作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
新世纪以来,越来越多的人会走出房间,迈向电影院。观看那一幕幕或惊心动魄,或温情的影片,那么电影对于我们来说存在的意义又是什么?有人说娱乐自我,放松心情;有人说要在影视的虚幻中得到安慰,以此来满足内心的梦魇;还有人回答我,要在别人的人生经历中汲取经验,获取能量……但电影似乎更像一面镜子,是我们人类历史发展的历程射影。无论悲喜,动作,言情,家庭,伦理,科幻,甚至综艺,他以任何形式所表达的任何内容,我们都能在现实生活中找到相应的情感寄托,又或者说,电影,本来就是生活!

人们会在网络上寻找那些已经在电影院下架的电影,那么,为人们提供好看而又有趣的电影已经有其存在的意义了!而豆瓣中为我们提供了无数的电影,人们既可以从上面寻找电影,也可在上面发表观看电影后的评价,供人们去理解和思考哪些电影是较好看和适合自己的。因此我们在豆瓣上面通过爬虫方式爬取了Top250条电影数据。这上面包括了电影名、图片链接、演员、印象、评分等信息。影片链接 :https://movie.douban.com/top250
除此之后还根据观众们的喜爱,分析一下各部电影的短评情况!了解该部电影吸引人的地方。
以下是豆瓣Top的网页结构:分析可知每一页都有25个电影数据,所有电影的数据都是由li标签组合而成的,而我们想获取的内容分别为a、img、p、span标签等组成。

按电影名与评分排列为:
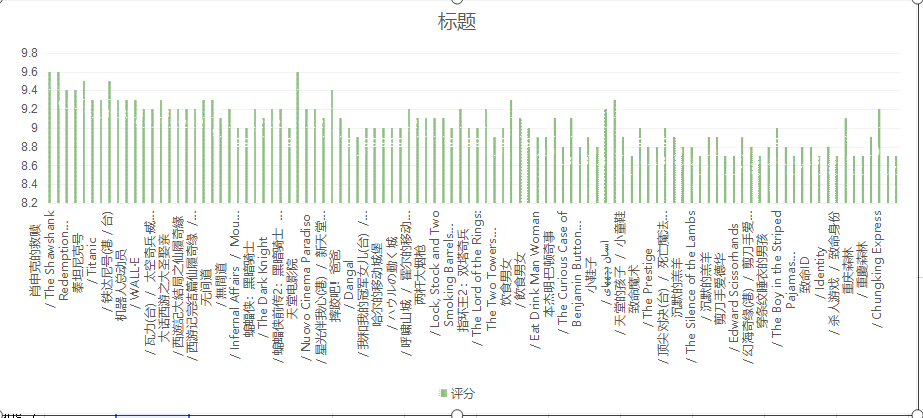
我们一生中观看的电影数不胜数,但是又有多少部电影能够直戳心灵呢?好的电影能够打动人,也能够影响人的一生。其中肖申克的救赎、霸王别姬、控方证人的评分均为9.6分。是大部分人心目当中的好电影!因此,那些怀旧和想看好电影的人可以去看这三部。


