Abstract
RDDs provide a restricted form of shared memory, based on coarse grained transformations rather than fine-grained updates to shared state.
RDD 提供的是粗粒度的更新操作。其实是指RDD是不可改变的,如果要更新数据,需要创建一个新的RDD代替。但这并不意味着更新的操作代价就非常大,因为你可以把大数据集拆分成多个小的RDD,大数据集的部分更新,其实对应着其中的某(几)个RDD更新。
Introducction
*** offer an interface based on fine-grained updates to mutable state (e.g., cells in a table). With this interface, the only ways to provide fault tolerance are to replicate the data across machines or to log updates across machines. Both approaches are expensive for data-intensive workloads, as they require copying large amounts of data over the cluster network, whose bandwidth is far lower than that of RAM, and they incur substantial storage overhead.
文中指出,使用细粒度的更新(平时见到的更新内存和文件,都是细粒度更新,因为允许更新部分内容),保证容错性的唯一方法是将数据或数据的log复制到其它机器上。
RDDs provide an interface based on coarse-grained transformations (e.g., map,filter and join) that apply the same operation to many data items. This allows them to efficiently provide fault tolerance by logging the transformations used to build a dataset (its lineage) rather than the actual data.
RDD使用粗粒度更新(不可变性质),这样它就可以通过记录数据的转换过程(血统lineage)来做容错(,而不需要备份真正的更新后的数据)。文中后面指出,RDD的lingage一般不超过10k大小。
2 Resilient Distributed Datasets(RDDs)
2.1 RDD Abstraction
Formally, an RDD is a read-only, partitioned collection of records. RDDs can only be created through deterministic operations on either (1) data in stable storage or (2) other RDDs. We call these operations transformations to differentiate them from other perations on RDDs. Examples of transformations include map, filter, and join
RDD是只读、分片的数据集,它只能通过确切的方法在两个源上创建:1)可靠存储中的数据;2)其他RDD。 RDD支持很多操作,为了特别区别其中这些创建RDD的操作,将它们称为transformation,像map、filter、join
in essence, a program cannot reference an RDD that it cannot reconstruct after a failure
程序不能引用已经失效的RDD。这是为了保证所有的RDD都“师出有名”。
2.2 Spark Programming Interface
each dataset is represented as an object and transformations are invoked using methods on these objects.
每个数据集都是一个对象,而transformation是对象的一个方法
They can then use these RDDs in actions, which are operations that return a value to the application or export data to a storage system.
RDD起源于可靠存储设备,然后可以生成其他的RDD。RDD还可以使用action来返回一个值给用户或者将数据存储到存储设备(action操作不会产生新的RDD,可以认为是RDD的输出,也可以认为是lineage的‘叶子节点‘或’末端‘)
Spark computes RDDs lazily the first time they are used in an action, so that it can pipeline transformations.
Spark会将RDD的实例化推迟到真正使用到action的时候,这样中间环节的多个RDD转换就可能进行串行化转换操作。(这是spark性能高的另一个主要原因)
In addition, programmers can call a persist method to indicate which RDDs they want to reuse in future operations
程序员可以指定哪个RDD需要重用,将他们保留在内存/磁盘中。(后续版本会致力于自动做这个决定,因为这是个艰难的决定。。)
3 Spark Programming Interface
To use Spark, developers write a driver program that connects to a cluster of workers, as shown in Figure 2. The driver defines one or more RDDs and invokes actions on them. Spark code on the driver also tracks the RDDs’ lineage. The workers are long-lived rocesses that can store RDD partitions in RAM across operations.
这短短的一小段,就将spark的工作原理描述得很清晰了(此时的spark仅有14k的源码!!)这里吧driver、worker的概念、关系以及运行方式都介绍了。特别注意的一点:RDD的血统(lingeage)是保存子啊driver中的。
RDDs themselves are statically typed objects parametrized by an element type. For example, RDD[Int] is an RDD of integers. However, most of our examples omit types since Scala supports type inference.
RDD支持的操作:(特别注意入参合出参的关系和形式)

4. Representing RDDs
In a nutshell, we propose representing each RDD through a common interface that exposes five pieces of information: a set of partitions, which are atomic pieces of the dataset; a set of dependencies on parent RDDs; a function for computing the dataset based on its parents; and metadata about its partitioning scheme and data placement.
