解析es的分布式架构
分布式架构的透明隐藏特性
-
ElasticSearch是一个分布式系统,隐藏了复杂的处理机制
-
分片机制:我们不用关系数据是按照什么机制分片的、最后放入到哪个分片中
-
分片的副本:集群发现机制(cluster discovery):比如当前我们启动了一个es进程,当启动了第二个es进程时,这个进程作为一个node自动就发现了集群,并且加入了进去
-
shard负载均衡:比如现在有10shard,集群中有3个节点,es会进行均衡的进行分配,以保持每个节点均衡的负载请求
-
请求路由
-
扩容机制
-
垂直扩容:购置新的机器,替换已有的机器
-
水平扩容:新增机器
rebalance
-
增加或减少节点时会自动均衡
master节点
-
主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点,稳定的主节点对集群的健康是非常重要的
节点对等
-
每个节点都能接收请求,每个节点接收到请求后都能把该请求路由到有相关数据的其他节点上,接收原始请求的节点负责采集数据并返回给客户端
分片和副本机制
-
index包含多个shard
-
每个shard都是一个最小工作单元,承载部分数据;每个shard都是一个lucene实列,有完整的建立索引和处理请求的能力
-
增减节点时,shard会自动再nodes中负载均衡
-
primary shard和replica shard,每个document肯定只存在于某个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
容错机制
-
集群状态为red,是因为不是所有的primary shard都是活跃的
-
如果主节点挂了,会重新选举另外的几个节点作为master
-
master会把丢失的primary shard的其中一个副本提升为primary shard,此时所有的primary shard都是活跃的,所以集群状态转为yellow(并不是所有的副本都是活跃的)
-
把宕机的服务器重启,master会把每个primary shard上的数据拷贝一份到该服务器上,此时primary shard和replicashard都是活跃的,所以集群状态为green
文档的核心元数据
-
_index
-
说明文档存储在哪个索引中
-
同一个索引下存放的是相似的文档(文档的field多数是相同的)
-
索引名必须是小写的,不能以下划线开头,不能包括逗号
-
-
_type
-
表示文档属于索引的哪个类型
-
一个索引下建议由一个type
-
类型名可以是大写也可以是小写,不能以下划线开头,不能包括逗号
-
-
_id
-
文档的唯一标识,和索引,类型组合在一起唯一标识了一个文档
-
可以手动指定值,也可以由es来生成这个值
-
文档id生成方式
-
手动指定
put /index/type/66
通常是把其它系统的已有数据导入到es时
-
由es生成id值
post /index/type
es生成的id长度为20个字符,使用的是base64编码,URL安全,使用的是GUID算法,分布式下并发生成id值时不会冲突
_source元数据分析
-
其实就是我们在添加文档时request_body中的内容
-
指定返回的结果中含有哪些字段:
get /index/type/2?_source=name
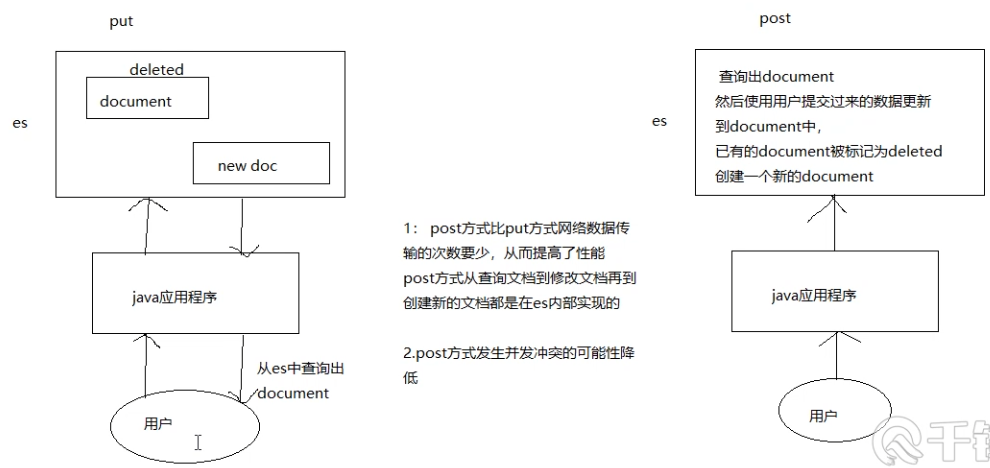
-
post方式获取文档数据和版本信息进行更新
# 跟新失败尝试3次
POST /lib/user/4/_update?retry_on_conflict=3?version=5
文档数据路由原理解析
-
文档路由到分片上:一个索引由多个分片构成,当添加(删除、修改)一个文档时,es就需要决定这个文档存储在哪个分片上,这个过程就称为数据路由(routing)
-
路由算法:
shard=hash(routing)%number_of_primary_shards // routing默认时文档的id值,也可以手动设置一个值, -
primary shard个数一旦确定就不能修改了
文档增删改内部原理
-
发送增删该请求时,可以选择任意一个节点,该节点就成了协调节点(coordinating node)
-
协调节点使用路由算法进行路由,然后将请求转到primary shard所在节点,该节点处理请求,并把数据同步到它的replica shard
-
协调节点对客户端做出响应