肖申克的救赎 霸王别姬
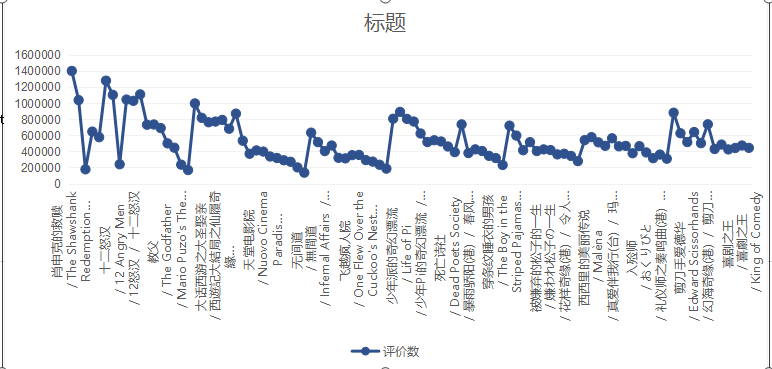
根据评价人数可知,肖申克的救赎和这个杀手不太冷这两部电影的人数最多,表明了他们更加容易影响人们的共鸣和吐槽的点最多。倘若你想寻找这方面的电影可以去看这两部电影。
urls=['https://movie.douban.com/top250?start={}&filter='.format(str(i)) for i in range(0,100,25)]
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36',
'Cookie':'bid="+RZMojI+I84"; ll="118281"; viewed="7056708_10863574_26647176_3288908"; gr_user_id=7758d24b-1ff7-4bfb-aac5-da0cebb3b129; _ga=GA1.2.1164329915.1430920272; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1457141967%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DwlFfuGH8nDDaDfhuElvs2e-927672lPlTf3UP5ra2LVTDrCK1YcFpyYiIAPJcOqq%26wd%3D%26eqid%3D86da232a00235c820000000356da38c0%22%5D; ps=y; ue="alovera@sina.com"; dbcl2="61719891:SKQE4SmJJ7U"; ck="WzE9"; ap=1; push_noty_num=0; push_doumail_num=0; __utma=30149280.1164329915.1430920272.1457093782.1457141968.44; __utmb=30149280.6.10.1457141968; __utmc=30149280; __utmz=30149280.1457141968.44.23.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmv=30149280.6171; __utma=223695111.1164329915.1430920272.1457093782.1457141968.6; __utmb=223695111.0.10.1457141968; __utmc=223695111; __utmz=223695111.1457141968.6.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_id.100001.4cf6=051573cd37c5bc0e.1446452093.6.1457142204.1457093853.; _pk_ses.100001.4cf6=*'
}
title=[]
image=[]
actor=[]
empression=[]
rate=[]
evalu_num=[]
def allfilm(web_url,data=None):
web_data=requests.get(web_url)
soup=BeautifulSoup(web_data.text,'html.parser')
time.sleep(2)
titles=soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
images=soup.select('#content > div > div.article > ol > li > div > div.pic > a > img')
actors=soup.select('#content > div > div.article > ol > li > div > div.info > div.bd > p:nth-of-type(1)')
empressions=soup.select('#content > div > div.article > ol > li > div > div.info > div.bd > p:nth-of-type(2)')
rates=soup.select('#content > div > div.article > ol > li > div > div.info > div.bd > div > span.rating_num')
evalu_nums=soup.select('#content > div > div.article > ol > li > div > div.info > div.bd > div > span:nth-of-type(4)')
for title1,image1,actor1,empression1,rate1,evalu_num1 in zip(titles,images,actors,empressions,rates,evalu_nums):
title.append(title1.get_text().replace('\xa0',' ').strip()),
image.append(image1.get('src')),
actor.append(actor1.get_text().replace('\xa0',' ').strip()),
empression.append(empression1.get_text()),
rate.append(rate1.get_text()),
evalu_num.append(evalu_num1.get_text())
for sigle_url in urls:
allfilm(sigle_url)
data={'电影名':title,
'图片链接':image,
'演员':actor,
'印象':empression,
'评分':rate,
'评价数':evalu_num}
frame=DataFrame(data,columns=[u'电影名',u'图片链接',u'演员',u'印象',u'评分',u'评价数'])
根据人们对这100部电影的印象并通过词云的方式显示出来可知,人们对改变、世界、故事、永远这些词语比较关注,电影制作人可以从这些角度分析为什么这些电影的评分比较高,从而创造出更优秀的电影!

