安装前准备
1. 一台或多台主机,这里准备三台机器
|
角色 |
IP |
Hostname |
配置(最低) |
操作系统版本 |
|
主节点 |
192.168.0.10 |
master |
2核2G |
CentOS7.6.1810 |
|
工作节点 |
192.168.0.11 |
node1 |
2核2G |
CentOS7.6.1810 |
|
工作节点 |
192.168.0.12 |
node2 |
2核2G |
CentOS7.6.1810 |
2. 验证MAC地址和product_uuid对于每个节点都是唯一的
- 您可以使用命令
ip link或ifconfig -a获取网络接口的MAC地址 - 可以使用
sudo cat /sys/class/dmi/id/product_uuid 查看product_uuid
3. 检查所需端口
- 主节点

- 子节点

4. 所有节点同步时间
yum install ntpdate -y ntpdate 0.asia.pool.ntp.org
5. 修改主机名,分别在三个节点下执行
hostnamectl set-hostname master hostnamectl set-hostname node1 hostnamectl set-hostname node2
6. 在三个节点下修改hosts文件
192.168.0.10 master 192.168.0.11 node1 192.168.0.12 node2
7. 关闭所有节点的防火墙及SELinux
systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
8. CentOS7需要确保确保 net.bridge.bridge-nf-call-iptables在sysctl配置中设置为1,在所有节点执行
cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 vm.swappiness=0 EOF sysctl --system
9. 关闭SWAP
swapoff -a
注释掉/etc/fstab中的swap挂载那一行
安装Docker CE
在所有节点下执行
yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo yum install docker-ce -y systemctl start docker systemctl enable docker
安装kubeadm,kubelet和kubectl
- kubeadm:引导群集的命令。
- kubelet:在群集中的所有计算机上运行的组件,并执行诸如启动pod和容器之类的操作。
- kubectl:用于与群集通信的命令行util。
1. 编辑版本库
在每个节点执行
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2. 安装,并设置kubelet开机自启动
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes systemctl enable kubelet && systemctl start kubelet
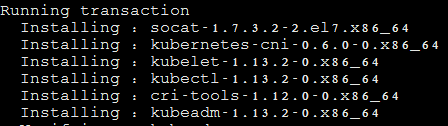
从安装结果可以看出还安装了cri-tools, kubernetes-cni, socat三个依赖:
官方从Kubernetes 1.9开始就将cni依赖升级到了0.6.0版本,在当前1.12中仍然是这个版本
socat是kubelet的依赖
cri-tools是CRI(Container Runtime Interface)容器运行时接口的命令行工具
创建集群
1. 初始化
在主节点下运行
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.0.10
参数解释注解:
为了flannel网络正常工作,你必须通过--pod-network-cidr=10.244.0.0/16
kubeadm使用与默认网关关联的网络接口来通告主IP,使用其他网络接口,请加上--apiserver-advertise-address=<ip-address>
初始化报错,镜像拉取错误,这是由于国内的防火墙测原因
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.13.0: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-controller-manager:v1.13.0: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-scheduler:v1.13.0: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-proxy:v1.13.0: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/pause:3.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/etcd:3.2.24: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [ERROR ImagePull]: failed to pull image k8s.gcr.io/coredns:1.2.6: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
解决方法如下,这些镜像也应该下载到工作节点
# 从dockerhub下载需要的镜像 docker pull mirrorgooglecontainers/kube-apiserver:v1.13.2 docker pull mirrorgooglecontainers/kube-controller-manager:v1.13.2 docker pull mirrorgooglecontainers/kube-scheduler:v1.13.2 docker pull mirrorgooglecontainers/kube-proxy:v1.13.2 docker pull mirrorgooglecontainers/pause:3.1 docker pull mirrorgooglecontainers/etcd:3.2.24 docker pull coredns/coredns:1.2.6 # 修改dockerhub镜像tag为k8s.gcr.io docker tag docker.io/mirrorgooglecontainers/kube-apiserver:v1.13.2 k8s.gcr.io/kube-apiserver:v1.13.2 docker tag docker.io/mirrorgooglecontainers/kube-controller-manager:v1.13.2 k8s.gcr.io/kube-controller-manager:v1.13.2 docker tag docker.io/mirrorgooglecontainers/kube-scheduler:v1.13.2 k8s.gcr.io/kube-scheduler:v1.13.2 docker tag docker.io/mirrorgooglecontainers/kube-proxy:v1.13.2 k8s.gcr.io/kube-proxy:v1.13.2 docker tag docker.io/mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1 docker tag docker.io/mirrorgooglecontainers/etcd:3.2.24 k8s.gcr.io/etcd:3.2.24 docker tag docker.io/coredns/coredns:1.2.6 k8s.gcr.io/coredns:1.2.6 # 删除多余镜像 docker rmi mirrorgooglecontainers/kube-apiserver:v1.13.2 docker rmi mirrorgooglecontainers/kube-controller-manager:v1.13.2 docker rmi mirrorgooglecontainers/kube-scheduler:v1.13.2 docker rmi mirrorgooglecontainers/kube-proxy:v1.13.2 docker rmi mirrorgooglecontainers/pause:3.1 docker rmi mirrorgooglecontainers/etcd:3.2.24 docker rmi coredns/coredns:1.2.6
再次执行初始化,成功,日志如下,记录了完成的初始化输出的内容,根据输出的内容基本上可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤。
