上一节说到如果要从海量数据中查找字符串的话,红黑树和和hashtable都不行,所以会用到布隆过滤器。
布隆过滤器
1、定义
布隆过滤器是⼀种概率型数据结构,它的特点是⾼效的插⼊和查询,能明确告知某个字符串 ⼀定不存在或者可能存在;
2、优点
布隆过滤器相⽐传统的查询结构(例如:hash,set,map等数据结构)更加⾼效,占⽤空间更 ⼩;
3、缺点
是其缺点是它返回的结果是概率性的,也就是说结果存在误差的,虽然这个误差是可控的; 同时它不⽀持删除操作;
4.原理:

布隆过滤器是由位图(bit数组)+ n个hash函数来实现的,当⼀个元素加⼊位图时,通过k个hash函数将这个元素映射到位图的k个点,并把它们置为 1;当检索时,再通过k个hash函数运算检测位图的k个点是否都为1;如果有不为1的点,那么认为 不存在;如果全部为1,则可能存在(存在误差);
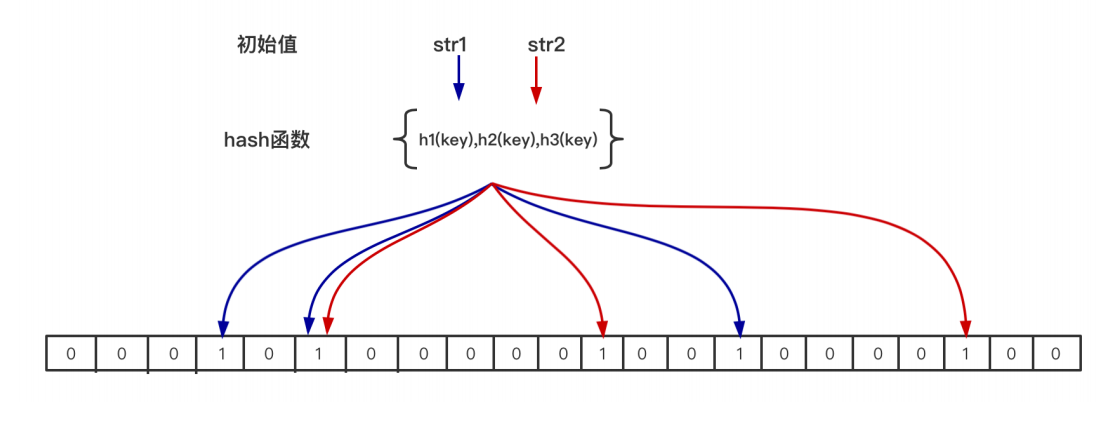
注意:在位图中每个槽位只有两种状态(0或者1),⼀个槽位被设置为1状态,但不明确它被设置了多少 次;也就是不知道被多少个str1哈希映射以及是被哪个hash函数映射过来的;所以不⽀持删除操 作;
5.布隆过滤器的使用
在实际应⽤过程中,布隆过滤器该如何使⽤?要选择多少个hash函数,要分配多少空间的位图,存 储多少元素?另外如何控制假阳率(布隆过滤器能明确⼀定不存在,不能明确⼀定存在,那么存在 的判断是有误差的,假阳率就是错误判断存在的概率)?

