目录:
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。
但你也可以自己创建函数,这被叫做用户自定义函数。
定义函数规则:
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
函数定义示例:
def 函数名(参数1,参数2):
'''
这是一个解决什么问题的函数
:param 参数1: 参数1代表输入什么
:param 参数2: 参数2代表输入什么
:return: 返回什么东西
'''
函数体
返回值
return 返回值
例如定义计算字符串长度的函数:
def my_len(my_str): #定义函数
'''
用于计算可变类型长度的函数
:param my_str: 用户输入的参数内容
:return:返回参数的长度
'''
count = 0
for val in my_str:
count += 1
return count
a = my_len("hightgood")
print(a) #输出值9
定义一个函数后,尽量不要用print,尽量return结果
自己是可以知道函数代码内部打印的是啥,自己可以随时修改,但是别人不知道
函数中的return:
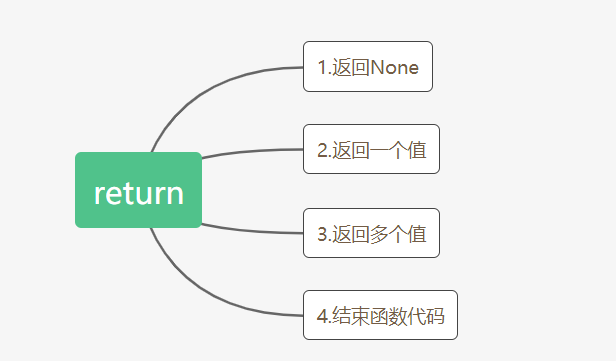
1.返回None
有三种情况:
(1)无return的情况
(2)本来就return None
(3)return #return空白
#无return
def my_print(parameter):
print("Welcome",parameter)
#return None
def my_print(parameter):
return None
#return
def my_print(parameter):
return #一般用于结束函数体
2.返回一个值
def my_len(my_str): #定义函数
#计算可变类型值的长度
my_str = "goodnight"
count = 0
for val in my_str:
count += 1
return count #count就是那个返回值
3.返回多个值
def my_print():
return 11,22,33,[1,2,3]
a = my_print()
print(a)
#打印结果:(11, 22, 33, [1, 2, 3])
return后面的值用逗号隔开,然后以元组的形式返回
4.结束函数代码
def my_print():
print('one')
return #遇到return不继续函数下面的代码
print('two')
my_print() #结果:one
5.补充:接收多个值
def my_print():
return 1,2,3
a,b,c=my_print()
print(a,b,c) #相当于用a接收1,b接收2,c接收3
def my_print():
return [4,5,6]
a,b,c=my_print()
print(a,b,c) #一个列表里有三个值,分别用abc去接收,相当于解包 a=4,b=5,c=6
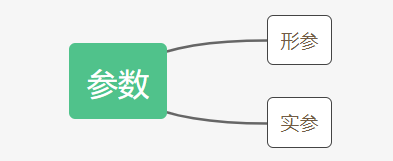
def my_len(my_str): #这里的my_str就是形参,形式参数,输入对象不确定,形参可以有多个,用逗号隔开
my_str = "goodnight"
count = 0
for val in my_str:
count += 1
return count
a = my_len("hightgood") #这里的hightgood就是实参,实际参数,输入对象确定
print(a)
函数参数详解:

1.位置参数:
def demo_1(a,b): #位置参数 用户必须传入的参数,不传会报错
print(a,b)
demo_1(1,2) #输出结果:1 2 按照位置传参
demo_1(b=1,a=2) #输出结果:2 1 按照关键字传参
demo_1(1,b=2) #输出结果:1 2 混用,但必须注意先按照位置传参,再按照关键字传参,不然会报错
2.默认参数:
def welcome(name,sex='man'): #sex为默认参数
print('welcome %s,sex %s'%(name,sex))
welcome('zrh') #输出结果:welcome zrh,sex man
welcome('lml','women') #输出结果:welcome lml,sex women
#默认参数如果不传参数,就用默认值,如果默认参数传入参数,就用传入值
默认参数的陷阱:
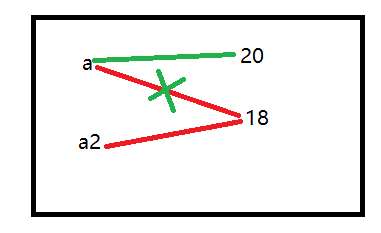
(1)
a = 18
def age(a1,a2=a):
print(a1,a2)
a = 20
age(10) #输出结果:10 18
内部原理:
(2)专门针对可变数据类型
def demo(a = []):
a.append(1)
print(a)
demo() #输出结果:[1]
demo() #输出结果:[1] [1]
demo() #输出结果:[1] [1] [1]
def demo_1(a = []):
a.append(1)
print(a)
demo_1([]) #输出结果:[1]
demo_1([]) #输出结果:[1]
demo_1([]) #输出结果:[1]
因为可变类型改变不是在内存中开辟一个新空间,而是在原来的基础上做修改,而10--12行是开辟了三块新内存
3.动态参数:
定义动态参数
def demo(*agrs): #按位置输入的动态参数,组成一个元组
pass
def demo_1(**kwargs): #按关键字传入的参数,组成一个字典
pass
站在函数定义的角度:*做聚合作用,将一个一个的参数组合成一个元组(**则是字典)
站在函数调用的角度:*做打散用,将一个列表或元组打散成多个参数(**则是关键字形式)
#函数定义角度:
def demo(*agrs): #按位置输入的动态参数
print(agrs)
demo(1,2,3,4,5) #输出结果(1, 2, 3, 4, 5)
def demo_1(**kwargs): #按关键字传入的参数,组成一个字典
print(kwargs)
demo_1(a=1,b=2,c=3) #输出结果{'a': 1, 'b': 2, 'c': 3}
#函数调用角度:
val = [1,2,3,4]
val2 = {'a':1,'b':2}
demo(*val) #将val打散成 1 2 3 4,然后传入函数
demo_1(**val2) #将val2打散成 a=1 b=2,然后传入函数
解释一下为什么在混用的传参中有必须先按位置传参,再按关键数传参:
def demo(*agrs,**kwargs): #*agrs和**kwargs的位置是python固定死的
#所以必须先是按照位置传参的*agrs,再是按照关键字传参的**keagrs
print(agrs)
print(kwargs)
demo(1,2,3,4,a = 1,b = 2)
# 输出结果:
# (1, 2, 3, 4)
# {'a': 1, 'b': 2}
第3行对应第7行的输出结果
第4行对应第8行的输出结果
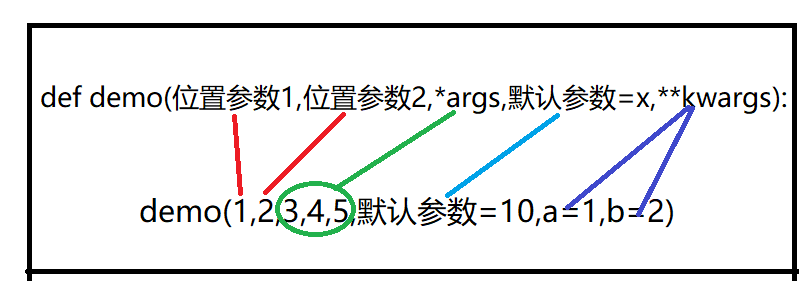
定义多个不同类型参数时的顺序:
def demo(位置参数1,位置参数2,*args,默认参数=x,**kwargs):
pass
#以后职业生涯用到多种参数时必须这么写
格式及原理:
情况总结:
def demo(*args,**kwargs): #接收参数个数不确定的时候用动态传参,用到的时候再用
pass
def demo_1(a,b,c): #位置参数,几个参数必须都要传入几个值,最常用
pass
def demo_2(a,b=10): #默认参数,当参数信息大量形同时用到
pass
函数案例:
需求:写函数,用户输入操作文件名字,将要修改的内容,修改后的内容,然后进行批量操作

def dict_change(filename,old_content,new_content):
'''
函数用于文件内容批量修改操作
:param filename: 操作对象的名字
:param old_content: 将要修改的值
:param new_content: 修改后的值
:return:无返回值
'''
import os
with open(filename,encoding='utf-8') as file_old,open('new_file','w',encoding='utf-8') as file_new :
for val_old in file_old:
val_new = val_old.replace(old_content,new_content)
file_new.write(val_new)
os.remove(filename)
os.rename('new_file',filename)
dict_change('file','.','=')
修改后的文件:

函数的嵌套:
#函数的嵌套调用
def demo_1():
print(123)
def demo_2():
demo_1()
print(456)
demo_2()
# 输出结果:
# 123
# 456
#函数嵌套定义
def demo_1():
print(123)
def demo_2():
print(456)
demo_2()
demo_1()
# 输出结果:
# 123
# 456
注意:内存读函数的时候先读定义函数名(不读里面的函数体),后面遇到调用此函数的时候,再返回读函数的函数体。
在函数外调整内部嵌套函数内容的方法:
def case(x,y,z):
def new_case(a,b,c):
print('content',a,b,c)
new_case(x,y,z)
case(1,2,3)
#输出结果 content 1 2 3
进阶:
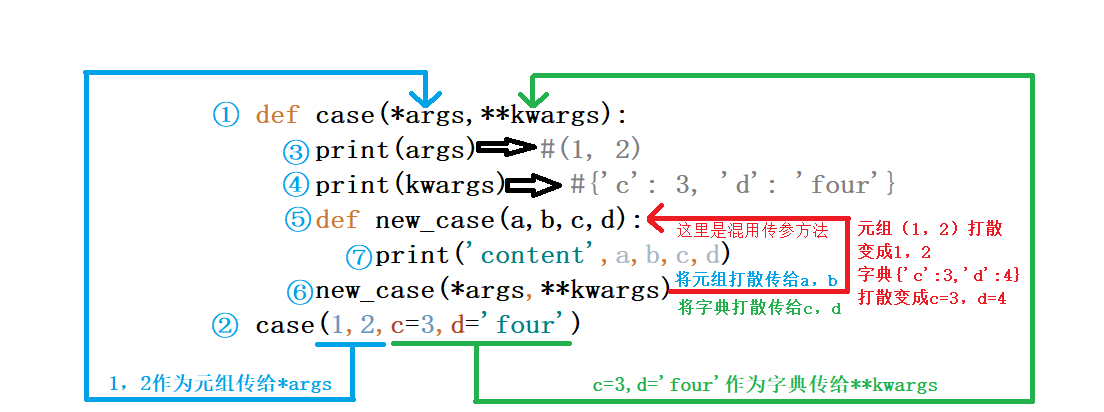
①到⑦表示代码运行顺序
*args 和 **kwargs 只是函数定义参数的方式,和混合传参不是一回事哦
在函数外部定义的变量为全局变量,函数内部定义的变量为局部变量
在函数内定义的局部变量只在该函数内可见,当函数运行结束后,在其内部定义的所有局部变量将自动删除而不访问
1.
a = 1
b = 2
def num_max(a,b):
c = b if a<b else a
print(c)
def num_min(a,b):
c = a if a<b else b
print(c)
num_max(10,8)
num_min(5,6)

局部命名空间之间信息不互通,不共享
2.
a = 1
b = 2
def num_max():
c = b if a<b else a
print(c)
num_max() #输出结果:2
函数局部命名空间(儿子)可以用全局命名空间(爸爸)的内容,但是全局命名空间(爸爸)不可以使用函数局部命名空间(儿子)的内容
就是 儿子可以用爸爸的,爸爸不能用儿子的
3.
a = 1
b = 2
def num_max():
def num():
a = 3
print(a)
num()
num_max() #输出结果:3
对于局部命名空间来说,自己有的话就用自己的,自己没有再用全局命名空间的
4.
a = 1
b = 2
def num_max():
c = 3
def num():
d = 4
print(a)
num()
num_max() #输出结果:1

