先看一下原理性的文章:http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/ ,http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/ , 另外,spark的存储使用了Segment File的概念(http://en.wikipedia.org/wiki/Segmented_file_transfer ),概括的说,它是把文件划分成多个段,分别存储在不同的服务器上;在读取的时候,同时从这些服务器上读取。(这也是BT的基础)。
之前分析shuffle的调用关系的时候,其实已经包含了很多的BlockManager的流程,但还是有必要系统的看一遍它的代码。
getLocalFromDisk这个函数,是前面看shuffleManager的终点,但却是BlockManager的起点。即使是到远端获取block的操作,也是发送一个消息到远端服务器上执行getLocalFromDisk,然后再把结果发送回来。
->diskStore.getValues(blockId, serializer)
============================BlockManager============================
-> BlockManager::getLocalFromDisk
->diskStore.getValues(blockId, serializer)
->getBytes(blockId).map(bytes => blockManager.dataDeserialize(blockId, bytes, serializer))
->val segment = diskManager.getBlockLocation(blockId) --DiskBlockManager的方法,获取block在一个文件中的一个块位置
->if blockId.isShuffle and env.shuffleManager.isInstanceOf[SortShuffleManager] --如果是hash类型shuffle,
->sortShuffleManager.getBlockLocation(blockId.asInstanceOf[ShuffleBlockId], this) --For sort-based shuffle, let it figure out its blocks
->else if blockId.isShuffle and shuffleBlockManager.consolidateShuffleFiles --联合文件模式
->shuffleBlockManager.getBlockLocation(blockId.asInstanceOf[ShuffleBlockId]) --For hash-based shuffle with consolidated files
->val shuffleState = shuffleStates(id.shuffleId) --
->for (fileGroup <- shuffleState.allFileGroups)
->val segment = fileGroup.getFileSegmentFor(id.mapId, id.reduceId) --次函数单独分析
->if (segment.isDefined) { return segment.get }
->else
->val file = getFile(blockId.name)--getFile(filename: String): File
->val hash = Utils.nonNegativeHash(filename)
->val dirId = hash % localDirs.length
->val subDirId = (hash / localDirs.length) % subDirsPerLocalDir
->var subDir = subDirs(dirId)(subDirId)
->new File(subDir, filename)
->new FileSegment(file, 0, file.length())
->val channel = new RandomAccessFile(segment.file, "r").getChannel
->if (segment.length < minMemoryMapBytes)
->channel.position(segment.offset)
->channel.read(buf)
->return buf
->else
->return Some(channel.map(MapMode.READ_ONLY, segment.offset, segment.length))
ShuffleFileGroup:如何通过mapId和reduceId在ShuffleBlockManager 中获取数据:getFileSegmentFor函数
->根据reduceId从ShuffleFileGroup的属性val files: Array[File]里面找到reduce的文件句柄fd
->根据mapId从mapIdToIndex找到index,
->根据reduce找到blockOffset向量和blockLen向量,
->再通过index从向量里面找到offset和len,
->最后通过offset和len从fd里面读取到需要的数据
从远本地取数据
->BlockManager::doGetLocal
->val info = blockInfo.get(blockId).orNull
->val level = info.level
->if (level.useMemory) --Look for the block in memory
->val result = if (asBlockResult)
->memoryStore.getValues(blockId).map(new BlockResult(_, DataReadMethod.Memory, info.size))
->esle
->memoryStore.getBytes(blockId)
->if (level.useOffHeap) -- Look for the block in Tachyon
->tachyonStore.getBytes(blockId)
->if (level.useDisk)
->val bytes: ByteBuffer = diskStore.getBytes(blockId)
->if (!level.useMemory) // If the block shouldn't be stored in memory, we can just return it
->if (asBlockResult)
->return Some(new BlockResult(dataDeserialize(blockId, bytes), DataReadMethod.Disk, info.size))
->else
->return Some(bytes)
->else --memory// Otherwise, we also have to store something in the memory store
->if (!level.deserialized || !asBlockResult) 不序列化或者不block"memory serialized", or if it should be cached as objects in memory
->val copyForMemory = ByteBuffer.allocate(bytes.limit)
->copyForMemory.put(bytes)
->memoryStore.putBytes(blockId, copyForMemory, level)
->if (!asBlockResult)
->return Some(bytes)
->else --需要序列化再写内存
->val values = dataDeserialize(blockId, bytes)