假定我们选取这四个值为:
n = 4000
p = 0.000000001
m = 172532
k = 30
四个值的关系:
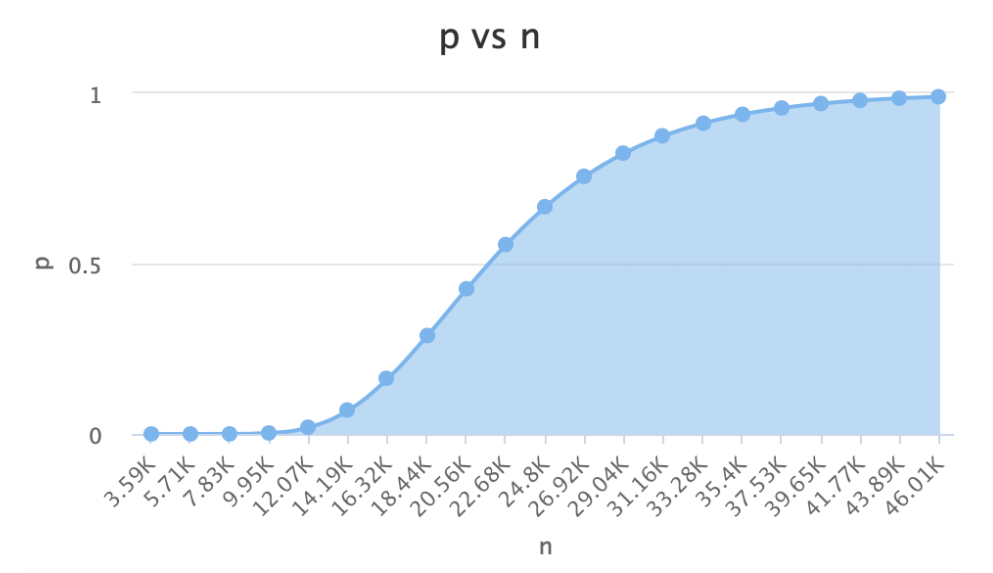
(1)m和k不变时:
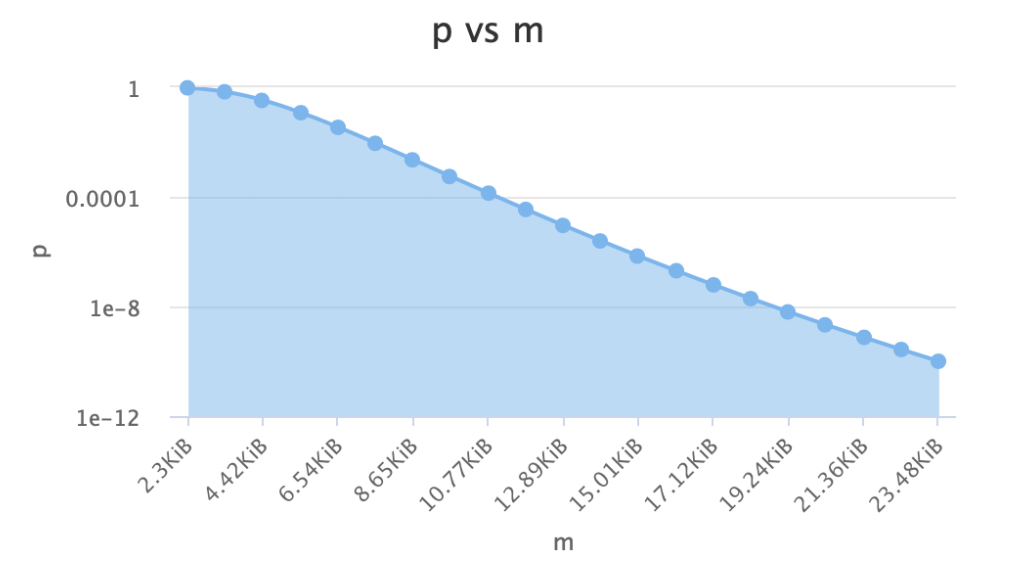
(2)n和k不变时:
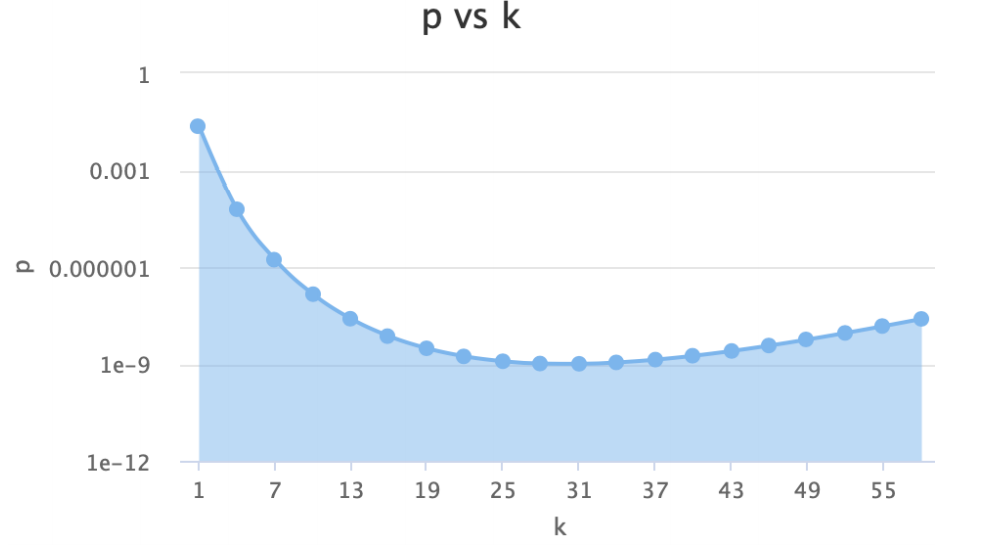
(3)n和m不变时:
在实际应⽤中,我们确定n和p,通过上⾯的计算算出m和k;也可以在⽹站上选取合适的值:https://hur.st/bloomfilter/
已知k,如何选择k个hash函数?
// 采⽤⼀个hash函数,给hash传不同的种⼦偏移值 // #define MIX_UINT64(v) ((uint32_t)((v>>32)^(v))) uint64_t hash1 = MurmurHash2_x64(key, len, Seed); uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1)); for (i = 0; i < k; i++) // k 是hash函数的个数 { Pos[i] = (hash1 + i*hash2) % m; // m 是位图的⼤⼩ } // 通过这种⽅式来模拟 k 个hash函数 跟我们前⾯开放寻址法 双重hash是⼀样的思路
6、布隆过滤器代码:
bloomfilter.h


#ifndef __MICRO_BLOOMFILTER_H__ #define __MICRO_BLOOMFILTER_H__ /** * * 仿照Cassandra中的BloomFilter实现,Hash选用MurmurHash2,通过双重散列公式生成散列函数,参考:http://hur.st/bloomfilter * Hash(key, i) = (H1(key) + i * H2(key)) % m * **/ #include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <math.h> #define __BLOOMFILTER_VERSION__ "1.1" #define __MGAIC_CODE__ (0x01464C42) /** * BloomFilter使用例子: * static BaseBloomFilter stBloomFilter = {0}; * * 初始化BloomFilter(最大100000元素,不超过0.00001的错误率): * InitBloomFilter(&stBloomFilter, 0, 100000, 0.00001); * 重置BloomFilter: * ResetBloomFilter(&stBloomFilter); * 释放BloomFilter: * FreeBloomFilter(&stBloomFilter); * * 向BloomFilter中新增一个数值(0-正常,1-加入数值过多): * uint32_t dwValue; * iRet = BloomFilter_Add(&stBloomFilter, &dwValue, sizeof(uint32_t)); * 检查数值是否在BloomFilter内(0-存在,1-不存在): * iRet = BloomFilter_Check(&stBloomFilter, &dwValue, sizeof(uint32_t)); * * (1.1新增) 将生成好的BloomFilter写入文件: * iRet = SaveBloomFilterToFile(&stBloomFilter, "dump.bin") * (1.1新增) 从文件读取生成好的BloomFilter: * iRet = LoadBloomFilterFromFile(&stBloomFilter, "dump.bin") **/ // 注意,要让Add/Check函数内联,必须使用 -O2 或以上的优化等级 #define FORCE_INLINE __attribute__((always_inline)) #define BYTE_BITS (8) #define MIX_UINT64(v) ((uint32_t)((v>>32)^(v))) #define SETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] |= (1 << (n%BYTE_BITS))) #define GETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] & (1 << (n%BYTE_BITS))) #pragma pack(1) // BloomFilter结构定义 typedef struct { uint8_t cInitFlag; // 初始化标志,为0时的第一次Add()会对stFilter[]做初始化 uint8_t cResv[3]; uint32_t dwMaxItems; // n - BloomFilter中最大元素个数 (输入量) double dProbFalse; // p - 假阳概率 (输入量,比如万分之一:0.00001) uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数 uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数 uint32_t dwSeed; // MurmurHash的种子偏移量 uint32_t dwCount; // Add()的计数,超过MAX_BLOOMFILTER_N则返回失败 uint32_t dwFilterSize; // dwFilterBits / BYTE_BITS unsigned char *pstFilter; // BloomFilter存储指针,使用malloc分配 uint32_t *pdwHashPos; // 存储上次hash得到的K个bit位置数组(由bloom_hash填充) } BaseBloomFilter; // BloomFilter文件头部定义 typedef struct { uint32_t dwMagicCode; // 文件头部标识,填充 __MGAIC_CODE__ uint32_t dwSeed; uint32_t dwCount; uint32_t dwMaxItems; // n - BloomFilter中最大元素个数 (输入量) double dProbFalse; // p - 假阳概率 (输入量,比如万分之一:0.00001) uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter的比特数 uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - 哈希函数个数 uint32_t dwResv[6]; uint32_t dwFileCrc; // (未使用)整个文件的校验和 uint32_t dwFilterSize; // 后面Filter的Buffer长度 } BloomFileHead; #pragma pack() // 计算BloomFilter的参数m,k static inline void _CalcBloomFilterParam(uint32_t n, double p, uint32_t *pm, uint32_t *pk) { /** * n - Number of items in the filter * p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p * m - Number of bits in the filter * k - Number of hash functions * * f = ln(2) × ln(1/2) × m / n = (0.6185) ^ (m/n) * m = -1 * ln(p) × n / 0.6185 , 这里有错误 * k = ln(2) × m / n = 0.6931 * m / n * darren修正: * m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995)) * = -1*n*ln(p)/0.4804530139182079271955440025 * k = ln(2)*m/n **/ uint32_t m, k, m2; // printf("ln(2):%lf, ln(p):%lf ", log(2), log(p)); // 用来验证函数正确性 // 计算指定假阳(误差)概率下需要的比特数 m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453); //darren 修正 m = (m - m % 64) + 64; // 8字节对齐 // 计算哈希函数个数 double double_k = (0.69314 * m / n); // ln(2)*m/n // 这里只是为了debug出来看看具体的浮点数值 k = round(double_k); // 返回x的四舍五入整数值。 printf("orig_k:%lf, k:%u ", double_k, k); *pm = m; *pk = k; return; } // 根据目标精度和数据个数,初始化BloomFilter结构 /** * @brief 初始化布隆过滤器 * @param pstBloomfilter 布隆过滤器实例 * @param dwSeed hash种子 * @param dwMaxItems 存储容量 * @param dProbFalse 允许的误判率 * @return 返回值 * -1 传入的布隆过滤器为空 * -2 hash种子错误或误差>=1 */ inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems, double dProbFalse) { if (pstBloomfilter == NULL) return -1; if ((dProbFalse <= 0) || (dProbFalse >= 1)) return -2; // 先检查是否重复Init,释放内存 if (pstBloomfilter->pstFilter != NULL) free(pstBloomfilter->pstFilter); if (pstBloomfilter->pdwHashPos != NULL) free(pstBloomfilter->pdwHashPos); memset(pstBloomfilter, 0, sizeof(BaseBloomFilter)); // 初始化内存结构,并计算BloomFilter需要的空间 pstBloomfilter->dwMaxItems = dwMaxItems; // 最大存储 pstBloomfilter->dProbFalse = dProbFalse; // 误差 pstBloomfilter->dwSeed = dwSeed; // hash种子 // 计算 m, k _CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, &pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs); // 分配BloomFilter的存储空间 pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS; pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize); if (NULL == pstBloomfilter->pstFilter) return -100; // 