主要代码如下:
sep = '.,:; ! 我们 不是 一个 自己 这样 电影 人生 最好 以为 那些' fo = open(r'C:UserszyDesktopzy.txt', 'r', encoding='utf-8') text = fo.read() fo.close text = text.lower() for ch in sep: text = text.replace(ch, ' ') print(text.split()) a = jieba.lcut(text) # print(a) wcdict = {} for word in a: if word not in wcdict: if len(word) == 1: continue else: wcdict[word] = wcdict.get(word, 0) + 1 wails = list(wcdict.items()) wails.sort(key=lambda x: x[1], reverse=True) cut_text = " ".join(a) 'print(cut_text)' mywc = WordCloud(font_path='msyh.ttc').generate(cut_text) plt.imshow(mywc) plt.axis("off") plt.show() for i in range(20): print(wails[i])
摘不到的星星,总是最闪亮的。 溜掉的小鱼,总是最美丽的。 错过的电影,总是最好看的。 这或许是大部分人的感受吧!为了能够寻找到那遗失的美好,我们就从那一部部“古老而又动情”的电影开始吧。
爬取完豆瓣电影排行之后,我们来分析下电影的短评。每个人的经历不同,看完的电影感受不同。
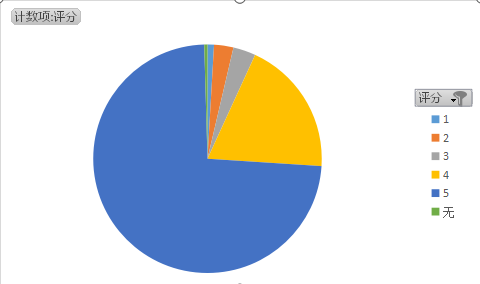
这里列出Top250电影中的第一名肖申克的救赎的影评,包括昵称、评分、日期、评论。

其中给5星好评的人是最多的,其次是4星好评的!这也与我们Top250排行第一所得到的结论是相同的!表明其实在是一部不可多得的好电影。
分析其短评所生成的词云,我们也可大概所其所想表达的主题!

主要代码如下:
def fillCommentsDatas(data, html): soup = BeautifulSoup(html, 'lxml') divs = soup.find_all('div', attrs={'class': 'comment-item'}) for div in divs: if isinstance(div, bs4.element.Tag): nickname = div.find('a', attrs={'title': True}).get('title') StarandDate = div.find_all('span', attrs={'title': True}) if len(StarandDate) == 2: star = float(re.findall('allstar(dd).*?', str(StarandDate[0]))[0]) / 10 date = StarandDate[1].get('title') else: star = "无" date = StarandDate[0].get('title') comment = div.find('span', attrs={'class': 'short'}).string.strip() data[nickname] = [date, star, comment]
def write_to_excel(data):
# 新建一个excel文件
workbook = xlwt.Workbook(encoding='ascii')
# 新建一个worksheet
worksheet = workbook.add_sheet('BookSheet')
# 设置表格的宽度
worksheet.col(0).width = 4000
worksheet.col(1).width = 3000
worksheet.col(2).width = 8000
worksheet.col(3).width = 30000
# 初始化样式
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = "宋体"
font.height = 11 * 20
# 新建alignment 样式设置
alignment = xlwt.Alignment()
# 设置行居中
alignment.horz = xlwt.Alignment.HORZ_CENTER
# 设置列居中
alignment.vert = xlwt.Alignment.VERT_CENTER
alignment.wrap = 1
style.font = font
style.alignment = alignment
worksheet.write(0, 0, "昵称", style)
worksheet.write(0, 1, "评分", style)
worksheet.write(0, 2, "日期", style)
worksheet.write(0, 3, "评论", style)
tmp = 1
for key, value in data.items():
worksheet.write(tmp, 0, key, style)
worksheet.write(tmp, 1, value[1], style)
worksheet.write(tmp, 2, value[0], style)
worksheet.write(tmp, 3, value[2], style)
tmp += 1
workbook.save('影评.xls')
结论:通过本次项目,使我对自己有了更加清晰的认识。对python等的知识点有了更加深刻的了解和认识!虽有进步,但仍有不足之处!望能够继续加油,争取自己有更大的进步!