Lucene 使用的是字符(词)类型的索引结构。对数值类型的索引和存储最终都要先转成字符类型。
早期版本Lucene 没有封装数值类型的公共类。需要先直接将数字转成字符串再加到Field 中。
JAVA代码:
1 Document doc = new Document(); 2 long i = 123456L;
3 doc.Add(new Field("id", String.valueOf(i), Field.Store.YES, Field.Index.YES)); 4 writer.AddDocument(doc);
如果按上面的方式直接转换,在进行范围查询的时候会有一个问题。
假设现在有123456,123,222 这三个数字,用上面的方式进行存储过。由于 lucene 索引用结构是基于字符的跳越链表。
最终在索引中的排序方式是 123 ,123456,222 。这样在早期用TermRangeQuery 进行范围查询的时候。
结果会把123 ,123456,222 都找出来。为了解决这个问题,一般都采用 固定位数,利用字符串排序特点,在不足位补0。
TermRangeQuery tQuery = new TermRangeQuery("id", "123", "222", true, true);//查找[123,222]
分别转换成:000000123,000123456,00000222 进行存储。这样的索引顺序变成000000123,000000222,000123456。
查询时也要做同样转换。
TermRangeQuery tQuery = new TermRangeQuery("id", "000000123", "000000222", true, true);
这个做会有两个性能问题:
1:如果把范围上下限拆分成多个term 如 000000123,000000124,000000125....000000222 。然后再分别去查询,把结果集合并。这种会造成查询次数过多。
2:从起始位置 000000123 遍历查找到000000222 结束,也会有遍历次数过多。
后期版本才提供对数值类型的支持,使用NumericField 来实例化一个Field(域)。并提供NumericRangeQuery 针对数值类型的区间查询的优化方案。
最新的版本(4.0 以上),提供了IntField,LongField FloatField, DoubleField 等,更加细化的数值类型。
索引代码:
1 Document doc = new Document(); 2 3 LongField idField = new LongField("id", h.getId(),Field.Store.YES); 4 5 doc.add(); 6 7 writer.addDocument(doc);
查询代码:
Query q = NumericRangeQuery.newLongRange("idField", 10L, 1000L, true, true);
对数值类型建索引的时候,会把数值转换成多个 lexicographic sortable string ,然后索引成 trie 字典树结构。
例如:假设num1 拆解成 a ,ab,abc ;num2 拆解成 a,ab,abd 。
【图1】:
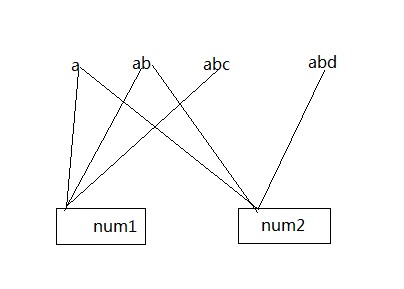
通过搜索ab 可以把带ab 前缀的num1,num2 都找出来。在范围查找的时候,查找范围内的数值的相同前缀可以达到一次查找返回多个doc 的目的,从而减少查找次数。
下面讲解一下 :数值类型的索引和范围查询的工作原理。
1:数值的二进制表示方式
以long 为例:符号位+63位整数位,符号位0表示正数 1表示负数。
对于正数来说低63位越大这个数越大,对于负数来说也是低63位越大。
如果对符号位取反。则long.min -- long.max 可表示为:0x0000,0000,0000,0000 -- 0xFFFF,FFFF,FFFF,FFFF
经过这样的转换后, 是不是从字符层面就已经是从小到大排序了?
2:如何拆分前缀
以0x0000,0000,0000,F234为例,每次右移4位。
1:0x0000,0000,0000,F23 与 0x0000,0000,0000,F230 --0x0000,0000,0000,F23F 范围内的所有数值的前缀一是一致的
2:0x0000,0000,0000,F2 与 0x0000,0000,0000,F200 ——0x0000,0000,0000,F2FF 范围内的所有数值的前缀一致
3:0x0000,0000,0000,F 与 0x0000,0000,0000,F000 --0x0000,0000,0000,FFFF 范围内的所有数值的前缀一致
....
0x0
如果用右移几位后的值做key,可以代表一个相应的范围。key可以理解成数值的前缀
3:对大范围折成小范围
Lucene 在查询时候的法做法是对大范围折成小范围,然后每个小范围分别用前缀进行查找,从而减少查找次数。
4:数值类型的索引的实现
先设定一个PrecisionStep (默认4),对数值类型每次右移(n-1)* PrecisionStep 位。
每次移位后,从左边开始每7位存入一个byte,组成一个byte[],
并且在数组第0位插入一个特殊byte,标识这次的偏移量。
每个byte[]可以转成一个lexicographic sortable string。
lexicographic sortable string 的字符按字典序排列后,和偏移量,数值的大小顺序是一致的。——这个是NumericRangeQuery 范围查找的关键!