->if (level.deserialized) // Cache the values before returning them
->val putResult = memoryStore.putIterator(blockId, values, level, returnValues = true, allowPersistToDisk = false)
->putResult.data match case Left(it) return Some(new BlockResult(it, DataReadMethod.Disk, info.size))
->else
->return Some(new BlockResult(values, DataReadMethod.Disk, info.size))
->val values = dataDeserialize(blockId, bytes)
从远端获取数据
->BlockManager::doGetRemote
->val locations = Random.shuffle(master.getLocations(blockId)) --随机打散
->for (loc <- locations) --遍历所有地址
->val data = BlockManagerWorker.syncGetBlock(GetBlock(blockId), ConnectionManagerId(loc.host, loc.port))
->val blockMessage = BlockMessage.fromGetBlock(msg)
->val newBlockMessage = new BlockMessage()
->newBlockMessage.set(getBlock)
->typ = BlockMessage.TYPE_GET_BLOCK
->id = getBlock.id
->val blockMessageArray = new BlockMessageArray(blockMessage)
-> val responseMessage = Try(Await.result(connectionManager.sendMessageReliably(toConnManagerId, blockMessageArray.toBufferMessage), Duration.Inf))
->responseMessage match {case Success(message) => val bufferMessage = message.asInstanceOf[BufferMessage]
->logDebug("Response message received " + bufferMessage)
->BlockMessageArray.fromBufferMessage(bufferMessage).foreach(blockMessage =>
->logDebug("Found " + blockMessage)
->return blockMessage.getData
->return Some(data)
===========================end=================================
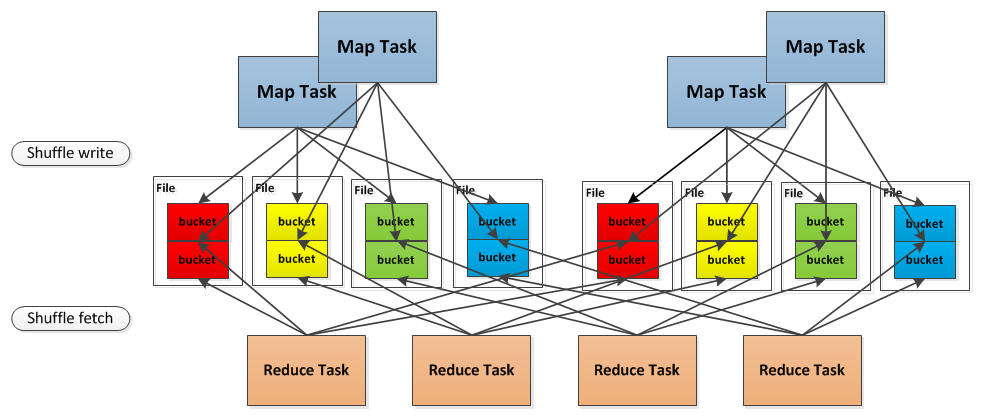
再次引用这个图:多个map可以对应一个文件,其中每个map对应文件中的某些段。这样做是为了减少文件数量。
获取block数据返回的数据结构
/* Class for returning a fetched block and associated metrics. */
private[spark] class BlockResult(
val data: Iterator[Any],
readMethod: DataReadMethod.Value,
bytes: Long) {
val inputMetrics = new InputMetrics(readMethod)
inputMetrics.bytesRead = bytes
}
private[spark] class BlockManager(
executorId: String,
actorSystem: ActorSystem,
val master: BlockManagerMaster,
defaultSerializer: Serializer,
maxMemory: Long,
val conf: SparkConf,
securityManager: SecurityManager,
mapOutputTracker: MapOutputTracker,
shuffleManager: ShuffleManager)
extends BlockDataProvider with Logging {
shuffle状态,主要包含了unusedFileGroups、allFileGroups两个属性,记录当前已经使用和未使用的ShuffleFileGroup
/**
* Contains all the state related to a particular shuffle. This includes a pool of unused
* ShuffleFileGroups, as well as all ShuffleFileGroups that have been created for the shuffle.
*/
private class ShuffleState(val numBuckets: Int) {
val nextFileId = new AtomicInteger(0)
val unusedFileGroups = new ConcurrentLinkedQueue[ShuffleFileGroup]()
val allFileGroups = new ConcurrentLinkedQueue[ShuffleFileGroup]()
/**
* The mapIds of all map tasks completed on this Executor for this shuffle.
* NB: This is only populated if consolidateShuffleFiles is FALSE. We don't need it otherwise.
*/
val completedMapTasks = new ConcurrentLinkedQueue[Int]()
}
shuffleStates 是一个基于时间戳的hash table
private val shuffleStates = new TimeStampedHashMap[ShuffleId, ShuffleState]
private val metadataCleaner =
new MetadataCleaner(MetadataCleanerType.SHUFFLE_BLOCK_MANAGER, this.cleanup, conf)
Used by sort-based shuffle: shuffle结束时将结果注册到shuffleStates
/**
* Register a completed map without getting a ShuffleWriterGroup. Used by sort-based shuffle
* because it just writes a single file by itself.
*/
def addCompletedMap(shuffleId: Int, mapId: Int, numBuckets: Int): Unit = {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
val shuffleState = shuffleStates(shuffleId)
shuffleState.completedMapTasks.add(mapId)
}
将自己注册给master
/**
* Initialize the BlockManager. Register to the BlockManagerMaster, and start the
* BlockManagerWorker actor.