RDD由5个部分组成:
- 数据分片,作为数据集的原子分片;
- 与父节点的依赖集合;
- 一个指明它是怎么从父节点创建而来的函数;
- 数据分片的元数据,关于分片模式的。
- 指明RDD怎么存储的数据
下面是RDD的两个重要概念: 窄依赖和宽依赖
We found it both sufficient and useful to classify dependencies into two types: narrow dependencies, where each partition of the parent RDD is used by at most one partition of the child RDD, wide dependencies, where multiple child partitions may depend on it. For example, map leads to a narrow dependency, while join leads to to wide dependencies
窄依赖:父节点的每个分片数据,最多只被一个子节点依赖;
宽依赖: 父节点的每个分片,被多个子节点依赖;
This distinction is useful for two reasons. First, narrow dependencies allow for pipelined execution on one cluster node, which can compute all the parent partitions. For example, one can apply a map followed by a filter on an element-by-element basis. In contrast, wide dependencies require data from all parent partitions to be available and to be shuffled across the nodes using a apReducelike operation. Second, recovery after a node failure is more efficient with a narrow dependency, as only the lost parent partitions need to be recomputed, and they can be recomputed in parallel on different nodes. In contrast, in a lineage graph with wide dependencies, a single failed node might cause the loss of some partition from all the ancestors of an RDD, requiring a complete re-execution
窄依赖的优点:
- 串行化允许多个RDD操作在一个机器上串行化处理(因为它不依赖于其他RDD),可以避免RDD传输的网络开销,以及各个操作之间的同步等待;
- 当一个RDD失效后,仅需要获取它的父节点,执行transformation重新生成这个RDD。
This common interface for RDDs made it possible to implement most transformations in Spark in less than 20 lines of code
5 Implementation
We have implemented Spark in about 14,000 lines of Scala.
5.1 Job Scheduling
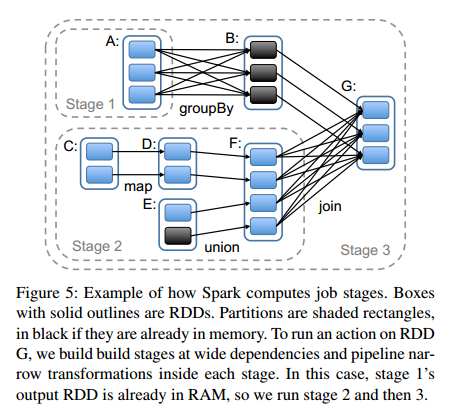
Whenever a user runs an action (e.g., count or save) on an RDD, the scheduler examines that RDD’s lineage graph to build a DAG
of stages to execute, as illustrated in Figure 5. Each stage contains as many pipelined transformations with narrow dependencies as possible. The boundaries of the stages are the shuffle operations required for wide dependencies, or any already computed partitions that can shortcircuit the computation of a parent RDD. The scheduler then launches tasks to compute missing partitions from each stage until it has computed the target RDD.
- 调度是被一个action触发的
- 调度器根据血统生成DAG
- 调度器将DAG划分为不同的stage,划分的原则是尽可能多的包含串行操作;
- stage的边界一般是 1)shuffle操作; 2)已经固化(保留在内存或磁盘的)RDD
- 调度器开始创建缺失数据分片的RDD,直到最后创建了目标(执行action操作的)RDD。
Our scheduler assigns tasks to machines based on data locality using delay scheduling [32]. If a task needs to process a partition that is available in memory on a node, we send it to that node. Otherwise, if a task processes a partition for which the containing RDD provides preferred locations (e.g., an HDFS file), we send it to those
调度器的本地化策略:基于本地化的延时调度,算法论文:http://people.csail.mit.edu/matei/papers/2010/eurosys_delay_scheduling.pdf
以后再看。
- 如果一个task处理中需要的分片数据在另一个节点的内存中,那么将task发送到那个节点处理(而不是将数据拉过来);
- 如果一个task处理的数据分片包含本地化信息,将task发到本地化信息中认为最优的那个节点(例如HDFS就有这些信息)
For wide dependencies (i.e., shuffle dependencies), we currently materialize intermediate records on the nodes holding parent partitions to simplify fault recovery
为了简化数据恢复,当前宽依赖是将中奖结果保存到磁盘,像hdfs那样
5.2 Interpreter Integration
The Scala interpreter normally operates by compiling a class for each line typed by the user, loading it into the JVM, and invoking a function on it. This class includes a singleton object that contains the variables or functions on that line and runs the line’s code in an initialize method.For example, if the user types var x = 5 followed by println(x), the interpreter defines a class called Line1 containing x and causes the second line to compile to println(Line1.getInstance().x)
将每行创建一个class,每行中的变量就是class的一个成员变量;其他行引用这些变量时,是通过访问这个class的成员变量实现的。
spark做的改动:
- 使用HTTP协议让work能获取每行定义的class;
- 使用逻辑引用前面行的变量,而不是单例对象. 目的是避免JVM不把静态成员序列化的特点。
5.3 Memory Management
用户可以选择将RDD保留在内存或磁盘中;在内存中还分为原生对象和序列化对象两种形式
性能:原生对象比序列化对象快2X;比磁盘的快10X以上;
To manage the limited memory available, we use an LRU eviction policy at the level of RDDs, unless this is the same RDD as the one with the new partition
内存不足时, 使用LRU淘汰使用少的RDD,但如果一个RDD被新创建的RDD使用,则不淘汰(避免循环淘汰)
5.4 Support for Checkpointing
In general, checkpointing is useful for RDDs with long lineage graphs containing wide dependencies。
往往是为了避免RDD有过多的依赖信息。
最后的亮点:
