当参数一样多的时候,神经网络变得更高比变宽更有效果。为什么会这样呢?
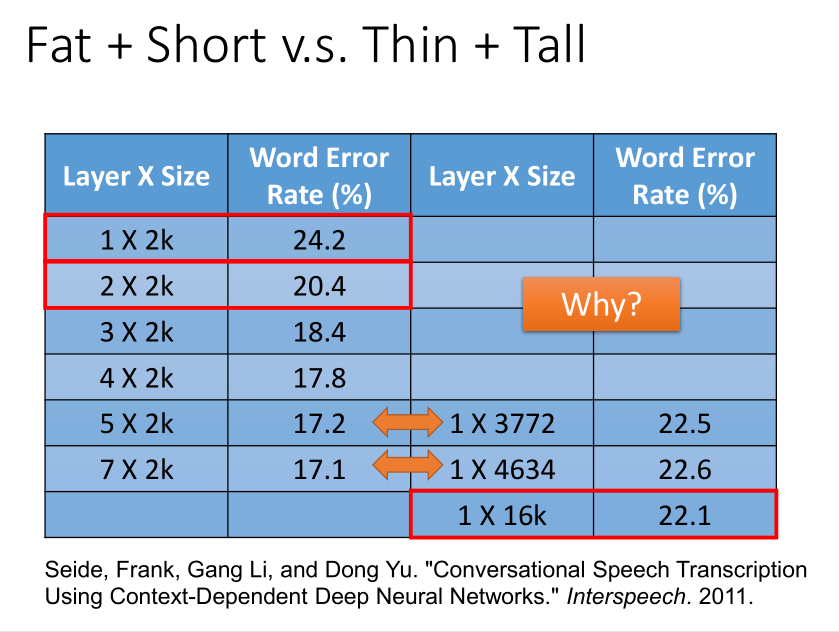
其实和软件行业的模块化思想是一致的。
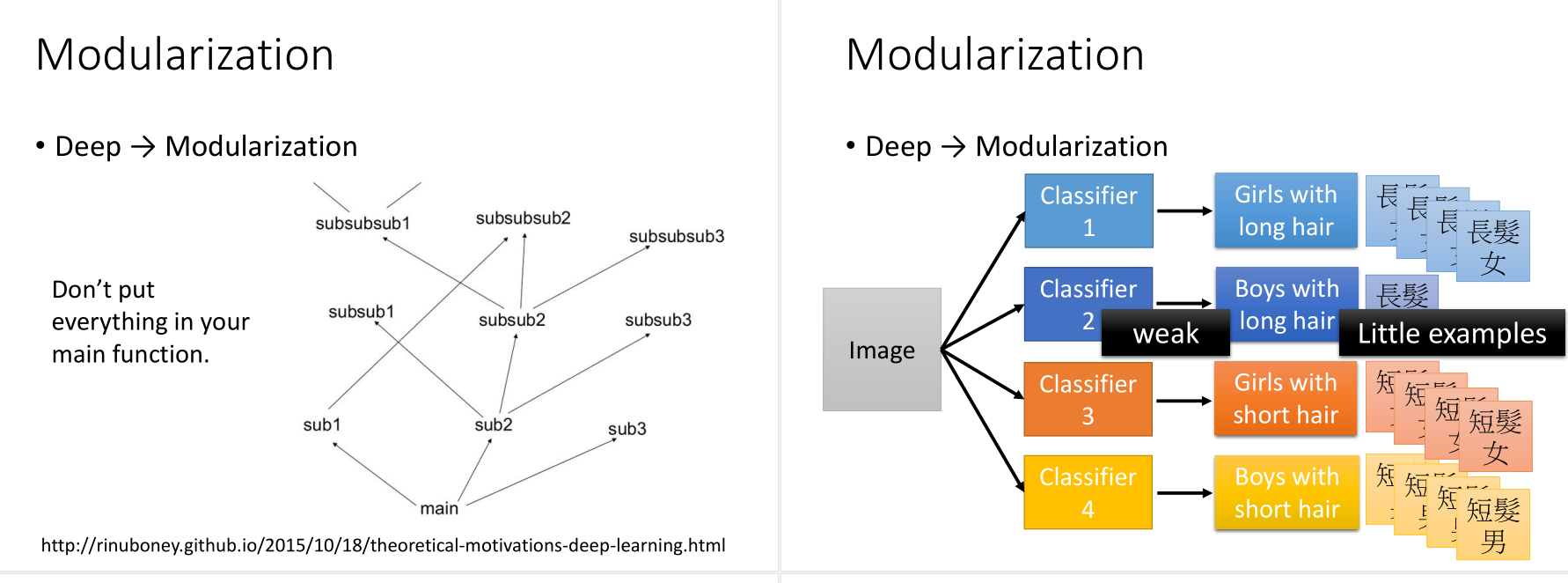
比如,如果直接对这四种分类进行训练,长发的男孩数据较少,那么这一类训练得到的classifier不是很好。
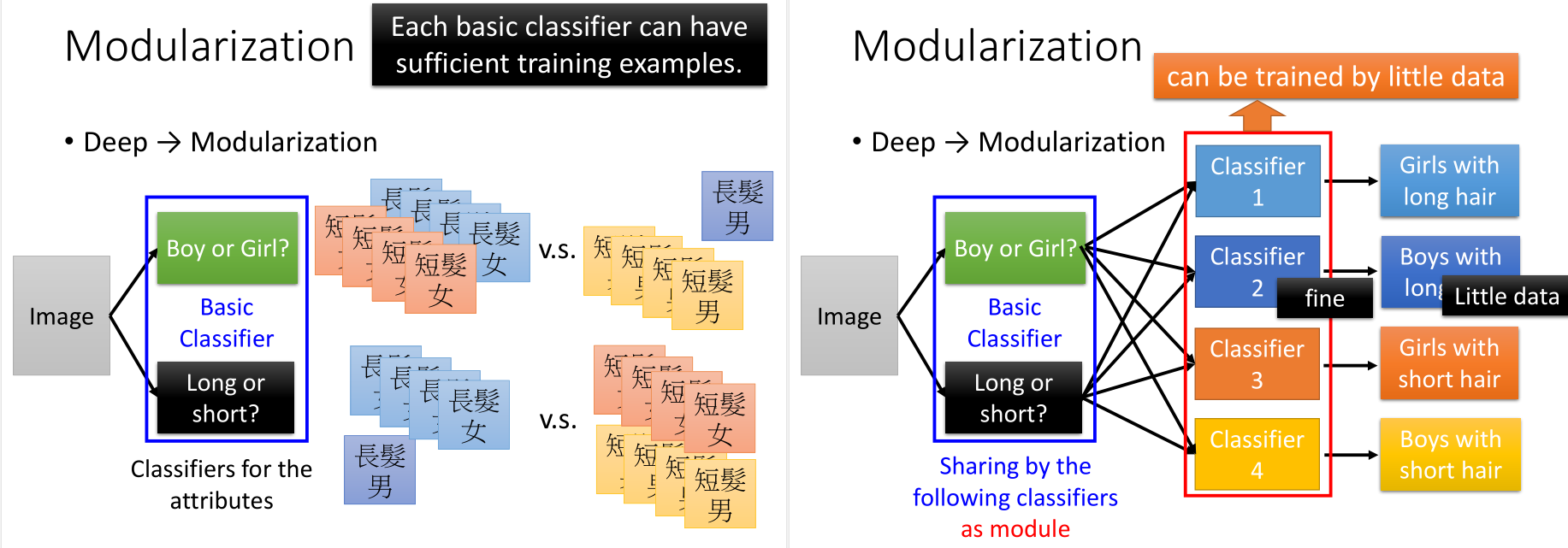
但如果分成长发or短发,男孩or女孩,这两种基分类器,那么数据就是足够的,可以得到很好的结果。这样的话,其实用比较少的数据就可以得到很好地分类结果。
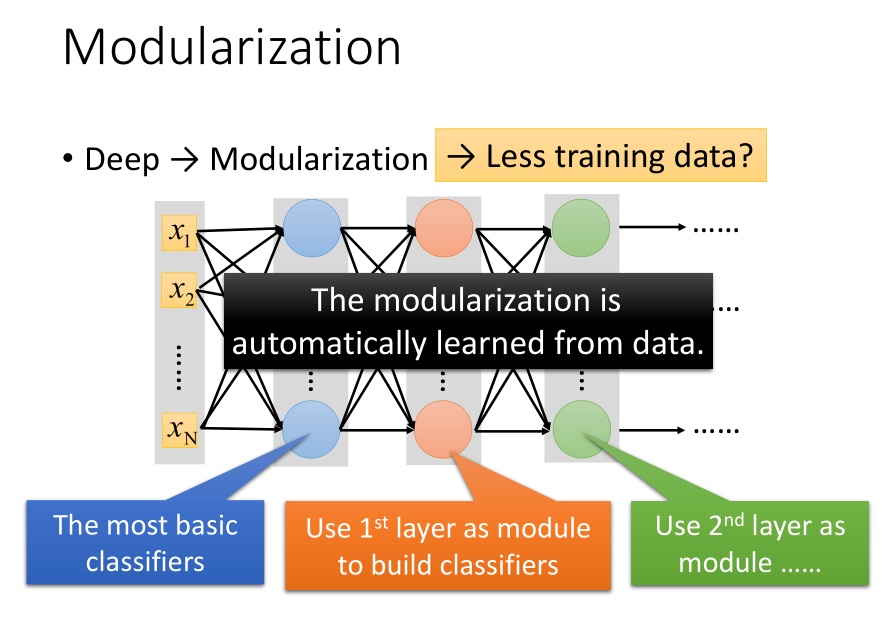
模组化这个事情机器是可以自动学到的。
图像应用

语音应用
第一步要做的事情就是把acoustic feature转成state,再把state转成phoneme,再转成文字。
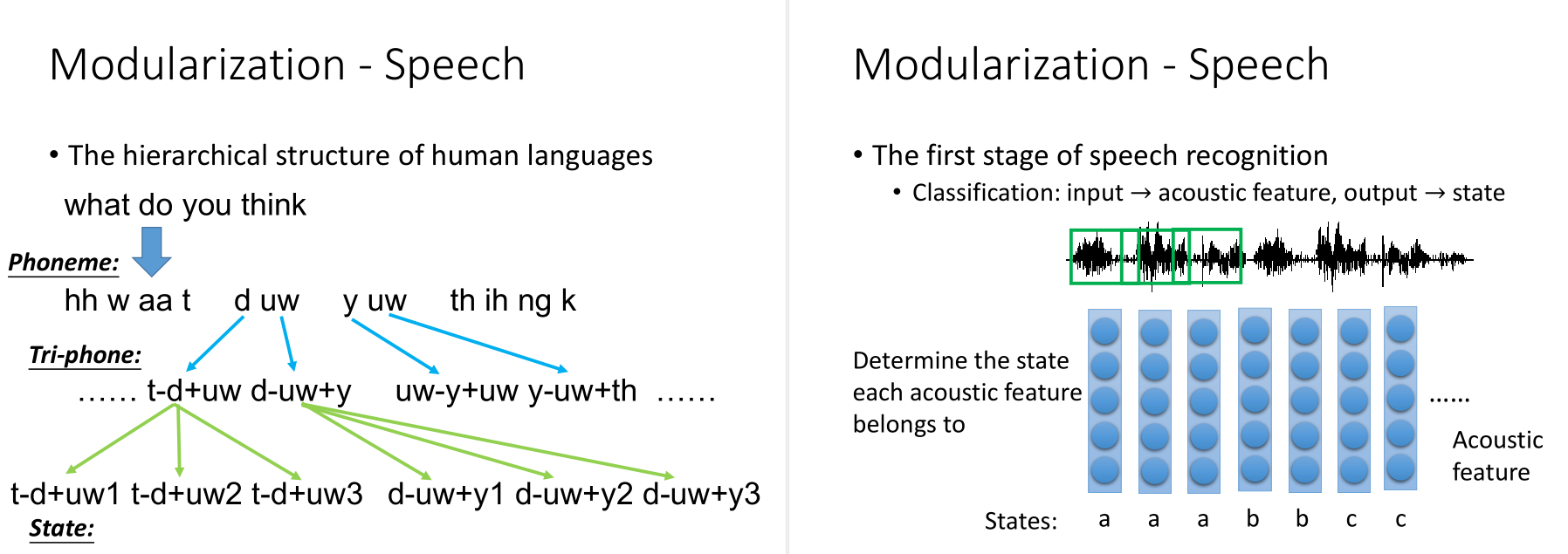
传统的HMM-GMM方法,给你一个feature,你就可以说每一个acoustic feature从每一个state产生出来的几率。
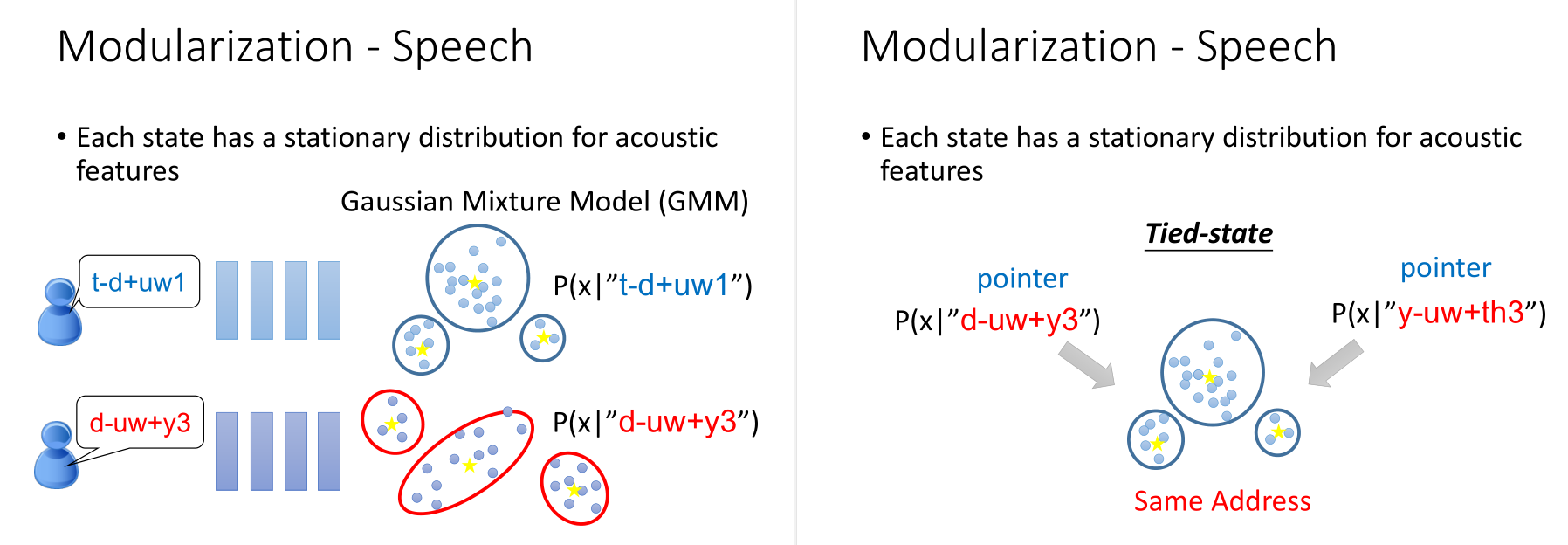
但是每一个state都要用Gaussian Mixture Model来描述,参数太多了。
有一些state,他们会共用同一个model distribution,这件事叫做Tied-state。是否共用,需要借助知识。
