemption is enough and should * only be modified and accessed from the local cpu. * * L: pool->lock protected. Access with pool->lock held. * * X: During normal operation, modification requires pool->lock and should * be done only from local cpu. Either disabling preemption on local * cpu or grabbing pool->lock is enough for read access. If * POOL_DISASSOCIATED is set, it's identical to L. * * A: wq_pool_attach_mutex protected. * * PL: wq_pool_mutex protected. * * PR: wq_pool_mutex protected for writes. RCU protected for reads. * * PW: wq_pool_mutex and wq->mutex protected for writes. Either for reads. * * PWR: wq_pool_mutex and wq->mutex protected for writes. Either or * RCU for reads. * * WQ: wq->mutex protected. * * WR: wq->mutex protected for writes. RCU protected for reads. * * MD: wq_mayday_lock protected. */ /* struct worker is defined in workqueue_internal.h */ struct worker_pool { spinlock_t lock; /* the pool lock */ int cpu; /* I: the associated cpu */ int node; /* I: the associated node ID */ int id; /* I: pool ID */ unsigned int flags; /* X: flags */ unsigned long watchdog_ts; /* L: watchdog timestamp */ struct list_head worklist; /* L: list of pending works */ int nr_workers; /* L: total number of workers */ int nr_idle; /* L: currently idle workers */ struct list_head idle_list; /* X: list of idle workers */ struct timer_list idle_timer; /* L: worker idle timeout */ struct timer_list mayday_timer; /* L: SOS timer for workers */ /* a workers is either on busy_hash or idle_list, or the manager */ DECLARE_HASHTABLE(busy_hash, BUSY_WORKER_HASH_ORDER); /* L: hash of busy workers */ struct worker *manager; /* L: purely informational */ struct list_head workers; /* A: attached workers */ struct completion *detach_completion; /* all workers detached */ struct ida worker_ida; /* worker IDs for task name */ struct workqueue_attrs *attrs; /* I: worker attributes */ struct hlist_node hash_node; /* PL: unbound_pool_hash node */ int refcnt; /* PL: refcnt for unbound pools */ /* * The current concurrency level. As it's likely to be accessed * from other CPUs during try_to_wake_up(), put it in a separate * cacheline. */ atomic_t nr_running ____cacheline_aligned_in_smp; /* * Destruction of pool is RCU protected to allow dereferences * from get_work_pool(). */ struct rcu_head rcu; } ____cacheline_aligned_in_smp;
其中
- worklist存储当前worker_pool负责处理的工作列表;
- workers:存储当前worker_pool管理的worker;
注意:一个worker对应一个内核线程,如果你了解线程池的话,那么worker_pool实际上可以类比做线程池,就是用来对线程创建、释放进行管理,而work相当于线程执行的任务。
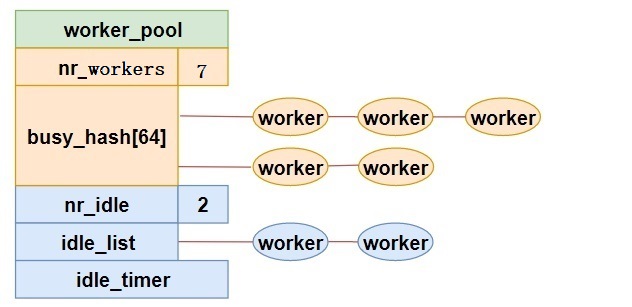
