每周一篇又来了。这次主要介绍netio的buffer管理器。 首先buffer管理是每一个网络层不可回避的问题。怎么高效的使用buffer是很关键的问题。这里主要介绍下我们的netio是怎么处理。说实话 这是我见过比较蛋疼buffer管理。 反正我是看了好几天 才看明白的。
最近看了下Qcon2016的视频.里面很多大牛介绍分布式平台。 感觉特别牛逼~~。 感觉我们的分布式相比他们的这些还是简陋了点。感兴趣的同学可以去看看
http://daxue.qq.com/content/special/id/20
1.1 我们先看下 一次系统调用recv就能收到完整包的情况
1)首先通过系统调用函数recv 会每次把从TCP读到的数据放到
m_achRecvBuf[TPT_RECV_BUF_LEN];
这个buf大小为128*1024
2、判断包头。
先判断是否是0x5a5a
然后解析包头判断 需要发送过来的总长度 如果大于1024*1024就报错。
1024*1024是在初始化的时候申请的大小。 我们的一个最大请求包已经限定为1M

如果发现tcp一次就能收到完整的包。
netio并不会使用我们字节的buf管理器。
m_pSink->OnRecv而是直接丢给netio的app类去处理。
然后等netio中app类对包做了具体的处理后。
网络层 发现处理完以后就会直接 重新跳到while 循环中等待新事件
int CNetHandleMng::_RetrievePkgData(int nHandle,char* pRcvBuf,int nBufLen) { ...... //当前数据包已经读取完成 m_pSink->OnRecv(nHandle,pRcvBuf+TPT_HEAD_LEN,dwPkgLen); return (dwPkgLen + TPT_HEAD_LEN); }
int CNetHandleMng::OnRecv(int nHandle,char* pRcvBuf,int nBufLen) { stConn* pConn = _GetConn(nHandle); if( NULL == pConn ) { std::stringstream oss; oss<<"reactor report recv data for connection handle"<<nHandle<<" but we cann't found the connection data"<<std::endl; m_pSink->ReportTptError(__FILE__,__LINE__,__func__,oss.str().c_str()); return 0; } int nReadLen =0; if( 0 == pConn->m_pRcvBuf->m_nDataLen ) { nReadLen = _RetrievePkgsData(nHandle,pRcvBuf,nBufLen); if( nReadLen < 0 ) return nReadLen;//reactor层会自动关闭连接 if( nReadLen >= nBufLen ) return 0;//数据已经处理完毕 ..... }
我们发现在一次recv能收完整个数据包的时候。平台没用字节的buf管理器。而是直接就给netio app类来处理了
1.2 我们先看下 一次系统调用recv收不完包的情况。
5.2.1 我们先分析下一个具体的例子 然后再慢慢的归纳和总结

a)为什么是256个指针?
初始化的时候
CNetioApp::CNetioApp():CNetMsgqSvr(4096*5,1024*1024,4*1024)buffer管理器中 最小的一个buf大小是4*1024
(1024*1024+4*1024 -1 ) / (1024*4) = 256
然后分配256个大小的二维指针。
所以初始化的时候 会设置一个大小为256的二维指针。注意这里只是创建二维指针。当时并没有给每个指针指向的对象分配空间。b) 当客户端首次connet的时候。会继续初始化一些信息
当客户端connet请求来临时候。会去buffer管理器取一块buffer。
默认情况下。都是取p[0]里的buffer。
当buffer管理器 发现p[0]为空的时候。 会去创建10个buffer 。这里10是写死的。 由于是p[0]是第一行。那么每个buffer的大小是4096.
这10个buffer 是一个链表。 index=0是最先创建的。index=9是最后创建的。
如上图。 index=9被拿出去了 。但其实这个时候并没有数据过来。
这个不管。被connet信息结构体指向的buffer。我们都认为是在使用中。
这个时候p[0] 就会跳到index=8.