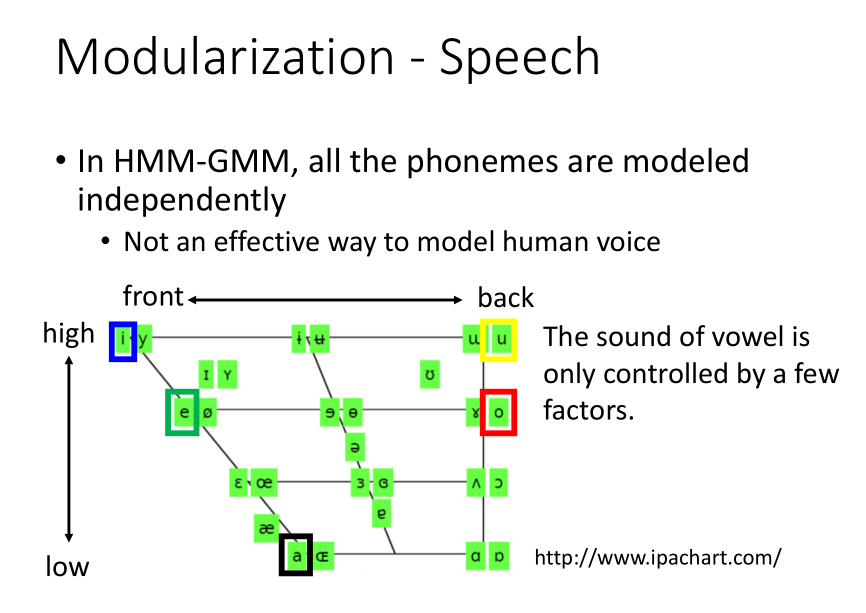
HMM-GMM的方式,所有的state是independently的,没有一个effective的方法来model人声。
不同的phoneme之间其实是有关系的,如果说每个phoneme都搞一个model,这件事是没有效率的。
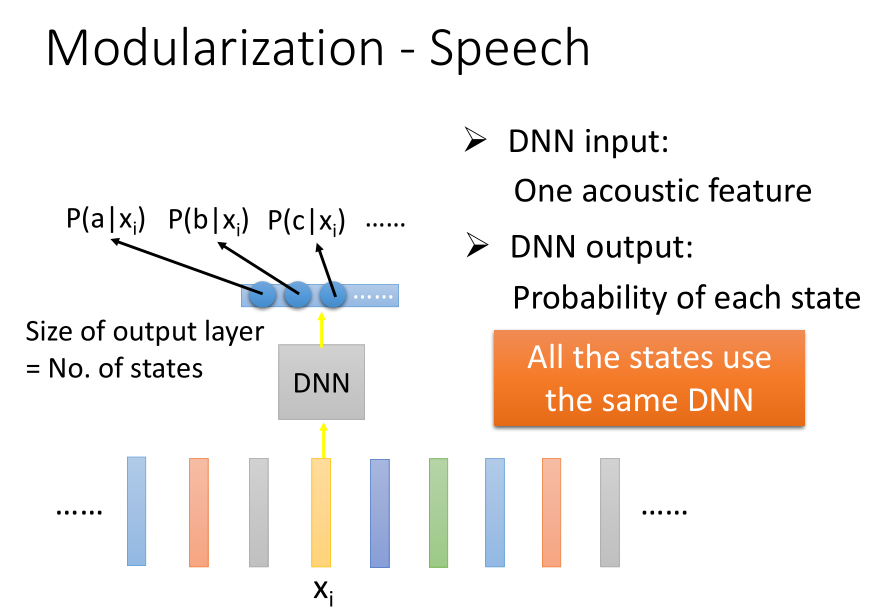
DNN的方法,input是一个acoustic feature,output是acoustic feature属于每个state的几率。