儿子没有的先用爸爸的,爸爸也没有的话,再用爷爷的
爷爷不能用爸爸,更不能用儿子
爸爸也不能用儿子的
命名空间的加载顺序:
1.启动python
2.内置的命名空间(在哪里都可以用,比如print()等)
3.加载全局命名空间中的名字 —— 从上到下顺序加载
4.加载局部命名空间中的名字 —— 调用该函数的时候,在函数里从上到下去加载
内置的命名空间,在任意地方都可以用
全局的命名空间,在我们写的代码里任意地方(相当于爷爷,爸爸儿子都可以用爷爷的)
局部的命名空间,只能在自己的函数内使用
global:在函数内部修改全局变量的值
a = 1
def demo_1():
a =2
print(a)
def demo_2():
a = 3
print(a)
demo_2()
demo_1()
print(a)
打印结果:

需求,在函数里修改全局变量a = 10,这个时候就用的global:
a = 1
def demo_1():
global a
a =10
print(a)
def demo_2():
a = 3
print(a)
demo_2()
demo_1()
print(a)
打印结果:

nonlocal:在函数内部修改函数上一级的变量值,儿子修改爸爸的值,但不影响爷爷的值,只改一层
nonlocal 只修改局部命名空间里的 从内部往外部找到第一个对应的变量名
需求:修改demo_1()里a的值为10
a = 1 def demo_1(): a = 2 def demo_2(): nonlocal a a = 10 print(a) demo_2() print(a) demo_1() print(a)
输出结果:

def func():
pass
func就是函数名,加个括号func()才是调用函数
函数的名字首先是一个函数的内存地址,可以当作变量使用 ,函数名是第一类对象的概念
函数的名字可以赋值,可以作为其他列表等容器类型的元素
函数的名字可以作为函数的参数,返回值
def func():
print(123)
print(func)
#输出结果:<function func at 0x0000023DB22EF1F8>
# 是个函数 名为func 内存地址
就表示func是一个存着一个函数地址的变量而已
所以下面这些都可以使用:
def func():
print(123)
a = func
print(func)
print(a)
#输出结果:一模一样
# <function func at 0x000002435074F1F8>
# <function func at 0x000002435074F1F8>
def func():
print(123)
a = func
a() #输出结果:123
def func():
print(123)
list_1 = [func]
print(list_1) #输出结果 [<function func at 0x000001BC83DCF1F8>]
#这个时候 list_1[0] == func
list_1[0]() #输出结果:123 list_1[0]()也可以调用函数func()
def func():
print(123)
def exal(q):
q() #相当于func(),用到了前面说的嵌套函数的调用
print(q,type(q))
exal(func)
print(type(func))
#输出结果:
# 123
# <function func at 0x0000027B24E5F288> <class 'function'>
#<class 'function'>
高阶函数:
高阶函数定义:
1.函数接收的参数是一个函数名
2.函数的返回值是一个函数名
满足上述条件任意一个,都可称之为高阶函数
def foo():
print('from foo')
def test(func_name):
return func_name
print(test(foo)) #<function foo at 0x0000018F2211F288> 拿到的是foo函数名的内存地址
此时test()就是一个高阶函数
内部函数(下面的demo_2)引用了外部函数(dem_1)的 变量,内部的函数就叫做闭包
def demo_1(): name = 'zrh' age = '20' def demo_2(): print(name,age) print(demo_2.__closure__) #(<cell at 0x0000018B6DE9A108: str object at 0x0000018B6DE6DDF0>, #<cell at 0x0000018B6DE9A1F8: str object at 0x0000018B6DE6DDB0>) #打印出来有东西说明用到了外部函数的变量,就形成了闭包 demo_1()
闭包的作用:
在变量不容易被别人改变的情况下,还不会随着你多次去调用而反复去创建变量
def demo_1():
name = 'zrh'
print(name)
demo_1()
demo_1()
demo_1()
demo_1()
demo_1()
demo_1()
#......
如果我执行demo_1函数一万次。那么内存就会开辟一万次空间储存 name = ‘zrh’,然后再耗费时间关闭那一万次的空间
def demo_1():
name = 'zrh'
def demo_2():
print(name)
return demo_2
i = demo_1()
i()
i()
i()
i()
如果用闭包的方式,即使调用函数一万次,内存也会在第6行代码执行时创建一次空间来储存name = ‘zrh’,大大节省空间利用效率
闭包的应用:
from urllib.request import urlopen #模块
def get_url():
url = 'http://www.cnblogs.com/'
def inner():
ret = urlopen(url).read()
return ret
return inner
get_web = get_url()
res = get_web()
print(res)
同样url = 'http://www.cnblogs.com/'只创建了一次,后面调用千百万次,内存空间只有一次