注意 二维指针 永远是指向未被使用的buffer。这很重要。如果没有空间。会继续创建buffer
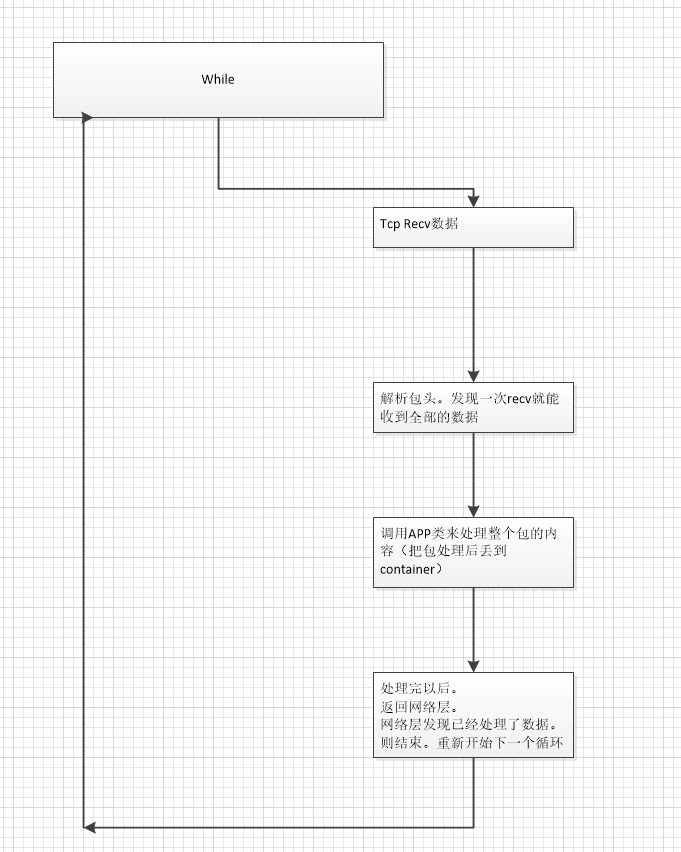
c) 第一次recv 16384数据
这里发现收到的16384个字节 大于4096个字节。
则buffer管理器。会在p[3] 这里申请10个buffer块。
每块 1024*4*4=16384 刚好 放下recv的16384数据
因为不用p[0]的buffer块。 则先回退p[0]的指向。从index=8 到index=9
然后让connet信息块 重新指向p[3]的index=9
前面说了 二维指针一定要指向未被使用的buffer。 所有p[3] 指向index=8
同时在m_nDatalen里面记录 已经保存的字节数
这个时候还没有收完 需要继续收数据