最关键的一点是所有的state都共用同一个DNN,并没有为每一个state产生一个DNN。
虽然DNN的参数很多,但并不是因为参数多所以比GMM好,因为GMM的每一个phoneme都有一个model,参数加起来可能比DNN还要多。
两种方法比较:
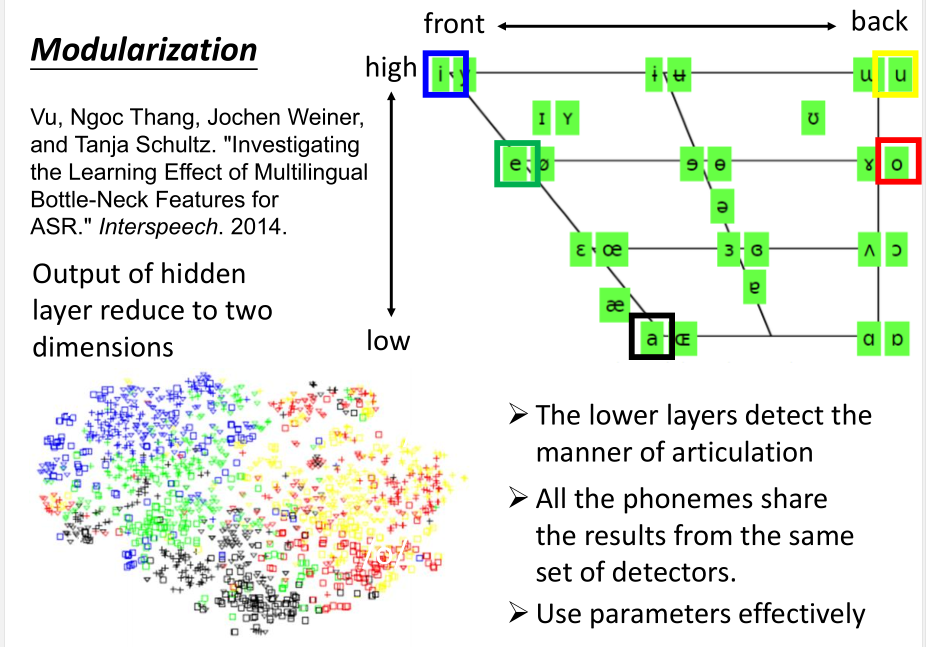
DNN做的事情在比较低层的时候,它并不是马上去侦测这个发音是属于哪个state。