long 类型一共64位,如果precisionStep=4,则会有16个lexicographic sortable string。
相当于16个前缀对应一个long数值,再用lucene 的倒序索引,最终索引成类似【图1】 的那种索引结构。
拆分的关键代码:
org.apache.lucene.util.NumericUtils 类的 longToPrefixCodedBytes() 方法
1 public static void longToPrefixCodedBytes(final long val, final int shift, final BytesRefBuilder bytes) {
2 if ((shift & ~0x3f) != 0) // ensure shift is 0..63 3 throw new IllegalArgumentException("Illegal shift value, must be 0..63");
//计算byte[]的大小,每位七位存入一个byte
4 int nChars = (((63-shift)*37)>>8) + 1; // i/7 is the same as (i*37)>>8 for i in 0..63 //最后还有第0位存偏移量,所以+1
5 bytes.setLength(nChars+1); // one extra for the byte that contains the shift info 6 bytes.grow(BUF_SIZE_LONG); //标识偏移量,shift
7 bytes.setByteAt(0, (byte)(SHIFT_START_LONG + shift)); //把符号位取反
8 long sortableBits = val ^ 0x8000000000000000L; //右移shift位,第一次shifi传0,之后按precisionStep递增
9 sortableBits >>>= shift; 10 while (nChars > 0) { 11 // Store 7 bits per byte for compatibility 12 // with UTF-8 encoding of terms //每7位存入一上byte ,前面第一位为0——在utf8中表示ascii码.并加到数组中。
13 bytes.setByteAt(nChars--, (byte)(sortableBits & 0x7f)); 14 sortableBits >>>= 7; 15 } 16 }
5:范围查询
大致思想是从范围的两端开始拆分。先把低位的值拆成一个区间,再移动PrecisionStep到下一个高位又并成一个区间。
最后把小区间里每个值,按移动的次数,用和索引的同样方式转成lexicographic sortable string.进行查找。
代码:
org.apache.lucene.util.NumericUtils 类的 splitRange() 方法
1 private static void splitRange( 2 final Object builder, final int valSize, 3 final int precisionStep, long minBound, long maxBound 4 ) { 5 if (precisionStep < 1) 6 throw new IllegalArgumentException("precisionStep must be >=1"); 7 if (minBound > maxBound) return; 8 for (int shift=0; ; shift += precisionStep) { 9 // calculate new bounds for inner precision 10 final long diff = 1L << (shift+precisionStep), 11 mask = ((1L<<precisionStep) - 1L) << shift; 12 final boolean 13 hasLower = (minBound & mask) != 0L, 14 hasUpper = (maxBound & mask) != mask; 15 final long 16 nextMinBound = (hasLower ? (minBound + diff) : minBound) & ~mask, 17 nextMaxBound = (hasUpper ? (maxBound - diff) : maxBound) & ~mask; 18 final boolean 19 lowerWrapped = nextMinBound < minBound, 20 upperWrapped = nextMaxBound > maxBound; 21 22 if (shift+precisionStep>=valSize || nextMinBound>nextMaxBound || lowerWrapped || upperWrapped) { 23 // We are in the lowest precision or the next precision is not available. 24 addRange(builder, valSize, minBound, maxBound, shift); 25 // exit the split recursion loop 26 break; 27 } 28 29 if (hasLower) 30 addRange(builder, valSize, minBound, minBound | mask, shift); 31 if (hasUpper) 32 addRange(builder, valSize, maxBound & ~mask, maxBound, shift); 33 34 // recurse to next precision 35 minBound = nextMinBound; 36 maxBound = nextMaxBound; 37 } 38 }
例如:1001,0001-1111,0010 分步拆分成
1: 1001,0001-1001,1111 ( 第0次偏移后 0x91-0x9F 有15个term )
和 1111,0000 -1111,0010 ( 第0次偏移后 0xF0-0F2 有3个term )
2: 1002,0000 – 1110,1111 右移一次后(0x11- 0x15 有5个term )
查找23个lexicographic sortable string.就可以覆盖整个区间。
官方说明:
http://lucene.apache.org/core/4_10_2/core/org/apache/lucene/search/NumericRangeQuery.html
On the other hand, if the precisionStep is smaller, the maximum number of terms to match reduces, which optimizes query speed. The formula to calculate the maximum number of terms that will be visited while executing the query is:
![mathrm{maxQueryTerms} = left[ left( mathrm{indexedTermsPerValue} - 1
ight) cdot left(2^mathrm{precisionStep} - 1
ight) cdot 2
ight] + left( 2^mathrm{precisionStep} - 1
ight)](http://lucene.apache.org/core/4_10_2/core/org/apache/lucene/search/doc-files/nrq-formula-2.png)
For longs stored using a precision step of 4, maxQueryTerms = 15*15*2 + 15 = 465, and for a precision step of 2, maxQueryTerms = 31*3*2 + 3 = 189. But the faster search speed is reduced by more seeking in the term enum of the index. Because of this, the ideal precisionStep value can only be found out by testing. Important: You can index with a lower precision step value and test search speed using a multiple of the original step value.
http://lucene.apache.org/core/4_10_2/core/index.html
To sort according to a LongField, use the normal numeric sort types, eg SortField.Type.LONG.
If you only need to sort by numeric value, and never run range querying/filtering, you can index using a precisionStep of Integer.MAX_VALUE.
如果这个数值只是用来当作sort 字段,不需要范围查询。 排序时指定排序Type SortField.Type.LONG.
可以将precisionStep=Integer.MAX_VALUE。这样就只会产生0偏移的lexicographic sortable string减少索引体积。