d) 第二次recv 16384数据
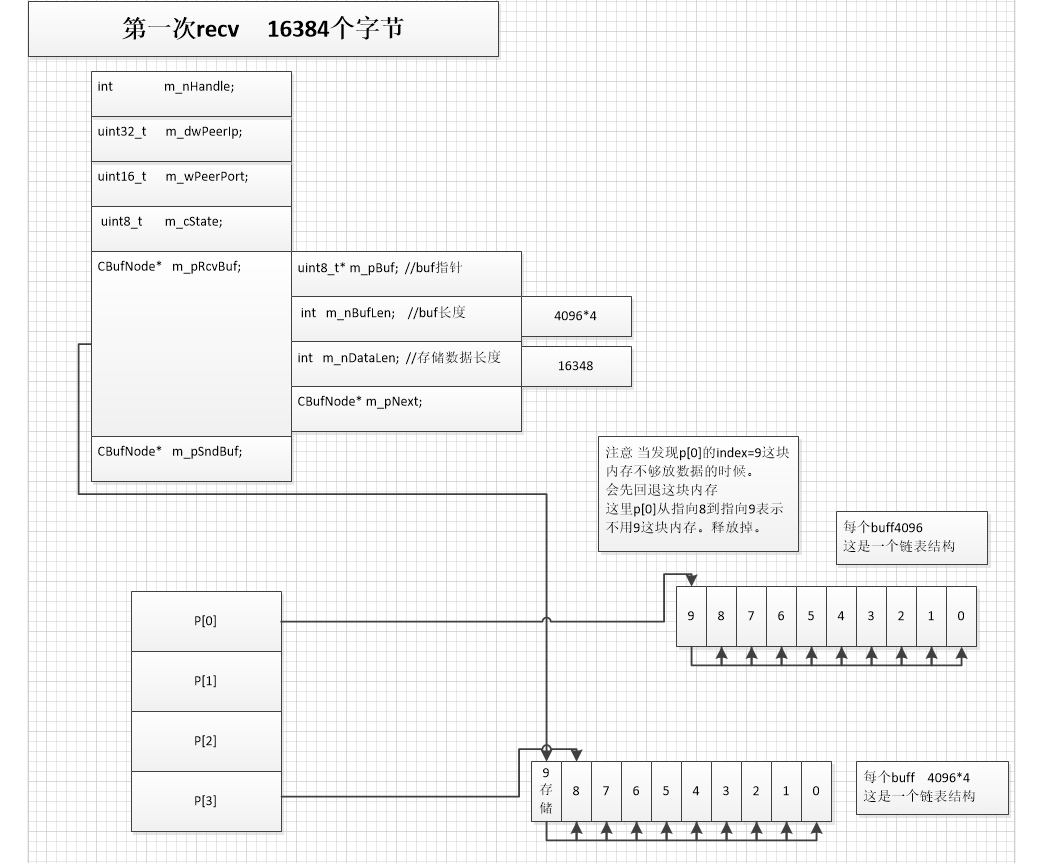
注意 第二次也收到了16384.
那么第二次的16384 + 上次的16384 = 32768
这个时候p[3] 这一列的buffer放不下。 需要重新创建buffer
这个时候在p[7] 这一列上创建 4*1024*8 =32768 刚好放下所有数据
这个时候在p[7] 创建10个buffer 。 每个buffer为4*1024*8
接着还是要归还p[3] buffer的使用权。这个时候吧p[3]的指针指向index = 9 同时把 index=9里面的m_nDatalen设置为0.
这样就表示p[3]的index=9被 释放了。 但是其实index=9还是有内容的并没有清除。