它的做事是它先观察(detector)说,当你听到这个发音的时候,人是用什么方式在发这个声音的。(模组化)
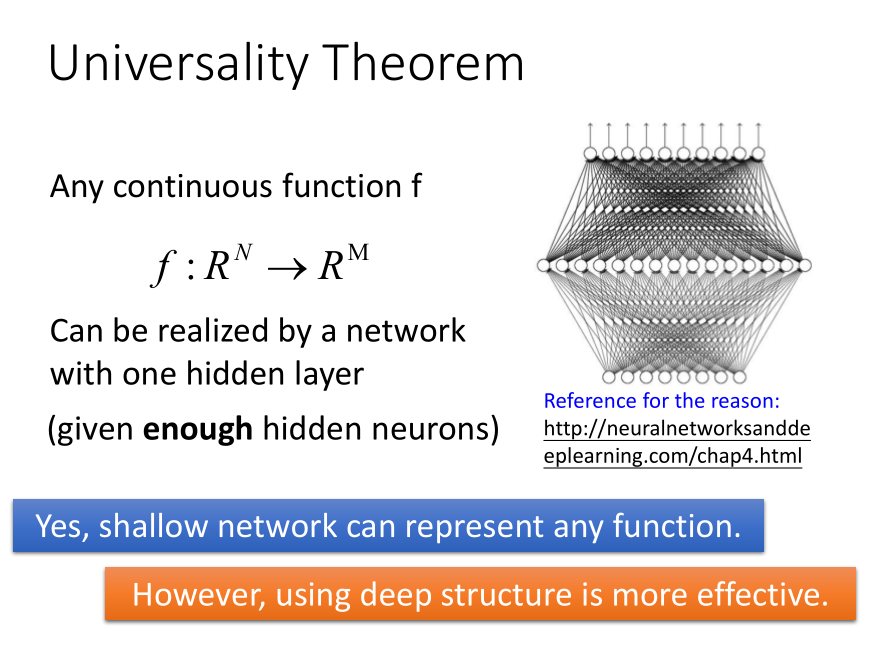
普遍性原理:
过去的理论说,任何的continuous function,都可以用一层来完成。但这种模型效率并不高。
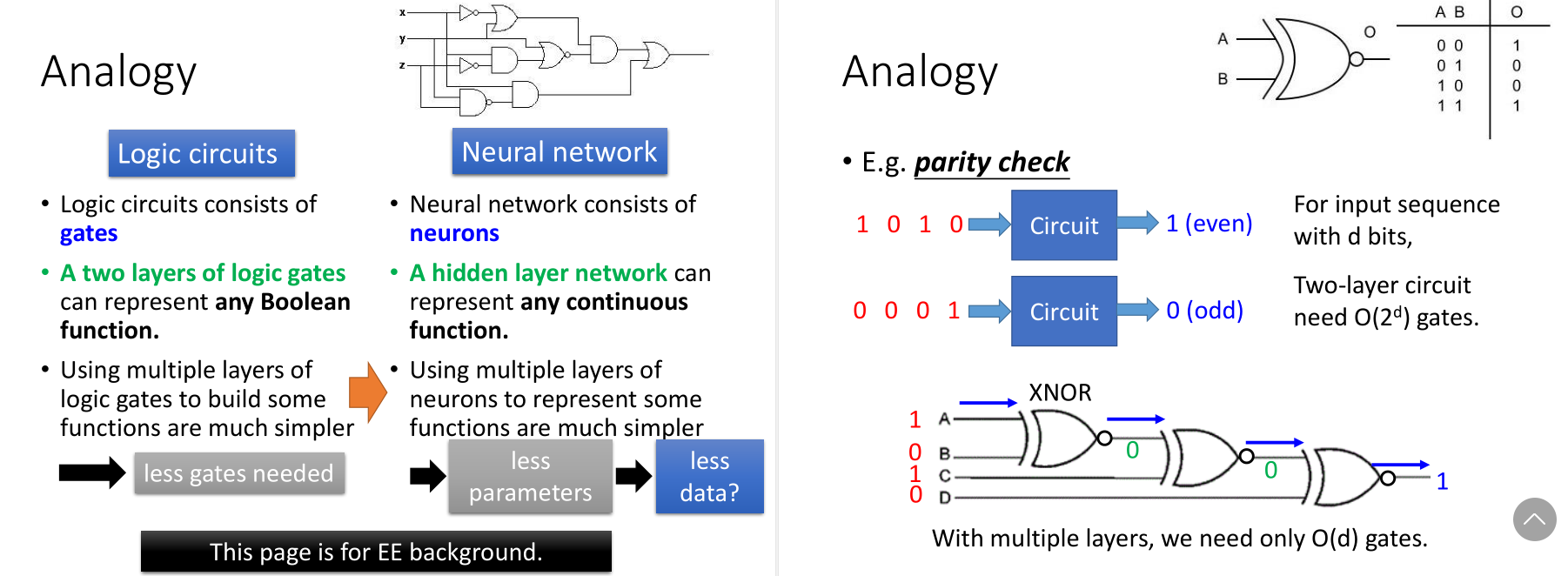
逻辑电路和逻辑闸的例子,后边做的是奇偶校验。
还有个形象的例子就是剪窗花,右图的features transformation和它是一个道理。
