-
认识Hadoop
概述
开源、分布式存储、分布式计算
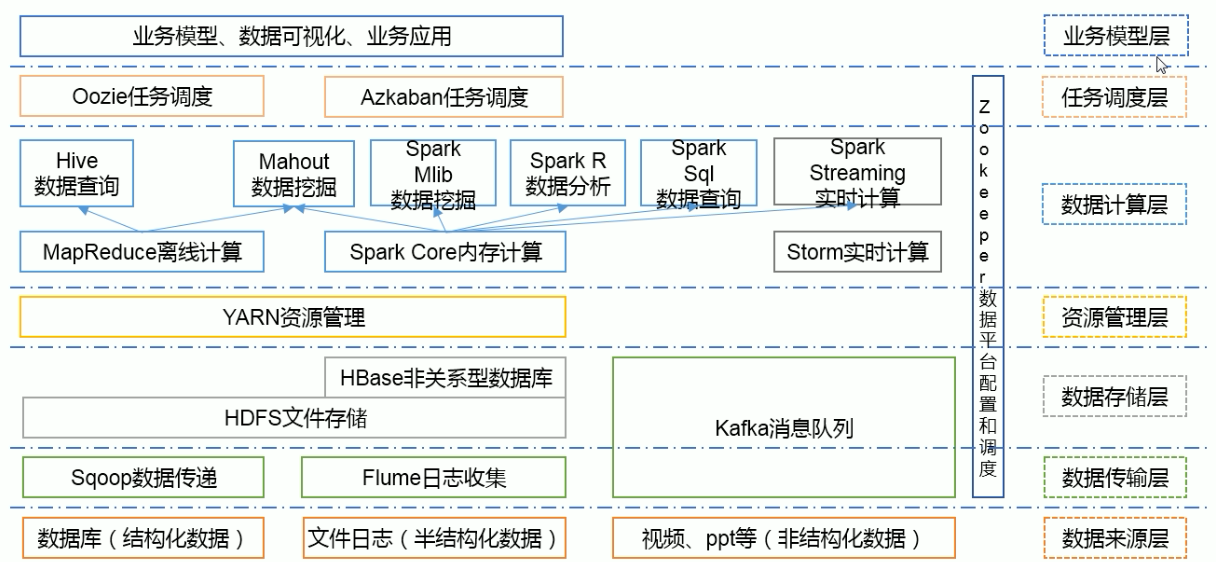
大数据生态体系
- 特点:开源、社区活跃
- 囊括了大数据处理的方方面面
- 成熟的生态圈
推荐系统
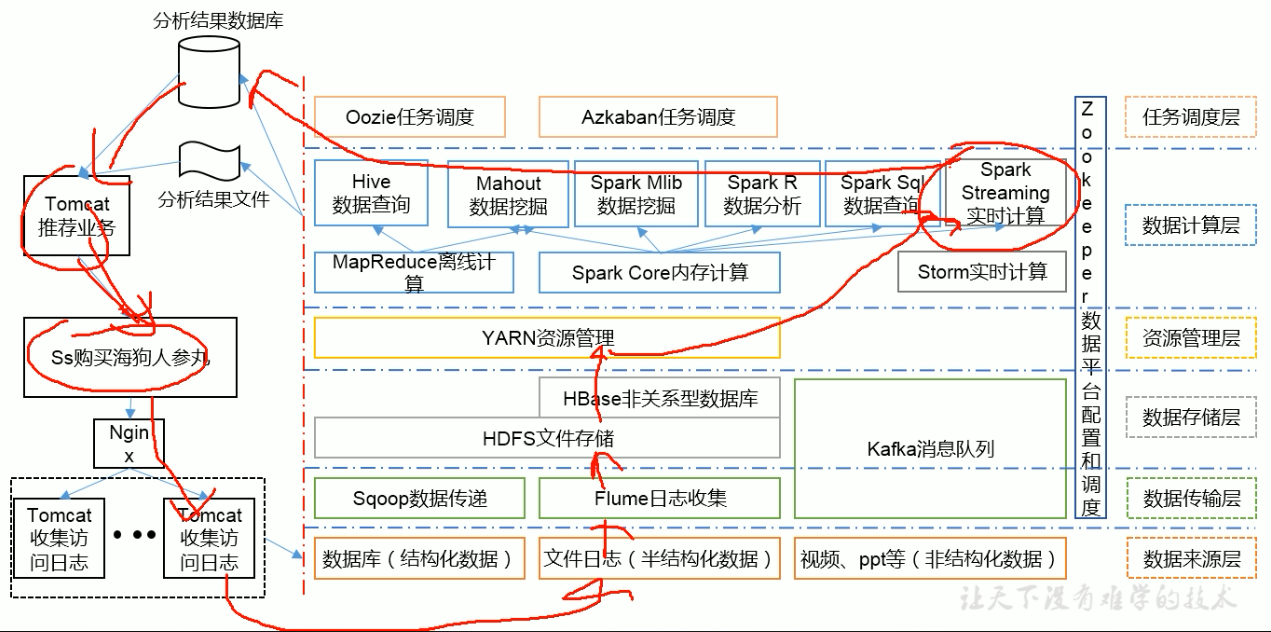
应用场景
- 搭建大型数据仓库,PB级数据的存储、处理、分析、统计
- 日志分析
- 数据挖掘
核心组件
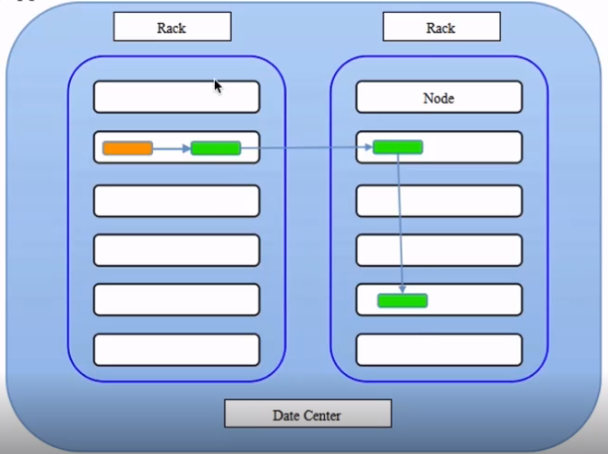
HDFS(分布式文件存储系统)
- 特点:扩展性、容错性、海量数据存储
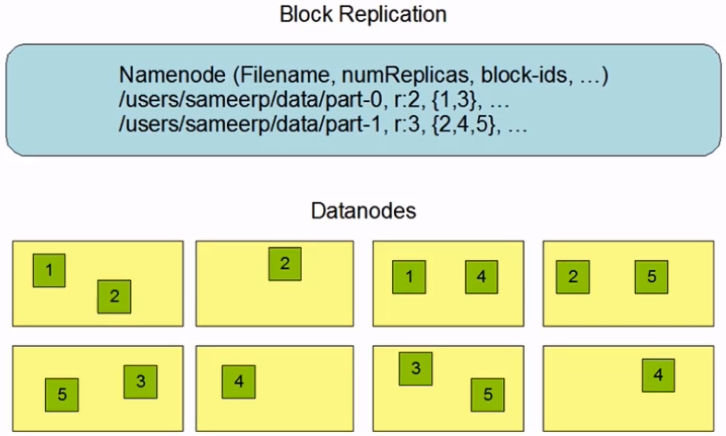
- 将文件切分成指定大小(默认128M)的数据块并以多副本(默认3副本)的存储在多个机器上
- 数据切分、多副本、容错等操作对用户是透明的
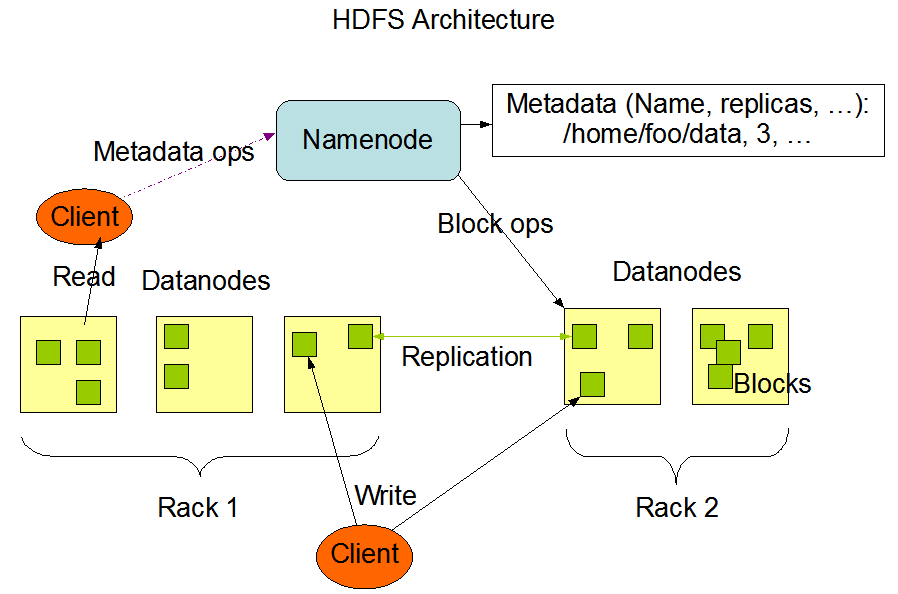