接着我们把累加的数据 放到p[7]的index=9里面
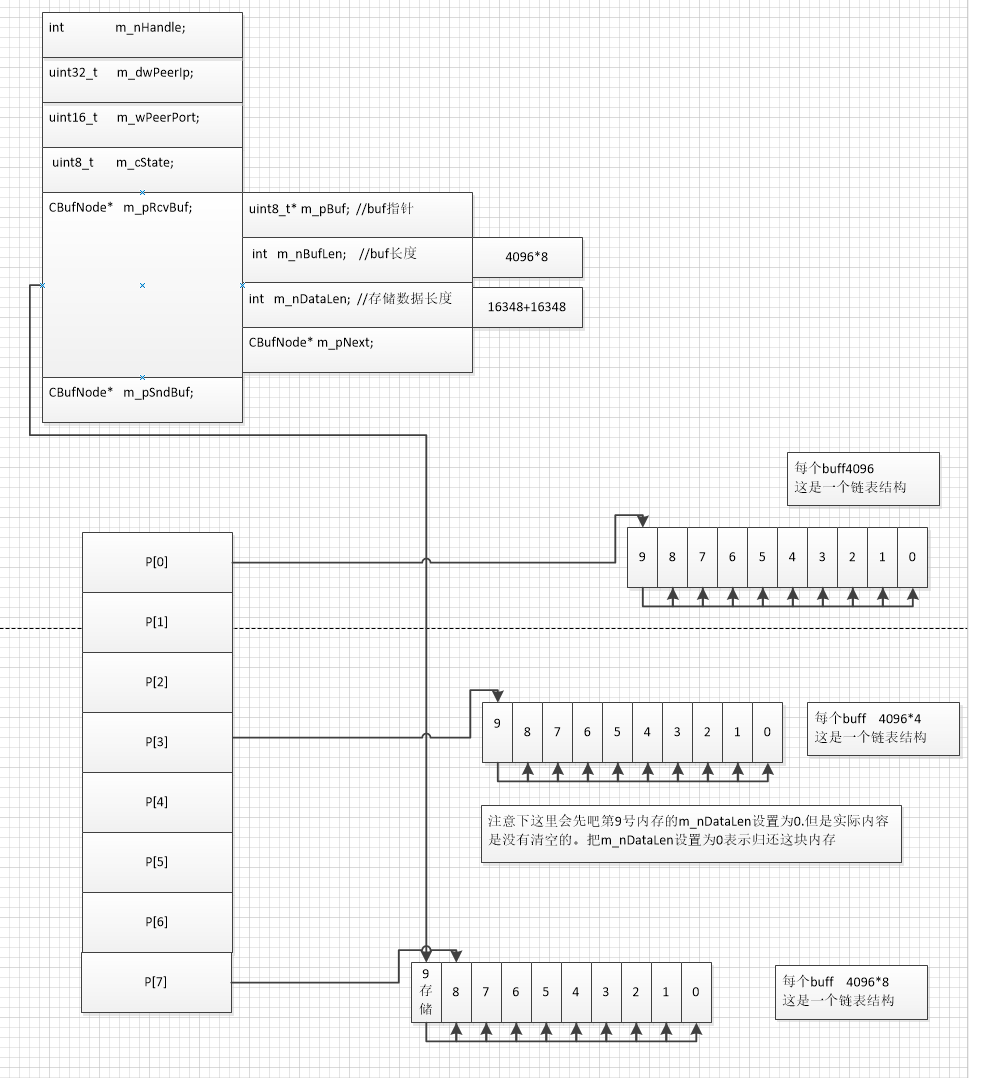
e)
后面都是类似的逻辑。 归还空间。然后申请新空间
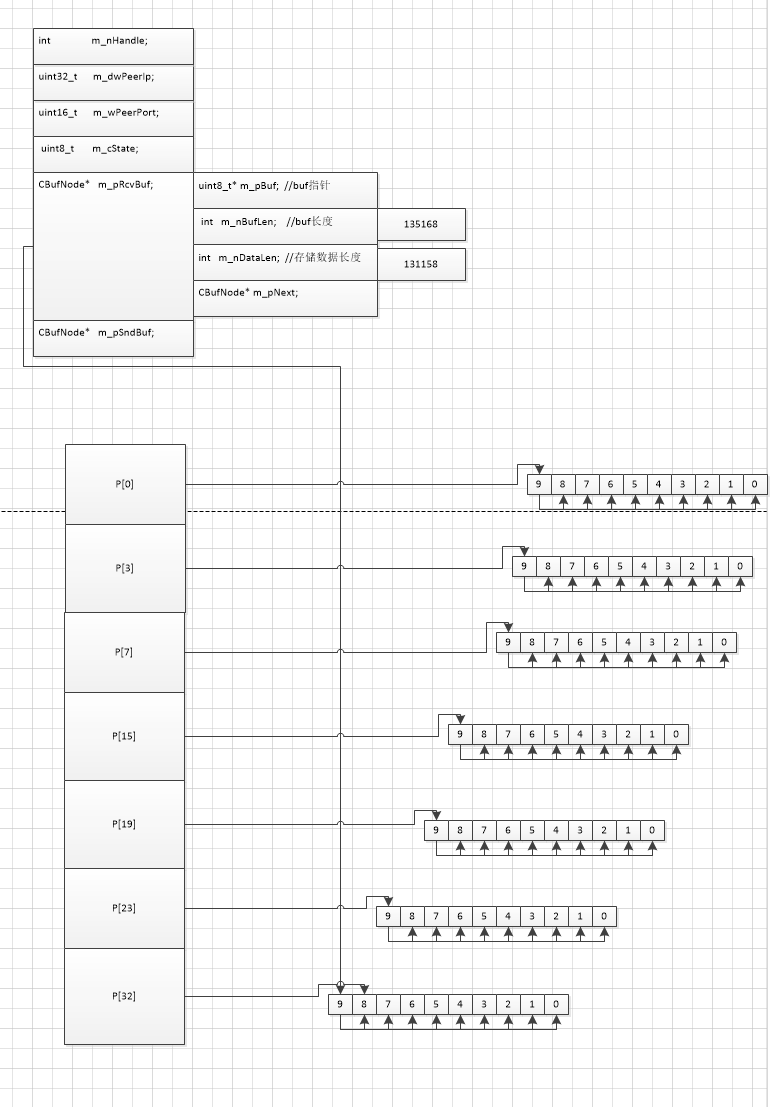
我看总共131158个字节的内容 recv 6次。
buffer管理器 替换了包括最开始初始化的的buffer总共花了7次 才找到合适的buffer来存放内容
p[32] 的buffer大小 为4*1024*33=135168
1.2.2 . 正常情况下的buffer总大小
在netio包了一段时间后。假如各种包的大小都存在。那么最后会怎么样~~。
这256个指针 都会被创建buffer。 没一列的buffer大小是 4*1024*行数。比如第一行就是4*1024*1.