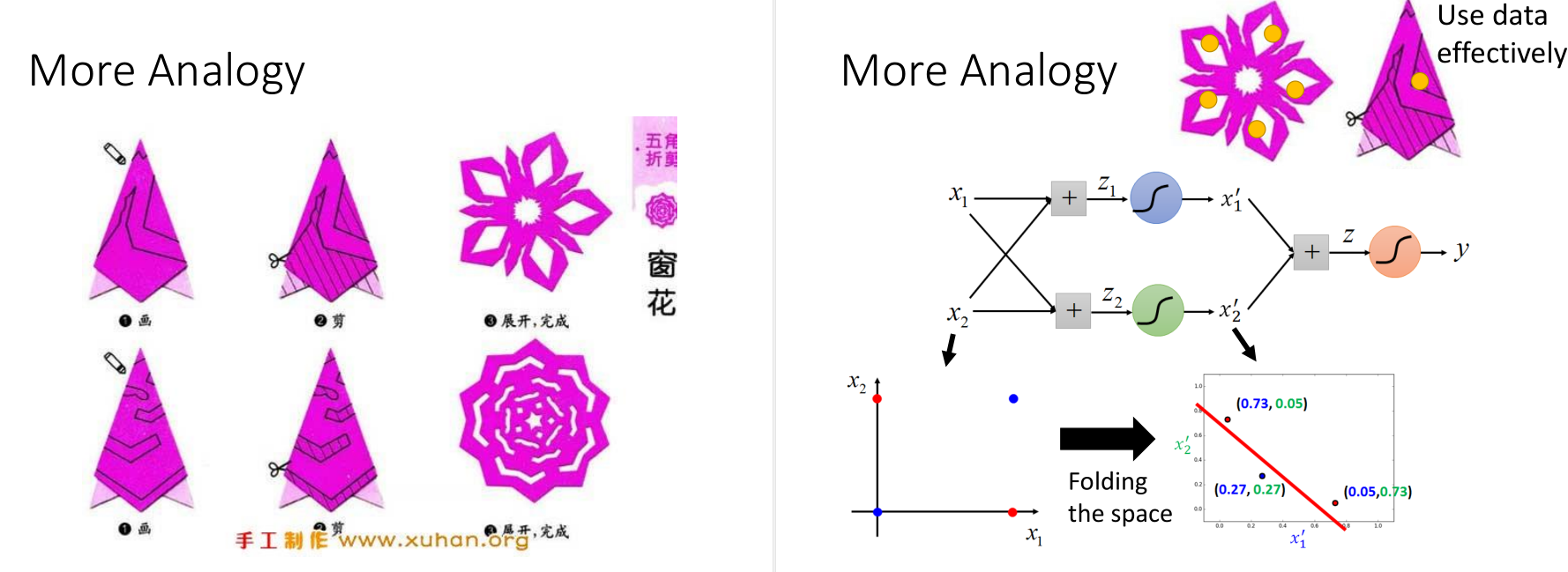
二维坐标的例子。

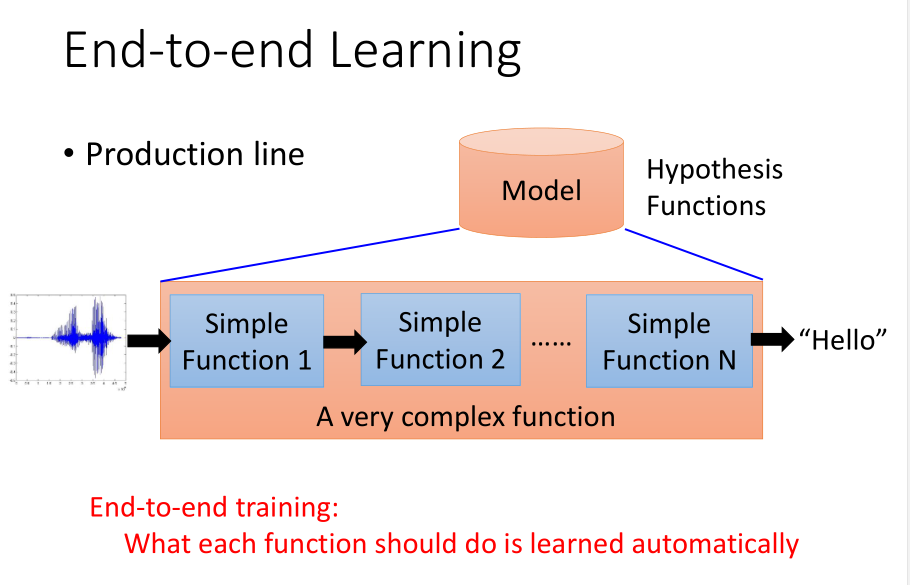
End to End Learning
深度学习的一个好处就是,我们可以做End-to-end learning。
就是说只要给model input和output,不用告诉它每层function要咋样分工,让它自己去学中间每一个function。