架构
- 1个master(NameNode/NN)带n个slave(datanode/DN)
- 1个文件会被拆分成多个Block(blocksize=128M)
- NN:
- 负责客户端请求响应
- 负责元数据(文件名称、副本系数、block存放的DN)管理
- DN:
- 存储用户的文件对应的数据块(block)
- 定期向NN发送心跳信息,汇报本身及所有的block信息,健康状况
hdfs副本策略
Yarn(资源调度系统)
- 特点:扩展性、容错性(任务失败重试)、多框架资源统一调度 (比如spark、hivesql、hbase、storm)
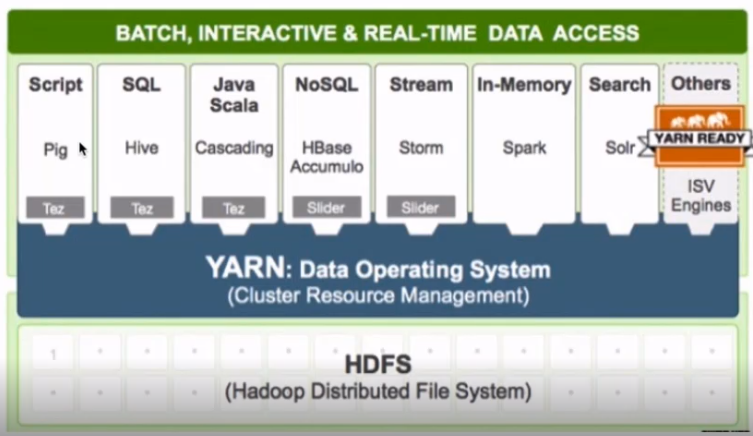
- yarn:Yet another resource negotiator
- 负责整个集群资源的管理和调度
MapReduce(分布式计算框架)
- 特点:扩展性、容错性、海量离线数据处理

Hadoop的优势
高可靠性
- 数据存储:数据块多副本
- 数据计算:重新调度作业计算
扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群可以包含数以千计的节点
其他
Hadoop常用发行版及选型
- Apache Hadoop(解决了单个框架的问题,联合使用时很多包冲突)
- CDH:Cloudera Distributed Hadoop(60~70%)
- HDP:Hortonworks Data PlatForm
-
相关阅读:
命令行下的curl使用详解
升级python版本(从2.4.3到2.6.5)
vim设置
php中curl模拟post提交多维数组
vim折叠设置
基础算法4——归并排序
总线类型
主板分类
网卡 接口类型
基础算法3——直接选择排序和堆排序
-
原文地址:https://www.cnblogs.com/zxbdboke/p/10458615.html
Copyright © 2020-2023
润新知