如果一个worker线程正在处理work,那么它就是busy的状态,将挂载在busy workers组成的6阶的hash表上。既然是hash表,那么就需要key,充当这个key的是正在被处理的work的内存地址。
如果一个worker没有处理work,那么它就是idle的状态,将挂载在idle workers组成的链表上。
如果现在一个CPU上的所有worker线程都进入了睡眠状态,但workqueue队列上还有未处理的work,内核就会启动一个新的worker线程,以提高效率。
有创建就有消亡,当现在空闲的worker线程过多的时候,就需要销毁一部分worker线程,以节省CPU资源。
这里实际上采用的就是一种类似负载均衡的策略,我们也不具体研究了。
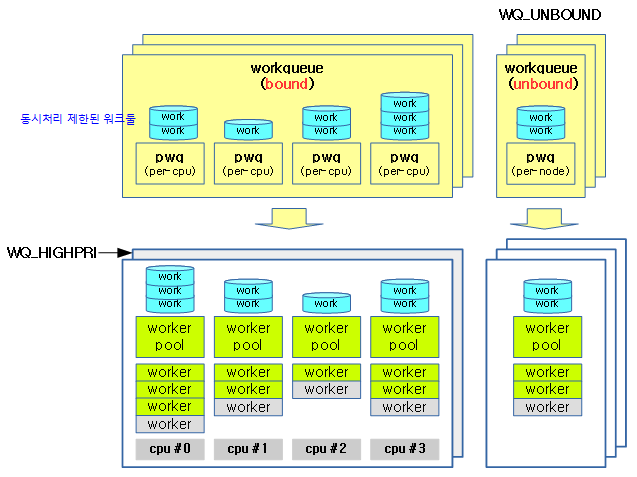
wmwq对worker_pool分成两类:
- normal worker_pool,给通用的 workqueue 使用;
- unbound worker_pool,给WQ_UNBOUND 类型的的workqueue使用;
在多个worker线程的cmwq模式下,系统的规则是一个CPU对应两个normal worker_pool,一个 normal 优先级 (nice=0)、一个高优先级 (nice=HIGHPRI_NICE_LEVEL),即一个CPU上同一优先级的所有worker线程共同构成了一个worker_pool,
9.4 worker
对于工作线程,linux内核使用struct worker来描述,定义在kernel/workqueue_internal.h文件中:
/* * The poor guys doing the actual heavy lifting. All on-duty workers are * either serving the manager role, on idle list or on busy hash. For * details on the locking annotation (L, I, X...), refer to workqueue.c. * * Only to be used in workqueue and async. */ struct worker { /* on idle list while idle, on busy hash table while busy */ union { struct list_head entry; /* L: while idle */ struct hlist_node hentry; /* L: while busy */ }; struct work_struct *current_work; /* L: work being processed */ work_func_t current_func; /* L: current_work's fn */ struct pool_workqueue *current_pwq; /* L: current_work's pwq */ struct list_head scheduled; /* L: scheduled works */ /* 64 bytes boundary on 64bit, 32 on 32bit */ struct task_struct *task; /* I: worker task */ struct worker_pool *pool; /* A: the associated pool */ /* L: for rescuers */ struct list_head node; /* A: anchored at pool->workers */ /* A: runs through worker->node */ unsigned long last_active; /* L: last active timestamp */ unsigned int flags; /* X: flags */ int id; /* I: worker id */ int sleeping; /* None */ /* * Opaque string set with work_set_desc(). Printed out with task * dump for debugging - WARN, BUG, panic or sysrq. */ char desc[WORKER_DESC_LEN]; /* used only by rescuers to point to the target workqueue */ struct workqueue_struct *rescue_wq; /* I: the workqueue to rescue */ /* used by the scheduler to determine a worker's last known identity */ work_func_t last_func; };
其中:
- pool是这个worker线程所在的worker pool,根据worker线程所处的状态,它要么在idle worker组成的空闲链表中,要么在busy worker组成的hash表中;
- current_work和current_func分别是worker线程正在处理的work和其对应的入口函数;
- 既然worker线程是一个内核线程,那么不管它是idle,还是busy的,都会对应一个task_struct,由task表示;
- current_pwq指向被worker所在的pool_workqueue;

9.5 workqueue
workqueue可以分为两类:一类系统创建的 workqueue,一类是用户自己创建的 workqueue。不论是系统还是用户的 workqueue,如果没有指定 WQ_UNBOUND,默认都是和 normal worker_pool 绑定。
系统在初始化时创建了一批默认的 workqueue:system_wq、system_highpri_wq、system_long_wq、system_unbound_wq、system_freezable_wq、system_power_efficient_wq、system_freezable_power_efficient_wq。像 system_wq,就是 schedule_work() 默认使用的。
linux内核使用struct workqueue_struct来描述workqueue,定义在kernel/workqueue.c文件中:
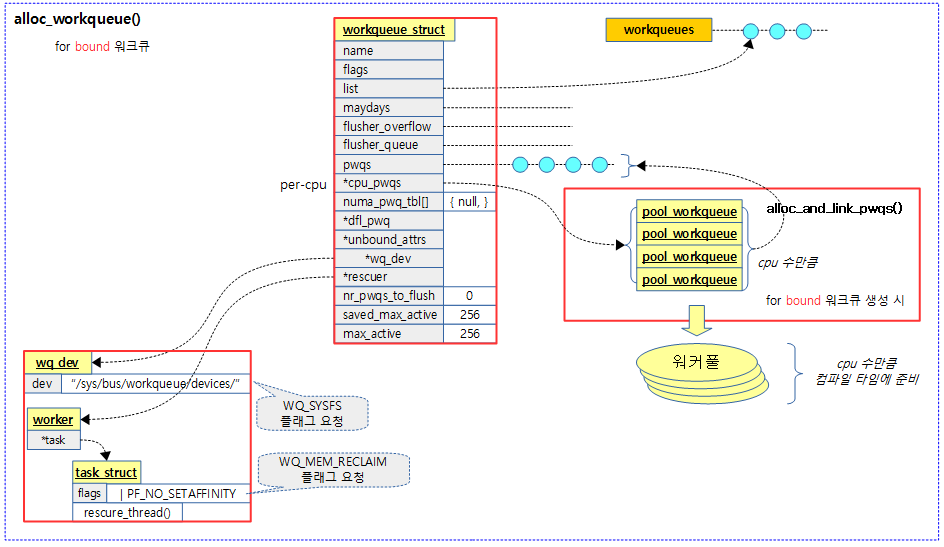
/* * The externally visible workqueue. It relays the issued work items to * the appropriate worker_pool through its pool_workqueues. */ struct workqueue_struct { struct list_head pwqs; /* WR: all pwqs of this wq */ struct list_head list; /* PR: list of all workqueues */ struct mutex mutex; /* protects this wq */ int work_color; /* WQ: current work color */ int flush_color; /* WQ: current flush color */ atomic_t nr_pwqs_to_flush; /* flush in progress */ struct wq_flusher *first_flusher; /* WQ: first flusher */ struct list_head flusher_queue; /* WQ: flush waiters */ struct list_head flusher_overflow; /* WQ: flush overflow list */ struct list_head maydays; /* MD: pwqs requesting rescue */ struct worker *rescuer; /* I: rescue worker */ int nr_drainers; /* WQ: drain in progress */ int saved_max_active; /* WQ: saved pwq max_active */ struct workqueue_attrs *unbound_attrs; /* PW: only for unbound wqs */ struct pool_workqueue *dfl_pwq; /* PW: only for unbound wqs */ #ifdef CONFIG_SYSFS struct wq_device *wq_dev; /* I: for sysfs interface */ #endif #ifdef CONFIG_LOCKDEP char *lock_name; struct lock_class_key key; struct lockdep_map lockdep_map; #endif char name[WQ_NAME_LEN]; /* I: workqueue name */ /* * Destruction of workqueue_struct is RCU protected to allow walking * the workqueues list without grabbing wq_pool_mutex. * This is used to dump all workqueues from sysrq. */ struct rcu_head rcu; /* hot fields used during command issue, aligned to cacheline */ unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */ struct pool_workqueue __percpu *cpu_pwqs; /* I: per-cpu pwqs */ struct pool_workqueue __rcu *numa_pwq_tbl[]; /* PWR: unbound pwqs indexed by node */ };
其中:
- list是有workqueue队列自身连接而成的链表,方便内核管理;
- pwqs:是由同种类型的pwq组成的链表;
- name:工作队列的名称;
- flags:工作队列标志位;比如WQ_UNBOUND、WQ_FREEZABLE、WQ_MEM_RECLAIM、WQ_HIGH_PRI、WQ_CPU_INTENSIVE、WQ_SYSFS、WQ_POWER_EFFICIENT、__WQ_DRAINING、__WQ_ORDERED、__WQ_LEGACY、__WQ_ORDERED_EXPLICIT;
下图为workqueue相关的结构图:
root@zhengyang:/work/sambashare/linux-5.2.8# ps -ef | grep worker root 4 2 0 5月16 ? 00:00:00 [kworker/0:0H] root 18 2 0 5月16 ? 00:00:00 [kworker/1:0H] root 24 2 0 5月16 ? 00:00:00 [kworker/2:0H] root 30 2 0 5月16 ? 00:00:00 [kworker/3:0H] root 281 2 0 5月16 ? 00:00:00 [kworker/3:1H] root 282 2 0 5月16 ? 00:00:02 [kworker/2:1H] root 284 2 0 5月16 ? 00:00:00 [kworker/0:1H] root 347 2 0 5月16 ? 00:00:01 [kworker/1:1H] root 34718 2 0 5月20 ? 00:00:00 [kworker/u257:0] root 48873 2 0 05:32 ? 00:00:00 [kworker/2:2] root 54309 2 0 09:54 ? 00:00:00 [kworker/1:2] root 59699 2 0 14:07 ? 00:00:01 [kworker/0:0] root 61060 2 0 15:25 ? 00:00:04 [kworker/3:2] root 63112 2 0 17:24 ? 00:00:00 [kworker/u256:0] root 63447 2 0 17:43 ? 00:00:00 [kworker/0:2] root 63489 2 0 17:45 ? 00:00:00 [kworker/1:1] root 63490 2 0 17:45 ? 00:00:00 [kworker/u256:2] root 63512 2 0 17:47 ? 00:00:00 [kworker/3:0] root 63521 2 0 17:47 ? 00:00:00 [kworker/2:1] root 63568 2 0 17:50 ? 00:00:00 [kworker/0:1] root 63620 2 0 17:53 ? 00:00:00 [kworker/u256:1] root 127524 2 0 5月19 ? 00:00:00 [kworker/u257:2]
worker线程被命名成了"kworker/n:x"的格式,其中n是worker线程所在的CPU的编号,x是其在worker pool中的编号,如果带了H后缀,说明这是高优先级的worker pool。
还有一些带u前缀的,它表示unbound,意思是这个worker线程不和任何的CPU绑定,而是被所有CPU共享,这种设计主要是为了增加灵活性。u后面的这个数字也不再表示CPU的编号,而是表示由这些unbound的worker线程组成的worker pool的id。
9.6 pool_workqueue
pool_workqueue定义在kernel/workqueue.c文件中:
/* * The per-pool workqueue. While queued, the lower WORK_STRUCT_FLAG_BITS * of work_struct->data are used for flags and the remaining high bits * point to the pwq; thus, pwqs need to be aligned at two's power of the * number of flag bits. */ struct pool_workqueue { struct worker_pool *pool; /* I: the associated pool */ struct workqueue_struct *wq; /* I: the owning workqueue */ int work_color; /* L: current color */ int flush_color; /* L: flushing color */ int refcnt; /* L: reference count */ int nr_in_flight[WORK_NR_COLORS]; /* L: nr of in_flight works */ int nr_active; /* L: nr of active works */ int max_active; /* L: max active works */ struct list_head delayed_works; /* L: delayed works */ struct list_head pwqs_node; /* WR: node on wq->pwqs */ struct list_head mayday_node; /* MD: node on wq->maydays */ /* * Release of unbound pwq is punted to system_wq. See put_pwq() * and pwq_unbound_release_workfn() for details. pool_workqueue * itself is also RCU protected so that the first pwq can be * determined without grabbing wq->mutex. */ struct work_struct unbound_release_work; struct rcu_head rcu; } __aligned(1 << WORK_STRUCT_FLAG_BITS);
其中:
- max_active和nr_active分别是该workqueue队列最大允许和实际挂载的work的数目。最大允许的work数目也就决定了该workqueue队列所对应的work pool上最多可能的活跃(busy)的worker线程的数目;
- pool指向与这个pool_workqueue连接的work_pool;
- wq指向与这个pool_workqueue连接的workqueue_struct;
9.7 工作队列拓扑结构