对于语音识别问题,DNN的方法得到的结果,和传统方法中最好的MFCC可以持平。
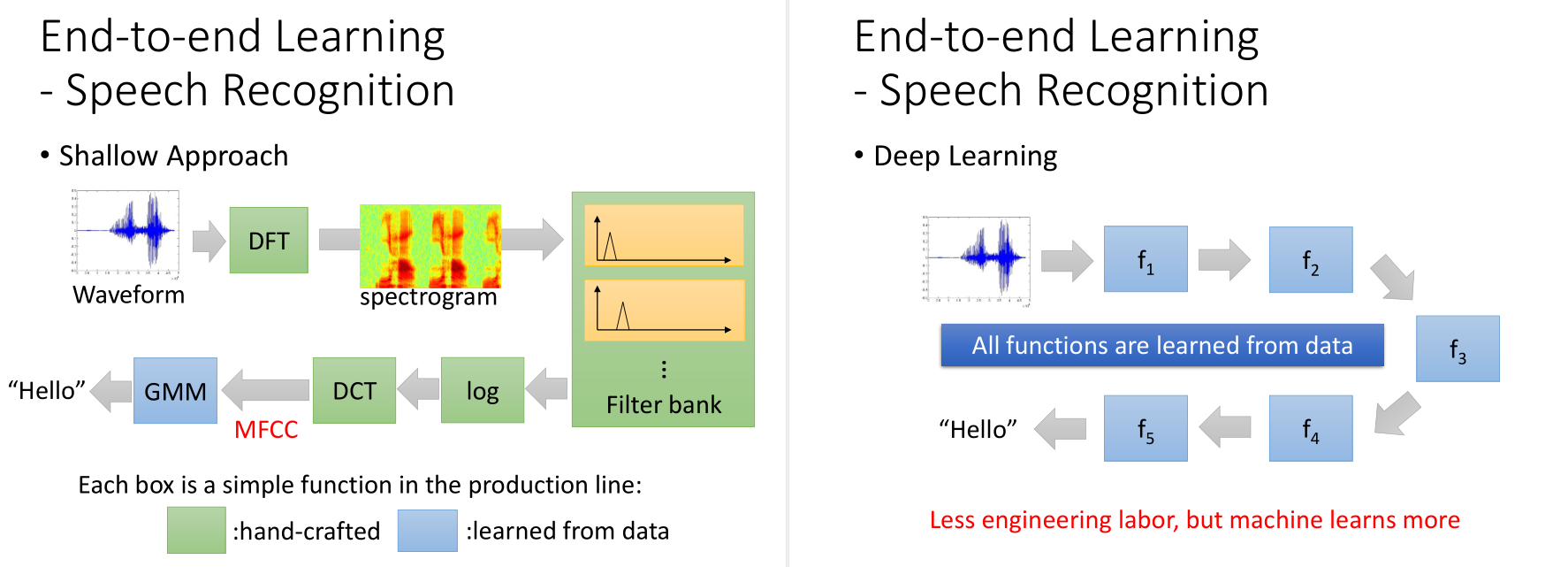
图像识别的问题也是一样。

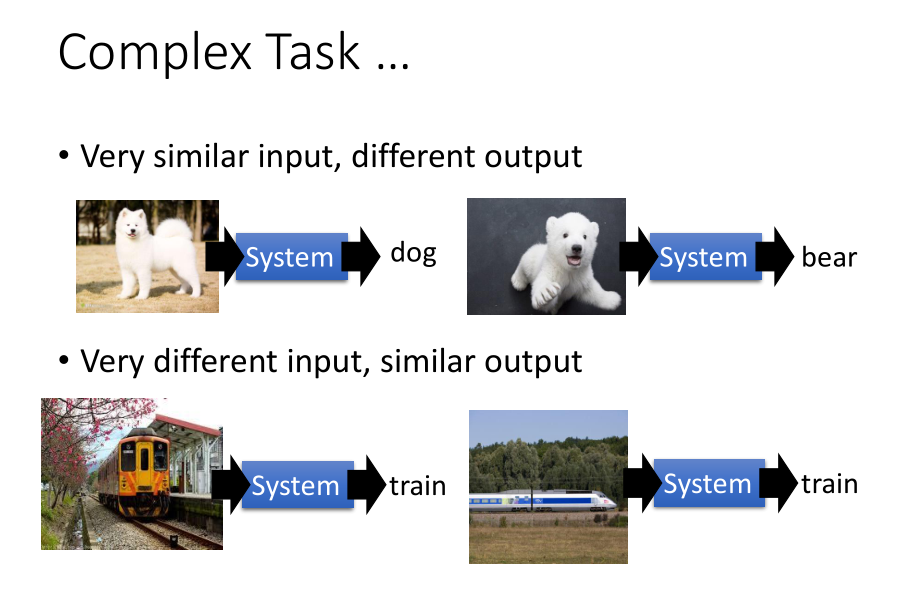
还有,对于复杂问题,一层是远远不够的。
对于语音识别来说,看起来每个人说的很不一样,但当到第八层时,不同的人说的同样的句子,它自动的被line在一起了。

对于手写数字识别,到了第三层时,就可以很好地分开了。