*/
private def initialize(): Unit = {
master.registerBlockManager(blockManagerId, maxMemory, slaveActor)
BlockManagerWorker.startBlockManagerWorker(this)
}
从本地磁盘获取一个block数据。为了方便使用
/**
* A short-circuited method to get blocks directly from disk. This is used for getting
* shuffle blocks. It is safe to do so without a lock on block info since disk store
* never deletes (recent) items.
*/
def getLocalFromDisk(blockId: BlockId, serializer: Serializer): Option[Iterator[Any]] = {
diskStore.getValues(blockId, serializer).orElse {
throw new BlockException(blockId, s"Block $blockId not found on disk, though it should be")
}
}
ShuffleWriterGroup:每个shuffleMapTask都有一组shuffleWriter,它给每个reducer分配了一个writer。当前只有HashShufflle使用了,唯一一个实例化是在forMapTask返回的,给HashShuffleWriter的shuffle属性使用:
/** A group of writers for a ShuffleMapTask, one writer per reducer. */
private[spark] trait ShuffleWriterGroup {
val writers: Array[BlockObjectWriter]
/** @param success Indicates all writes were successful. If false, no blocks will be recorded. */
def releaseWriters(success: Boolean)
}
/**
* Manages assigning disk-based block writers to shuffle tasks. Each shuffle task gets one file
* per reducer (this set of files is called a ShuffleFileGroup).
*
* As an optimization to reduce the number of physical shuffle files produced, multiple shuffle
* blocks are aggregated into the same file. There is one "combined shuffle file" per reducer
* per concurrently executing shuffle task. As soon as a task finishes writing to its shuffle
* files, it releases them for another task.
* Regarding the implementation of this feature, shuffle files are identified by a 3-tuple:
* - shuffleId: The unique id given to the entire shuffle stage.
* - bucketId: The id of the output partition (i.e., reducer id)
* - fileId: The unique id identifying a group of "combined shuffle files." Only one task at a
* time owns a particular fileId, and this id is returned to a pool when the task finishes.
* Each shuffle file is then mapped to a FileSegment, which is a 3-tuple (file, offset, length)
* that specifies where in a given file the actual block data is located.
*
* Shuffle file metadata is stored in a space-efficient manner. Rather than simply mapping
* ShuffleBlockIds directly to FileSegments, each ShuffleFileGroup maintains a list of offsets for
* each block stored in each file. In order to find the location of a shuffle block, we search the
* files within a ShuffleFileGroups associated with the block's reducer.
*/
// TODO: Factor this into a separate class for each ShuffleManager implementation
private[spark]
class ShuffleBlockManager(blockManager: BlockManager,
shuffleManager: ShuffleManager) extends Logging {
ShuffleFileGroup是一组文件,每个reducer对应一个。每个map将会对应一个这个文件(但多个map可以对应一个文件)。多个map对应一个文件时,它们写入是分段写入的(mapId,ReduceId)通过getFileSegmentFor函数获取到这个块的内容
private[spark]
object ShuffleBlockManager {
/**
* A group of shuffle files, one per reducer.
* A particular mapper will be assigned a single ShuffleFileGroup to write its output to.
*/
private class ShuffleFileGroup(val shuffleId: Int, val fileId: Int, val files: Array[File]) {
private var numBlocks: Int = 0
/**
* Stores the absolute index of each mapId in the files of this group. For instance,
* if mapId 5 is the first block in each file, mapIdToIndex(5) = 0.
*/
private val mapIdToIndex = new PrimitiveKeyOpenHashMap[Int, Int]()
/**
* Stores consecutive offsets and lengths of blocks into each reducer file, ordered by
* position in the file.
* Note: mapIdToIndex(mapId) returns the index of the mapper into the vector for every
* reducer.
*/
private val blockOffsetsByReducer = Array.fill[PrimitiveVector[Long]](files.length) {
new PrimitiveVector[Long]()
}
private val blockLengthsByReducer = Array.fill[PrimitiveVector[Long]](files.length) {
new PrimitiveVector[Long]()
}
def apply(bucketId: Int) = files(bucketId)
def recordMapOutput(mapId: Int, offsets: Array[Long], lengths: Array[Long]) {
assert(offsets.length == lengths.length)
mapIdToIndex(mapId) = numBlocks
numBlocks += 1
for (i <- 0 until offsets.length) {
blockOffsetsByReducer(i) += offsets(i)
blockLengthsByReducer(i) += lengths(i)
}
}
/** Returns the FileSegment associated with the given map task, or None if no entry exists. */
def getFileSegmentFor(mapId: Int, reducerId: Int): Option[FileSegment] = {
val file = files(reducerId)
val blockOffsets = blockOffsetsByReducer(reducerId)
val blockLengths = blockLengthsByReducer(reducerId)
val index = mapIdToIndex.getOrElse(mapId, -1)
if (index >= 0) {
val offset = blockOffsets(index)
val length = blockLengths(index)
Some(new FileSegment(file, offset, length))
} else {
None
}
}
}
}