定义:装饰器为其他函数添加附加功能,本质上还是一个函数
原则:
①不修改被修饰函数的源代码
②不修改被修饰函数的调用方式
有这样一个函数:demo()
先导入时间模块,然后函数执行时先睡两秒,在执行打印
import time
def demo():
time.sleep(2)
print("welcome sir")
demo()
现在想为demo()函数添加一个统计函数运行时间的功能,但是要遵循开放封闭原则
初步思想:
import time
def demo():
start_time = time.time()
time.sleep(2)
print("welcome sir")
end_time = time.time()
print("运行时间%s" %(end_time-start_time))
demo()
这样就完美解决了,但是,我们要用可持续发展的眼光来看,假如有十万个代码,我们这样一个一个添加,你不加班谁加班?
这个时候我们可以用函数的思维来解决
进步思想:
import time
def demo():
time.sleep(2)
print("welcome sir")
def timmer(func_name):
def inner():
start_time = time.time()
func_name()
end_time = time.time()
print("运行时间%s" %(end_time-start_time))
return inner
res = timmer(demo)
res()
这样看起来非常Nice,用到了高阶函数,嵌套函数,函数闭包,但是我们违反了开放封闭原则,这个时候把res 改成 demo 就可以了
在这里有一个命令,可以直接略过这个赋值,让代码看起来更美观,执行效率更高
import time
def timmer(func_name):
def inner():
start_time = time.time()
func_name()
end_time = time.time()
print("运行时间%s" %(end_time-start_time))
return inner
@timmer
def demo():
time.sleep(2)
print("welcome sir")
demo()
ok,代码完成,这其实就是一个函数装饰器,我们来解释一下代码运行顺序

为装饰器加上返回值:
import time
def timmer(func_name):
def inner():
start_time = time.time()
res = func_name()
end_time = time.time()
print("运行时间%s" %(end_time-start_time))
return res
return inner
@timmer
def demo():
time.sleep(2)
return '函数demo的返回值'
val = demo()
print(val)
有参数的装饰器:
import time
def timmer(func_name):
def inner(*args,**kwargs):
start_time = time.time()
res = func_name(*args,**kwargs)
end_time = time.time()
print("运行时间%s" %(end_time-start_time))
return res
return inner
@timmer
def demo(name,age):
time.sleep(2)
return '函数demo的返回值,姓名:%s,年龄:%s' %(name,age)
val = demo('zrh',20)
print(val)
图示流程:

可迭代协议:只要包括了"_iter_"方法的数据类型就是可迭代的
print([1,2,3].__iter__()) #打印结果:<list_iterator object at 0x000002E7F803DE88>
iterable 形容词 可迭代的
from collections import Iterable #检测一个对象是否可迭代
print(isinstance('aaa',Iterable))
print(isinstance(123,Iterable))
print(isinstance([1,2,3],Iterable))
迭代器协议:迭代器中有 __next__ 和 __iter__方法
iterator 名词 迭代器,迭代器 就是实现了能从其中一个一个的取出值来
检测参数是不是个迭代器:
from collections import Iterator
print(isinstance(lst_iterator,Iterator))
print(isinstance([1,2,3],Iterator))
在python里,目前学过的所有的可以被for循环的基本数据类型都是可迭代的,而不是迭代器。
迭代器包含可迭代对象
可迭代对象转换为迭代器:
可迭代对象._iter_() 这样就变成可一个迭代器
lise_case = [1,2,3].__iter__()
迭代器存在的意义:
1.能够对python中的基本数据类型进行统一的遍历,不需要关心每一个值分别是什么
2.它可以节省内存 —— 惰性运算
for循环的本质:
lst_iterator = [1,2,3].__iter__()
while True:
try:
print(lst_iterator.__next__())
except StopIteration:
break
只不过for循环之后如果参数是一个可迭代对象,python内部会将可迭代对象转换成迭代器而已。
Iterator 迭代器
Gerator 生成器
生成器其实就是迭代器,生成器是用户写出来的
def generator_func(): #生成器函数
print(123)
yield 'aaa'
generate = generator_func()
print(generate)
print(generate.__next__())
# 打印结果:
# <generator object generator_func at 0x0000018F3942E8C8>
# 123
# aaa
带yield关键字的函数就是生成器函数,包含yield语句的函数可以用来创建生成器对象,这样的函数也称为生成器函数。
yield语句与return语句的作用相似,都是用来从函数中返回值,return语句一旦执行会立刻结束函数的运行
而每次执行到yield语句并返回一个值之后会暂停或挂起后面的代码的执行,下次通过生成器对象的__next__()、for循环或其他方式索要数据时恢复执行
生成器具有惰性求值的特点
生成器运行顺序:

生成器问题注意1:
1 def generator_func(): #生成器函数 2 print(123) 3 yield 'aaa' 4 print(456) 5 yield 'bbb' 6 ret_1 = generator_func().__next__() 7 print(ret_1) 8 ret_2 = generator_func().__next__() 9 print(ret_2) 10 # 输出结果: 11 # 123 12 # aaa 13 # 123 14 # aaa 15 def generator_func(): #生成器函数 16 print(123) 17 yield 'aaa' 18 print(456) 19 yield 'bbb' 20 generate_1 = generator_func() 21 ret_1 = generate_1.__next__() 22 print(ret_1) 23 ret_2 = generate_1.__next__() 24 print(ret_2) 25 # 输出结果: 26 # 123 27 # aaa 28 # 456 29 # bbb
第6行和第8行相当于创建了两个生成器,第20行创建了一个生成器,21行和23行都用的是第20行创建的生成器,所以输出结果不一样
生成器问题注意2:

for循环完了之后生成器数据就取完了,再继续print数据的话,就会报错,因为没有数据可以读了。
一个函数有两个以上的yield,才算一个必要的生成器,如果只有一个yield,那还不如老老实实的去写return
生成器实例:
需求:写一个实时监控文件输入的内容,并将输入内容返回的函数
def tail(filename):
f = open(filename,encoding='utf-8')
f.seek(0,2)
while True:
line = f.readline()
if not line:continue
yield line
tail_g = tail('file_1')
for line in tail_g:print(line,end='')
生成器send用法:
1.send和next工作的起止位置是完全相同的
2.send可以把一个值作为信号量传递到函数中去
3.在生成器执行伊始,只能先用next
4.只要用send传递参数的时候,必须在生成器中还有一个未被返回的yield
def average_func():
total = 0
count = 0
average = 0
while True:
value = yield average
total += value
count += 1
average = total/count
g = average_func()
print(g.__next__())
print(g.send(30))
print(g.send(20))
代码解释:

装饰器生成激活函数装置:
def wrapper(func):
def inner(*args,**kwargs):
g = func(*args,**kwargs)
g.__next__()
return g
return inner
@wrapper
def average_func():
total = 0
count = 0
average = 0
while True:
value = yield average
total += value
count += 1
average = total/count
g = average_func()
print(g.send(30))
利用函数装饰器写了一个函数激活装置,就不用在18行之前的send前使用 next 了,next 在第4行已经实现了。
以( )框住里面的内容,就是把列表表达式的[ ]改成( ),就是生成器表达式
case = ('第%d个人' %i for i in range(3))
从生成器中取值的三种方法:

生成器表达式作用:节省内存,简化代码,相比较列表表达式多了一个节省内存的作用,那是因为生成器具有惰性求值的特性
生成一个人生成器归生成,我内存不会加载他,只有当你用的时候我才去加载他。
用户要一个数据,生成器就给一个数据,列表表达式就是一下子生成3个,生成器表达式就是你要一个我生成一个。
集合生成器:
以{ }框住里面的内容,自带去重功能
lis_case = [-1,1,2,3]
print({i*i for i in lis_case}) #输出结果{1, 4, 9}
在以后工作中,列表推导式最常用,但是尽量把列表推导式变成生成器推导式,因为这样节省内存,节省内存的思想应该处处体现在代码里,这样才能体现水平。
生成器表达式面试题:
有如下代码:问输出的结果是什么?
def demo():
for i in range(4):
yield i
g=demo()
g1=(i for i in g)
g2=(i for i in g1)
print(list(g1))
print(list(g2))
答案:
[0, 1, 2, 3]
[]
考点:
内存加载第5行和第6行的时候是不会加载里面的内容的,然后第7行调用g1的时候内存才会去加载g1的内容
g1本质上是一个生成器推导式,只能用一次,所以第7行print一次之后,g1就是空列表了
生成器练习题:问输出结果是啥?
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g=test()
for n in [1,10,5]:
g=(add(n,i) for i in g)
print(list(g))
上面的代码可以这样理解:
# def add(n,i):
# return n+i
# def test():
# for i in range(4):
# yield i
# g=test()
# n = 1:
# g=(add(n,i) for i in g)
# n = 10:
# g=(add(n,i) for i in (add(n,i) for i in g))
# n = 5:
# g=(add(n,i) for i in (add(n,i) for i in (add(n,i) for i in g)))
# print(list(g))
代码解释:
7~12行代码还是会运行,但只是计算 g=什么 ,并不会计算=后面的具体内容,只有后面真正调用g的时候,即(list(g)),这个时候才会回去执行g=后面的内容。
先看一个需求:
写函数,将“从前有座山,山里有个庙,庙里有个老和尚讲故事,讲的什么呀?”打印10遍
一般写法
def func_case():
for i in range(10):print('从前有座山,山里有个庙,庙里有个老和尚讲故事,讲的什么呀?')
func_case()
解耦思想写法
def func_case():
print('从前有座山,山里有个庙,庙里有个老和尚讲故事,讲的什么呀?')
for i in range(10):
func_case()
这样写的好处就可以在不动第一个函数的情况下,修改打印的次数,一般写法中如果要修改打印次数是直接修改的是函数内部的内容,这样会影响代码质量。
解耦的定义
要完成一个完整的功能,但这个功能的规模要尽量小,并且和这个功能无关的其他代码应该和这个函数分离
解耦的作用
1.增强代码的重用性
2.减少代码变更的相互影响
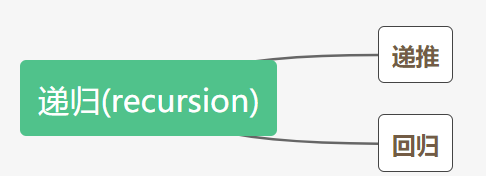
