MySQL分层
MySQL分层
主要分为:连接层,服务层,引擎层,存储层
客户端执行一条select命令的流程如下

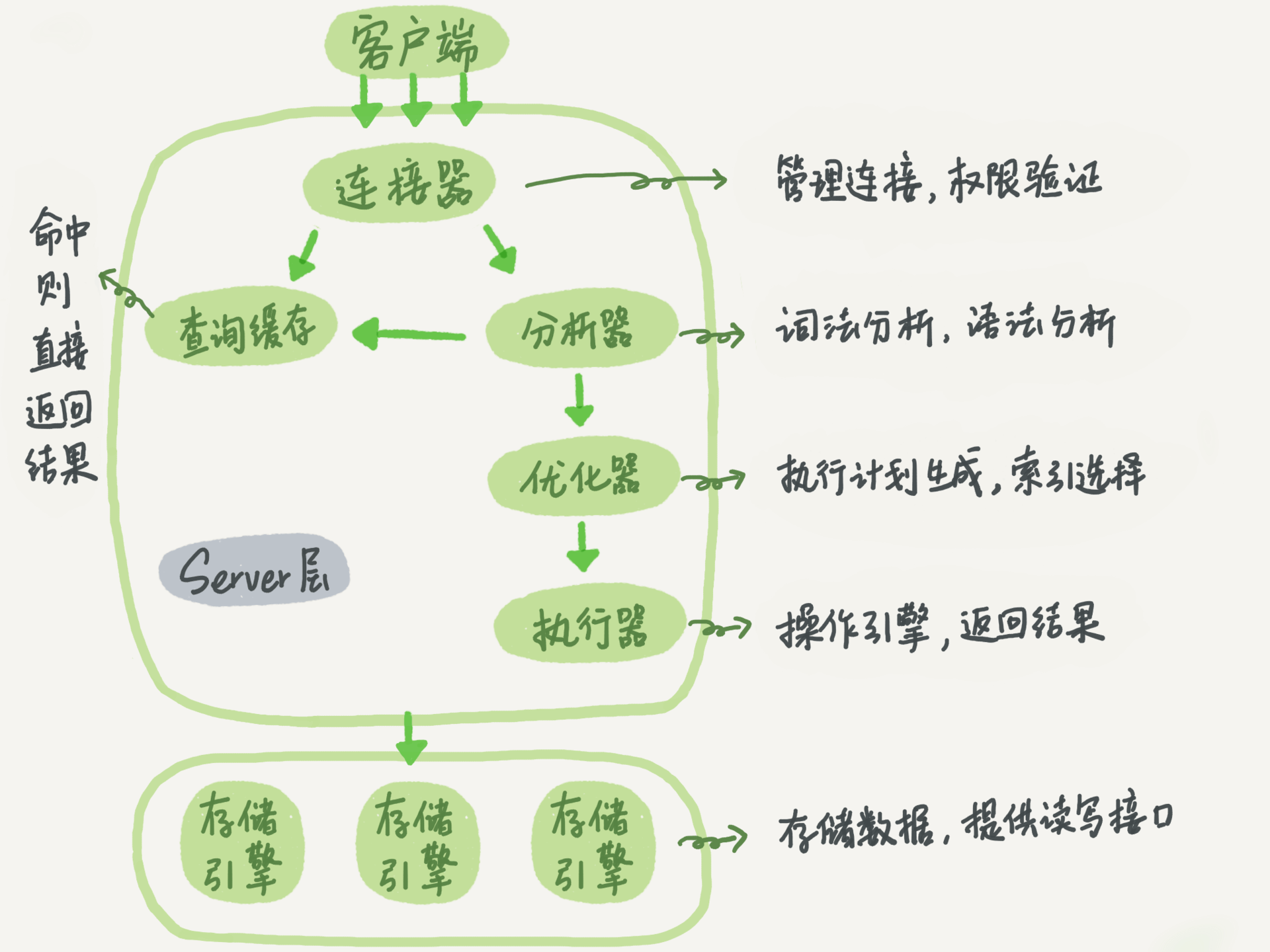
连接器
功能:
负责跟客户端建立连接、获取权限、维持和管理连接
细节:
1.当用户登录成功后,用户就会拿到权限信息,即使管理员更改了你的权限,但是在本次连接中你的权限依然不变
2.连接分,长连接、短连接,连接对象比较消耗内存,要注意连接的管理
报错:
mysql -u -p
这里就会返回账号密码错误
查询缓存
功能:
当连接建立完成后,如果执行查询语句,第二步就会执行查询缓存,如果缓存内有之前的查询结果,那么直接命中返回结果,效率会很高。
缺点(不推荐使用,利大于弊):
查询缓存很容易失效,如果一张表进行了一个更新,那么这张表所有的缓存会被清空。
注意:
MYSQL8.0直接把查询缓存这块给删除了
分析器
功能:
如果查询缓存没有命中,就会进入分析器,进行词法分析和语法分析,会分析表是否存在,字段是否存在等等
报错:
我们一般接触的最多的错误就是从这部分返回的
优化器
功能:
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多个多表查询的时候,会进行决定,用哪个索引,或者先查询哪个表。
虽然不管怎么查询,最后的结果都是一样的,但是不同的查询方式会有不同的查询效率
有时候觉得你写的sql语句太复杂了,性能太低了,mysql帮你的优化sql语句,提高效率(因为是帮你优化改写了你查询的sql,可能会出现一些问题)
执行器:
作用:
既然知道要查询什么,怎么查询了,那么就到了执行器执行的时候了,到这一步会检查你的权限,是否有权限操作相关的表,如果有权限,就打开表,然后根据表的引擎定义,去使用引擎的接口
报错:
如果在查询缓存就命中数据,但是没有权限,则权限错误在查询缓存就会出现,否则,就会在执行器,报出没有权限的错误
引擎:
图中有很多引擎,是因为MySQL有很多的引擎
select * from zx where id=125
执行流程:
(没有索引的表)
执行器调用InnoDB引擎接口取取zx表的第一行,然后判断id是否为125,如果满足条件就返回给结果集,如果不满足就继续拿下一条的数据重复操作,直到遍历了所有数据,最后把结果集返回给客户端
有索引的表,逻辑是差不多的,但是细节有差别
InnoDB和MyISAM区别
InnoDB(默认):事务优先(适合高并发:行锁)
MyISAM:性能优先(表锁)