经过上面的分析,我们可以得到工作队列拓扑结构图如下:

9.8 工作创建
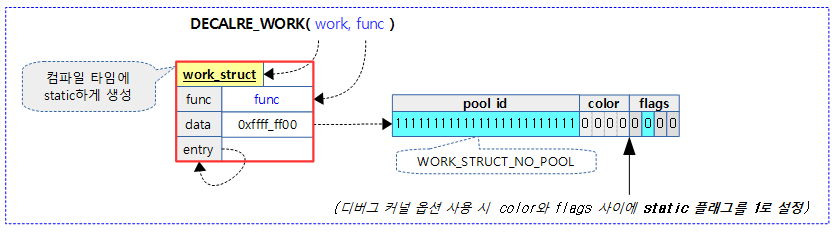
静态创建:
#define __WORK_INITIALIZER(n, f) { \ .data = WORK_DATA_STATIC_INIT(), \ .entry = { &(n).entry, &(n).entry }, \ .func = (f), \ __WORK_INIT_LOCKDEP_MAP(#n, &(n)) \ } #define DECLARE_WORK(n, f) \ struct work_struct n = __WORK_INITIALIZER(n, f)
执行后结果如下:
动态创建:
#define __INIT_WORK(_work, _func, _onstack) \ do { \ __init_work((_work), _onstack); \ (_work)->data = (atomic_long_t) WORK_DATA_INIT(); \ INIT_LIST_HEAD(&(_work)->entry); \ (_work)->func = (_func); \ } while (0) #define INIT_WORK(_work, _func) \ __INIT_WORK((_work), (_func), 0)
执行后结果如下:
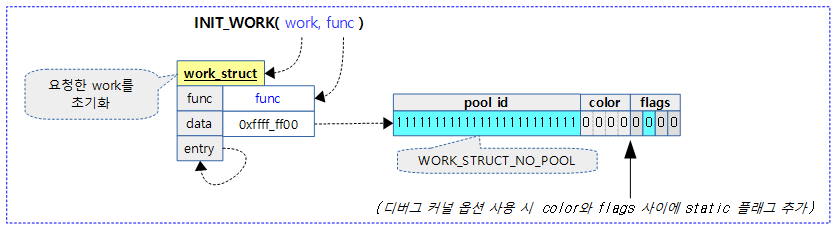
9.9 创建工作队列
要使用工作队列,首先创建一个队列,linux内核使用create_workqueue宏创建工作队列:
#define create_workqueue(name) \ alloc_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, 1, (name))
返回值为工作队列,name为工作队列名称。
alloc_workqueue定义在kernel/workqueue.c文件中:
struct workqueue_struct *alloc_workqueue(const char *fmt, unsigned int flags, int max_active, ...) { size_t tbl_size = 0; va_list args; struct workqueue_struct *wq; struct pool_workqueue *pwq; /* * Unbound && max_active == 1 used to imply ordered, which is no * longer the case on NUMA machines due to per-node pools. While * alloc_ordered_workqueue() is the right way to create an ordered * workqueue, keep the previous behavior to avoid subtle breakages * on NUMA. */ if ((flags & WQ_UNBOUND) && max_active == 1) flags |= __WQ_ORDERED; /* see the comment above the definition of WQ_POWER_EFFICIENT */ if ((flags & WQ_POWER_EFFICIENT) && wq_power_efficient) flags |= WQ_UNBOUND; /* allocate wq and format name */ if (flags & WQ_UNBOUND) tbl_size = nr_node_ids * sizeof(wq->numa_pwq_tbl[0]); wq = kzalloc(sizeof(*wq) + tbl_size, GFP_KERNEL); // 动态分配workqueue_struct内存 if (!wq) return NULL; if (flags & WQ_UNBOUND) { wq->unbound_attrs = alloc_workqueue_attrs(GFP_KERNEL); if (!wq->unbound_attrs) goto err_free_wq; } va_start(args, max_active); vsnprintf(wq->name, sizeof(wq->name), fmt, args); va_end(args); max_active = max_active ?: WQ_DFL_ACTIVE; max_active = wq_clamp_max_active(max_active, flags, wq->name); /* init wq */ wq->flags = flags; wq->saved_max_active = max_active; mutex_init(&wq->mutex); atomic_set(&wq->nr_pwqs_to_flush, 0); INIT_LIST_HEAD(&wq->pwqs); INIT_LIST_HEAD(&wq->flusher_queue); INIT_LIST_HEAD(&wq->flusher_overflow); INIT_LIST_HEAD(&wq->maydays); wq_init_lockdep(wq); INIT_LIST_HEAD(&wq->list); if (alloc_and_link_pwqs(wq) < 0) goto err_unreg_lockdep; if (wq_online && init_rescuer(wq) < 0) goto err_destroy; if ((wq->flags & WQ_SYSFS) && workqueue_sysfs_register(wq)) goto err_destroy; /* * wq_pool_mutex protects global freeze state and workqueues list. * Grab it, adjust max_active and add the new @wq to workqueues * list. */ mutex_lock(&wq_pool_mutex); mutex_lock(&wq->mutex); for_each_pwq(pwq, wq) pwq_adjust_max_active(pwq); mutex_unlock(&wq->mutex); list_add_tail_rcu(&wq->list, &workqueues); // 将工作队列添加到全局工作队列列表中 mutex_unlock(&wq_pool_mutex); return wq; err_unreg_lockdep: wq_unregister_lockdep(wq); wq_free_lockdep(wq); err_free_wq: free_workqueue_attrs(wq->unbound_attrs); kfree(wq); return NULL; err_destroy: destroy_workqueue(wq); return NULL; }
执行后结果如下:
9.10 添加任务
工作队列创建成功后工作就有了栖身之所,以后只要往工作队列里添加工作就可以异步执行了。
queue_work函数向工作队列中添加任务,queue_work定义在include/linux/workqueue.h:
/** * queue_work - queue work on a workqueue * @wq: workqueue to use * @work: work to queue * * Returns %false if @work was already on a queue, %true otherwise. * * We queue the work to the CPU on which it was submitted, but if the CPU dies * it can be processed by another CPU. */ static inline bool queue_work(struct workqueue_struct *wq, struct work_struct *work) { return queue_work_on(WORK_CPU_UNBOUND, wq, work); }
queue_work_on定义在kernel/workqueue.c:
/** * queue_work_on - queue work on specific cpu * @cpu: CPU number to execute work on * @wq: workqueue to use * @work: work to queue * * We queue the work to a specific CPU, the caller must ensure it * can't go away. * * Return: %false if @work was already on a queue, %true otherwise. */ bool queue_work_on(int cpu, struct workqueue_struct *wq, struct work_struct *work) { bool ret = false; unsigned long flags; local_irq_save(flags); if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) { __queue_work(cpu, wq, work); ret = true; } local_irq_restore(flags); return ret; }
__queue_work定义在kernel/workqueue.c:
static void __queue_work(int cpu, struct workqueue_struct *wq, struct work_struct *work) { struct pool_workqueue *pwq; struct worker_pool *last_pool; struct list_head *worklist; unsigned int work_flags; unsigned int req_cpu = cpu; /* * While a work item is PENDING && off queue, a task trying to * steal the PENDING will busy-loop waiting for it to either get * queued or lose PENDING. Grabbing PENDING and queueing should * happen with IRQ disabled. */ lockdep_assert_irqs_disabled(); debug_work_activate(work); /* if draining, only works from the same workqueue are allowed */ if (unlikely(wq->flags & __WQ_DRAINING) && WARN_ON_ONCE(!is_chained_work(wq))) return; rcu_read_lock(); retry: if (req_cpu == WORK_CPU_UNBOUND) cpu = wq_select_unbound_cpu(raw_smp_processor_id()); /* pwq which will be used unless @work is executing elsewhere */ if (!