[root@master ~]# kubeadm init
> --kubernetes-version=v1.13.0
> --pod-network-cidr=10.244.0.0/16
> --apiserver-advertise-address=192.168.0.10
[init] Using Kubernetes version: v1.13.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.09.1. Latest validated version: 18.06
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.0.10]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [master localhost] and IPs [192.168.0.10 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [master localhost] and IPs [192.168.0.10 127.0.0.1 ::1]
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 30.506947 seconds
[uploadconfig] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.13" in namespace kube-system with the configuration for the kubelets in the cluster
[patchnode] Uploading the CRI Socket information "/var/run/dockershim.sock" to the Node API object "master" as an annotation
[mark-control-plane] Marking the node master as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: k9bohf.6zl3ovmlkf4iwudg
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstraptoken] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 192.168.0.10:6443 --token k9bohf.6zl3ovmlkf4iwudg --discovery-token-ca-cert-hash sha256:e73fe78ac9a961582a0ad81e3bffbebfa1d81b37b2f0cd7aacbfa6c1a1de351c
要使kubectl为非root用户工作,请运行以下命令,这些命令也是kubeadm init输出的一部分
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
或者,如果您是root用户,则可以运行:
export KUBECONFIG=/etc/kubernetes/admin.conf
2. 安装pod网络附加组件
这里选择flannel作为Pod的网络,在管理节点下执行
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.extensions/kube-flannel-ds-amd64 created daemonset.extensions/kube-flannel-ds-arm64 created daemonset.extensions/kube-flannel-ds-arm created daemonset.extensions/kube-flannel-ds-ppc64le created daemonset.extensions/kube-flannel-ds-s390x created
安装了pod网络后,您可以通过运行下面命令检查CoreDNS pod是否正常工作
[root@master ~]# kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-86c58d9df4-fvrfv 1/1 Running 0 17m kube-system coredns-86c58d9df4-lgsxd 1/1 Running 0 17m kube-system etcd-master 1/1 Running 0 16m kube-system kube-apiserver-master 1/1 Running 0 16m kube-system kube-controller-manager-master 1/1 Running 0 16m kube-system kube-flannel-ds-amd64-h56rl 1/1 Running 0 92s kube-system kube-proxy-99hmp 1/1 Running 0 17m kube-system kube-scheduler-master 1/1 Running 0 16m
如果报错,下面的方法排错:
查看日志: /var/log/messages
kubectl --namespace kube-system logs kube-flannel-ds-amd64-wdqsl
3. 加入工作节点
在工作节点执行初始化时日志的输出。
kubeadm join 192.168.0.10:6443 --token qrduq2.24km2r56xg24o6yw --discovery-token-ca-cert-hash sha256:54c981ec4220202107b1ef89907d31af94840ed75a1e9f352f9288245760ac83
更新令牌
默认情况下令牌24小时过期,使用下面方法创建新的令牌
kubeadm token create kubeadm token list
4. 查看节点的状态
状态为Ready表示和Master节点正常通信
[root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready master 104m v1.13.2 node1 Ready <none> 34m v1.13.2 node2 Ready <none> 29m v1.13.2
5. 将主节点加入工作负载(可选操作)
默认情况下,出于安全原因,您的群集不会在主服务器上安排pod。如果您希望能够在主服务器上安排pod,例如,对于用于开发的单机Kubernetes集群,请运行:
[root@master ~]# kubectl describe node master | grep Taint Taints: node-role.kubernetes.io/master:NoSchedule [root@master ~]# kubectl taint nodes --all node-role.kubernetes.io/master- node/master untainted taint "node-role.kubernetes.io/master:" not found taint "node-role.kubernetes.io/master:" not found
6. 从主服务器以外的计算机控制您的群集(可选操作)
在工作节点上运行
scp root@<master ip>:/etc/kubernetes/admin.conf . kubectl --kubeconfig ./admin.conf get nodes
移除集群
在控制节点上运行
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets kubectl delete node <node name>
然后,在要删除的节点上,重置所有kubeadm安装状态:
kubeadm reset
重置过程不会重置或清除iptables规则或IPVS表。如果您想重置iptables,必须手动执行:
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
如果要重置IPVS表,则必须运行以下命令:
ipvsadm -C
参考文档:https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/