最后一行就是4*1024*256.
而且被创建的buffer不会被释放。我们来计算下这个总的buffer会多大。
4*1024*(1+2+3...+256)=134742016 134742016 1048576
134742016 / (1024 * 1024) = 128 M
大概128兆。但是 这只是并发请求不高的情况下。我们来看下并发请求高的情况下会怎么样

1.2.3 . 高并发场景下 buffer的总大小
我们假设并发来了20个请求。为了使分析简单。我们就认为。每个请求数据都在4*1024以内。
如下图 用户p[0]的10个buffer以后。
p[0] 这个时候是指向了NULL的。
但是这个时候还有请求该怎么帮。
继续分配
这个时候再分配 10个buffer
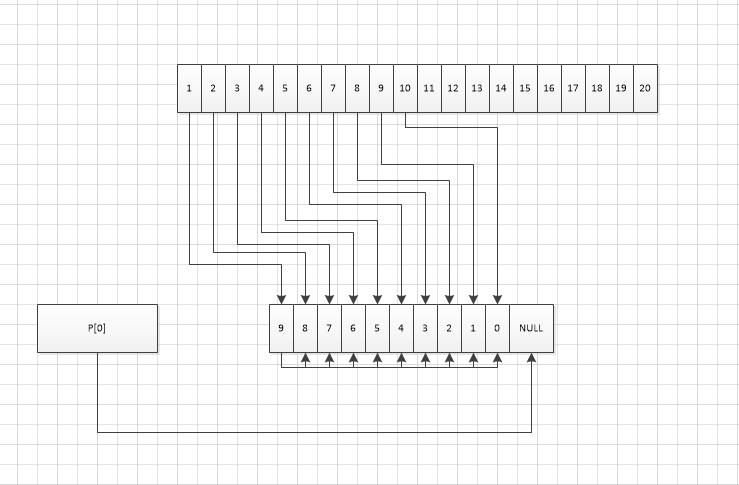
如下图 又重新分配了10个buffer。 跟在0的后面。 在来的请求就是在后面的10个buffer中分配。
代码中是 每次网络层向buffer管理器申请buffer的时候。
会去查看 二维指针是否为空。不为空则把空间给出来存数据。
如果为空。则会申请10个内存
所有看到这。当并发请求很大的时候。这个buffer会突增大到一个很恐怖的数字。
而且由于 创建后的空间不会被删除。会一直维持一个很高的内存占用

1.2.4 buffer的释放。
我们以下图为例子。
请求 7、4、8 先后是否空间。
那么p[0] 先是指向 index=3 然后指向index=6 最后指向index=2
那么p[0] 指向的其实是 没有被使用的空间的 链表头。
p[0] ->index2->index6->index3
下次又有新请求来的时候。 则把index2分配给新请求使用

总结下:
1)netio的buffer初看还是很麻烦的。看了2、3天才看明白。主要是实现的思想还是有点复杂。但是个人感觉看下来并没有什么特别惊艳的地方。实现上感觉有点像google的tcmall。
2)申请不释放的好处就是不会产生大量内存碎片。
3)但是高并发场景下回内存爆增。且不会下去。
4)还有针对一个大包。需要多次recv。那么buffer管理器会不停的替换buffer来存数据。而不是解析包头。确定包的大小。然后指定一个刚好符合的buffer。然后每次recv数据都放在这个buffer里。而不用不停的替换buffer.