哈希结果数组,每个哈希函数一个 pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t)); if (NULL == pstBloomfilter->pdwHashPos) return -200; printf(">>> Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.2fMB, items:bits=1:%0.1lf ", pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits, pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024, pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems); // 初始化BloomFilter的内存 memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize); pstBloomfilter->cInitFlag = 1; return 0; } // 释放BloomFilter inline int FreeBloomFilter(BaseBloomFilter *pstBloomfilter) { if (pstBloomfilter == NULL) return -1; pstBloomfilter->cInitFlag = 0; pstBloomfilter->dwCount = 0; free(pstBloomfilter->pstFilter); pstBloomfilter->pstFilter = NULL; free(pstBloomfilter->pdwHashPos); pstBloomfilter->pdwHashPos = NULL; return 0; } // 重置BloomFilter // 注意: Reset()函数不会立即初始化stFilter,而是当一次Add()时去memset inline int ResetBloomFilter(BaseBloomFilter *pstBloomfilter) { if (pstBloomfilter == NULL) return -1; pstBloomfilter->cInitFlag = 0; pstBloomfilter->dwCount = 0; return 0; } // 和ResetBloomFilter不同,调用后立即memset内存 inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter) { if (pstBloomfilter == NULL) return -1; memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize); pstBloomfilter->cInitFlag = 1; pstBloomfilter->dwCount = 0; return 0; } /// /// 函数FORCE_INLINE,加速执行 /// // MurmurHash2, 64-bit versions, by Austin Appleby // https://sites.google.com/site/murmurhash/ FORCE_INLINE uint64_t MurmurHash2_x64 ( const void * key, int len, uint32_t seed ) { const uint64_t m = 0xc6a4a7935bd1e995; const int r = 47; uint64_t h = seed ^ (len * m); const uint64_t * data = (const uint64_t *)key; const uint64_t * end = data + (len/8); while(data != end) { uint64_t k = *data++; k *= m; k ^= k >> r; k *= m; h ^= k; h *= m; } const uint8_t * data2 = (const uint8_t*)data; switch(len & 7) { case 7: h ^= ((uint64_t)data2[6]) << 48; case 6: h ^= ((uint64_t)data2[5]) << 40; case 5: h ^= ((uint64_t)data2[4]) << 32; case 4: h ^= ((uint64_t)data2[3]) << 24; case 3: h ^= ((uint64_t)data2[2]) << 16; case 2: h ^= ((uint64_t)data2[1]) << 8; case 1: h ^= ((uint64_t)data2[0]); h *= m; }; h ^= h >> r; h *= m; h ^= h >> r; return h; } // 双重散列封装 FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len) { //if (pstBloomfilter == NULL) return; int i; uint32_t dwFilterBits = pstBloomfilter->dwFilterBits; uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed); uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1)); for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++) { pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits; } return; } // 向BloomFilter中新增一个元素 // 成功返回0,当添加数据超过限制值时返回1提示用户 FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len) { if ((pstBloomfilter == NULL) || (key == NULL) || (len <= 0)) return -1; int i; if (pstBloomfilter->cInitFlag != 1) { // Reset后没有初始化,使用前需要memset memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize); pstBloomfilter->cInitFlag = 1; } // hash key到bloomfilter中 bloom_hash(pstBloomfilter, key, len); for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++) { SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]); } // 增加count数 pstBloomfilter->dwCount++; if (pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems) return 0; else return 1; // 超过N最大值,可能出现准确率下降等情况 } // 检查一个元素是否在bloomfilter中 // 返回:0-存在,1-不存在,负数表示失败 FORCE_INLINE int BloomFilter_Check(BaseBloomFilter *pstBloomfilter, const void * key, int len) { if ((pstBloomfilter == NULL) || (key == NULL) || (len <= 0)) return -1; int i; bloom_hash(pstBloomfilter, key, len); for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++) { // 如果有任意bit不为1,说明key不在bloomfilter中 // 注意: GETBIT()返回不是0|1,高位可能出现128之类的情况 if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0) return 1; } return 0; } /* 文件相关封装 */ // 将生成好的BloomFilter写入文件 inline int SaveBloomFilterToFile(BaseBloomFilter *pstBloomfilter, char *szFileName) { if ((pstBloomfilter == NULL) || (szFileName == NULL)) return -1; int iRet; FILE *pFile; static BloomFileHead stFileHeader = {0}; pFile = fopen(szFileName, "wb"); if (pFile == NULL) { perror("fopen"); return -11; } // 先写入文件头 stFileHeader.dwMagicCode = __MGAIC_CODE__; stFileHeader.dwSeed = pstBloomfilter->dwSeed; stFileHeader.dwCount = pstBloomfilter->dwCount; stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems; stFileHeader.dProbFalse = pstBloomfilter->dProbFalse; stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits; stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs; stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize; iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile); if (iRet != 1) { perror("fwrite(head)"); return -21; } // 接着写入BloomFilter的内容 iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile); if ((uint32_t)iRet != pstBloomfilter->dwFilterSize) { perror("fwrite(data)"); return -31; } fclose(pFile); return 0; } // 从文件读取生成好的BloomFilter inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName) { if ((pstBloomfilter == NULL) || (szFileName == NULL)) return -1; int iRet; FILE *pFile; static BloomFileHead stFileHeader = {0}; if (pstBloomfilter->pstFilter != NULL) free(pstBloomfilter->pstFilter); if (pstBloomfilter->pdwHashPos != NULL) free(pstBloomfilter->pdwHashPos); // pFile = fopen(szFileName, "rb"); if (pFile == NULL) { perror("fopen"); return -11; } // 读取并检查文件头 iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile); if (iRet != 1) { perror("fread(head)"); return -21; } if ((stFileHeader.dwMagicCode != __MGAIC_CODE__) || (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS)) return -50; // 初始化传入的 BaseBloomFilter 结构 pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems; pstBloomfilter->dProbFalse = stFileHeader.dProbFalse; pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits; pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs; pstBloomfilter->dwSeed = stFileHeader.dwSeed; pstBloomfilter->dwCount = stFileHeader.dwCount; pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize; pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize); if (NULL == pstBloomfilter->pstFilter) return -100; pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t)); if (NULL == pstBloomfilter->pdwHashPos) return -200; // 将后面的Data部分读入 pstFilter iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile); if ((uint32_t)iRet != pstBloomfilter->dwFilterSize) { perror("fread(data)"); return -31; } pstBloomfilter->cInitFlag = 1; printf(">>> Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMB ", pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits, pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024); fclose(pFile); return 0; } #endif
main.cpp
#include "bloomfilter.h" #include <stdio.h> #define MAX_ITEMS 4000 // 设置最大元素 #define ADD_ITEMS 1000 // 添加测试元素 #define P_ERROR 0.0000001 // 设置误差 int main(int argc, char** argv) { printf(" test bloomfilter "); // 1. 定义BaseBloomFilter static BaseBloomFilter stBloomFilter = {0}; // 2. 初始化stBloomFilter,调用时传入hash种子,存储容量,以及允许的误判率 InitBloomFilter(&stBloomFilter, 0, MAX_ITEMS, P_ERROR); // 3. 向BloomFilter中新增数值 char url[128] = {0}; for(int i = 0; i < ADD_ITEMS; i++){ sprintf(url, "https://0voice.com/%d.html", i); if(0 == BloomFilter_Add(&stBloomFilter, (const void*)url, strlen(url))){ // printf("add %s success", url); }else{ printf("add %s failed", url); } memset(url, 0, sizeof(url)); } // 4. check url exist or not char* str = "https://0voice.com/0.html"; if (0 == BloomFilter_Check(&stBloomFilter, (const void*)str, strlen(str)) ){ printf("https://0voice.com/0.html exist "); } char* str2 = "https://0voice.com/10001.html"; if (0 != BloomFilter_Check(&stBloomFilter, (const void*)str2, strlen(str2)) ){ printf("https://0voice.com/10001.html not exist "); } // 5. free bloomfilter FreeBloomFilter(&stBloomFilter); getchar(); return 0; }