递归:一个函数在内部调用自己就叫做递归,递归在函数内部分为递推、回归两个流程,python解释器规定递归层数是有限制的(一般为997层),写递归函数时必须要有一个结束条件。
例如需求:1的年龄比2大两岁,2的年龄比3大两岁,3的年龄比4大两岁,4的年龄是40岁,用函数方式计算1的年龄。
这个需求就是典型的递归问题,下面是代码示例:
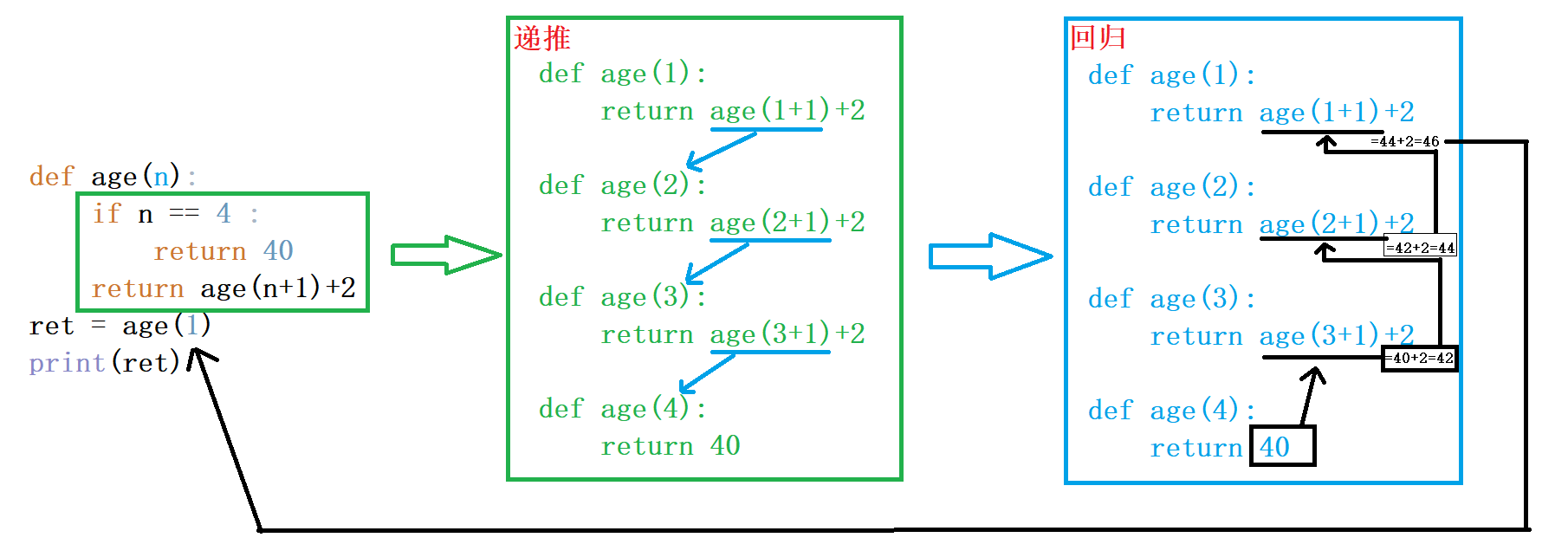
def age(n):
if n == 4 :
return 40
return age(n+1)+2
ret = age(1)
print(ret)
代码解释:
递归实例:
用户输入数字n,求n的阶乘:
n = int(input(">>>:"))
def func(n):
if n == 1:return 1
return n*func(n-1)
print(func(n))
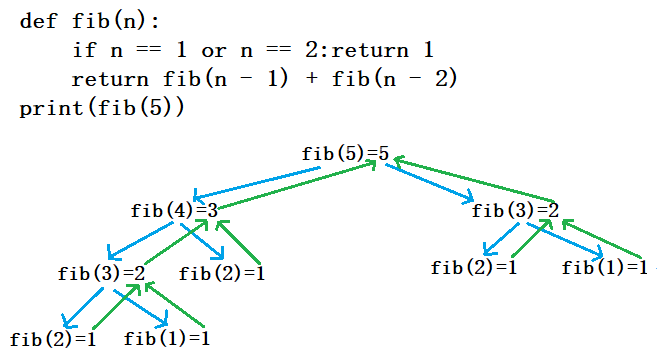
斐波那契:
n表示打印第n个斐波那契数
n = int(input(">>>:"))
def fib(n):
if n == 1 or n == 2:return 1
return fib(n-1)+fib(n-2)
print(fib(5))
二分法查找索引位置:(需要背过)
def search(num,l,start=None,end=None):
start = start if start else 0
end = end if end else len(l) - 1
mid = (end - start)//2 + start
if start > end:
return None
elif l[mid] > num : #17,17
return search(num,l,start,mid-1)
elif l[mid] < num:
return search(num,l,mid+1,end)
elif l[mid] == num:
return mid
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
print(search(66,l))
三级菜单:


menu = {
'北京': {
'海淀': {
'五道口': {
'soho': {},
'网易': {},
'google': {}
},
'中关村': {
'爱奇艺': {},
'汽车之家': {},
'youku': {},
},
'上地': {
'百度': {},
},
},
'昌平': {
'沙河': {
'老男孩': {},
'北航': {},
},
'天通苑': {},
'回龙观': {},
},
'朝阳': {},
'东城': {},
},
'上海': {
'闵行': {
"人民广场": {
'炸鸡店': {}
}
},
'闸北': {
'火车战': {
'携程': {}
}
},
'浦东': {},
},
'山东': {},
}
def Three_Level_Menu(menu):
while True:
for k in menu:print(k)
key = input('>>>(输入q退出,输入b返回上一层):')
if key == 'q':return 'q'
elif key == 'b':break
elif key in menu:
ret = Three_Level_Menu(menu[key])
if ret == 'q': return 'q'
Three_Level_Menu(menu)