(wq->flags & WQ_UNBOUND)) pwq = per_cpu_ptr(wq->cpu_pwqs, cpu); else pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu)); /* * If @work was previously on a different pool, it might still be * running there, in which case the work needs to be queued on that * pool to guarantee non-reentrancy. */ last_pool = get_work_pool(work); if (last_pool && last_pool != pwq->pool) { struct worker *worker; spin_lock(&last_pool->lock); worker = find_worker_executing_work(last_pool, work); if (worker && worker->current_pwq->wq == wq) { pwq = worker->current_pwq; } else { /* meh... not running there, queue here */ spin_unlock(&last_pool->lock); spin_lock(&pwq->pool->lock); } } else { spin_lock(&pwq->pool->lock); } /* * pwq is determined and locked. For unbound pools, we could have * raced with pwq release and it could already be dead. If its * refcnt is zero, repeat pwq selection. Note that pwqs never die * without another pwq replacing it in the numa_pwq_tbl or while * work items are executing on it, so the retrying is guaranteed to * make forward-progress. */ if (unlikely(!pwq->refcnt)) { if (wq->flags & WQ_UNBOUND) { spin_unlock(&pwq->pool->lock); cpu_relax(); goto retry; } /* oops */ WARN_ONCE(true, "workqueue: per-cpu pwq for %s on cpu%d has 0 refcnt", wq->name, cpu); } /* pwq determined, queue */ trace_workqueue_queue_work(req_cpu, pwq, work); if (WARN_ON(!list_empty(&work->entry))) goto out; pwq->nr_in_flight[pwq->work_color]++; work_flags = work_color_to_flags(pwq->work_color); if (likely(pwq->nr_active < pwq->max_active)) { trace_workqueue_activate_work(work); pwq->nr_active++; worklist = &pwq->pool->worklist; if (list_empty(worklist)) pwq->pool->watchdog_ts = jiffies; } else { work_flags |= WORK_STRUCT_DELAYED; worklist = &pwq->delayed_works; } insert_work(pwq, work, worklist, work_flags); out: spin_unlock(&pwq->pool->lock); rcu_read_unlock(); }
9.11 总结
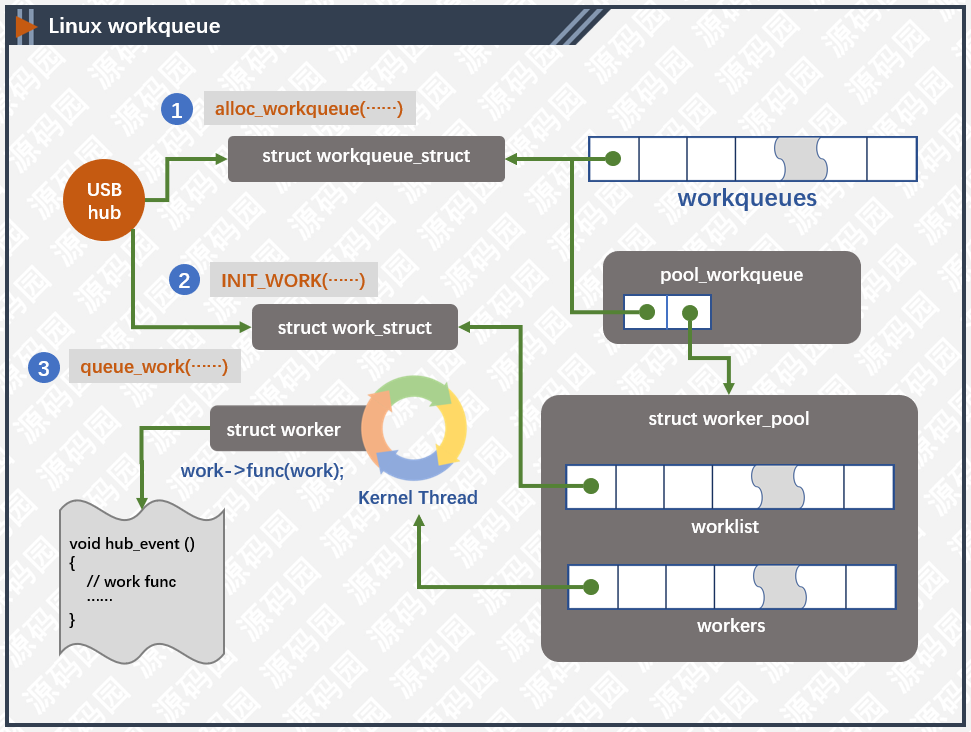
实际上,linux的usb子系统就利用了工作队列的原理来实现usb设备的热插拔,有兴趣得我可以阅读这篇博客Linux工作队列workqueue源码分析:
参考文章
[1]Linux中断(interrupt)子系统之五:软件中断(softIRQ)
[2]Linux的中断处理机制 [四] - softirq(1)
[3]Linux的中断处理机制 [五] - softirq(2)
[4]Linux中的中断处理机制 [六] - 从tasklet到中断线程化
[6]linux kernel的中断子系统之(八):softirq
[7]Softirq, Tasklets and Workqueues
[8]详解Linux中断处理中的hardirq与softirq机制
[9]Linux内核中的软中断、tasklet和工作队列详解
[10]Linux系统中的知名内核线程(1)——ksoftirqd和events
[12]任务工厂 - Linux中的workqueue机制 [一]
[13]任务工厂 - Linux中的workqueue机制 [二]